
arXiv:1506.02186v2 [math.OC] 25 Oct 2015
A Universal Catalyst for First-Order Optimization
Hongzhou Lin
1
, Julien Mairal
1
and Zaid Harchaoui
1,2
1
Inria
2
NYU
{hongzhou.lin,julien.mairal}@inria.fr
zaid.harchao[email protected]
Abstract
We introduce a generic scheme for accelerating first-order optimization methods
in the sense of Nesterov, which builds upon a new analysis of the accelerated prox-
imal point algorithm. Our approach consists of minimizing a convex objective
by approximately solving a sequence of well-chosen auxiliary problems, leading
to faster convergence. This strategy applies to a large class of algorithms, in-
cluding gradient descent, block coordinate descent, SAG, SAGA, SDCA, SVRG,
Finito/MISO, and their proximal variants. For all of these methods, we provide
acceleration and explicit support for non-strongly convex objectives. In addition
to theoretical speed-up, we also show that acceleration is useful in practice, espe-
cially for ill-conditioned problems where we measure significant improvements.
1 Introduction
A large number of machine learning and signal processing problems are formulated as the mini-
mization of a composite objective function F : R
p
→ R:
min
x∈R
p
n
F (x) , f(x) + ψ(x)
o
, (1)
where f is convex and has Lipschitz continuous derivatives with constant L and ψ is convex but may
not be differentiable. The variable x represents model parameters and the role of f is to ensure that
the estimated parameters fit some observed data. Specifically, f is often a large sum of functions
f(x) ,
1
n
n
X
i=1
f
i
(x), (2)
and each term f
i
(x) measures the fit between x and a data point indexed by i. The function ψ in (1)
acts as a regularizer; it is typically chosen to be the squared ℓ
2
-norm, which is smooth, or to be a
non-differentiable penalty such as the ℓ
1
-norm or another sparsity-inducing norm [2]. Composite
minimization also encompasses constrained minimization if we consider extended-valued indicator
functions ψ that may take the value +∞ outside of a convex set C and 0 inside (see [11]).
Our goal is to accelerate gradient-based or first-order methods that are designed to solve (1), with
a particular focus on large sums of functions (2). By “accelerating”, we mean generalizing a mech-
anism invented by Nesterov [17] that improves the convergence rate of the gradient descent algo-
rithm. More precisely, when ψ = 0, gradient descent steps produce iterates (x
k
)
k≥0
such that
F (x
k
) −F
∗
= O(1/k), where F
∗
denotes the minimum value of F . Furthermore, when the objec-
tive F is strongly convexwith constant µ, the rate of convergence becomes linear in O((1−µ/L)
k
).
These rates were shown by Nesterov [16] to be suboptimal for the class of first-order methods, and
instead optimal rates—O(1/k
2
) for the convex case and O((1 −
p
µ/L)
k
) for the µ-strongly con-
vex one—could be obtained by taking gradient steps at well-chosen points. Later, this acceleration
technique was extended to deal with non-differentiable regularization functions ψ [4, 19].
For modern machine learning problems involving a large sum of n functions, a recent effort has been
devoted to developing fast incremental algorithms [6, 7, 14, 24, 25, 27] that can exploit the particular
1

structure of (2). Unlike full gradient approaches which require computing and averaging n gradients
∇f(x) = (1/n)
P
n
i=1
∇f
i
(x) at every iteration, incremental techniques have a cost per-iteration
that is independent of n. The price to pay is the need to store a moderate amount of information
regarding past iterates, but the benefit is significant in terms of computational complexity.
Main contributions. Our main achievement is a generic acceleration scheme that applies to a
large class of optimization methods. By analogy with substances that increase chemical reaction
rates, we call our approach a “catalyst”. A method may be accelerated if it has linear conver-
gence rate for strongly convex problems. This is the case for full gradient [4, 19] and block coordi-
nate descent methods [18, 21], which already have well-known accelerated variants. More impor-
tantly, it also applies to incremental algorithms such as SAG [24], SAGA [6], Finito/MISO [7, 14],
SDCA [25], and SVRG [27]. Whether or not these methods could be accelerated was an important
open question. It was only known to be the case for dual coordinate ascent approaches such as
SDCA [26] or SDPC [28] for strongly convex objectives. Our work provides a universal positive an-
swer regardless of the strong convexity of the objective, which brings us to our second achievement.
Some approaches such as Finito/MISO, SDCA, or SVRG are only defined for strongly convex ob-
jectives. A classical trick to apply them to general convex functions is to add a small regularization
εkxk
2
[25]. The drawback of this strategy is that it requires choosing in advance the parameter ε,
which is related to the target accuracy. A consequence of our work is to automatically provide a
direct support for non-strongly convex objectives, thus removing the need of selecting ε beforehand.
Other contribution: Proximal MISO. The approach Finito/MISO, which was proposed in [7]
and [14], is an incremental technique for solving smooth unconstrained µ-strongly convex problems
when n is larger than a constant βL/µ (with β = 2 in [14]). In addition to providing acceleration
and support for non-strongly convex objectives, we also make the following specific contributions:
• we extend the method and its convergence proof to deal with the composite problem (1);
• we fix the method to remove the “big data condition” n ≥ βL/µ.
The resulting algorithm can be interpreted as a variant of proximal SDCA [25] with a different step
size and a more practical optimality certificate—that is, checking the optimality condition does not
require evaluating a dual objective. Our construction is indeed purely primal. Neither our proof of
convergence nor the algorithm use duality, while SDCA is originally a dual ascent technique.
Related work. The catalyst acceleration can be interpreted as a variant of the proximal point algo-
rithm [3, 9], which is a central concept in convex optimization, underlying augmented Lagrangian
approaches, and composite minimization schemes [5, 20]. The proximal point algorithm consists
of solving (1) by minimizing a sequence of auxiliary problems involving a quadratic regulariza-
tion term. In general, these auxiliary problems cannot be solved with perfect accuracy, and several
notations of inexactness were proposed, including [9, 10, 22]. The catalyst approach hinges upon
(i) an acceleration technique for the proximal point algorithm originally introduced in the pioneer
work [9]; (ii) a more practical inexactness criterion than those proposed in the past.
1
As a result, we
are able to control the rate of convergence for approximately solving the auxiliary problems with
an optimization method M. In turn, we are also able to obtain the computational complexity of the
global procedure for solving (1), which was not possible with previous analysis [9, 10, 22]. When
instantiated in different first-order optimization settings, our analysis yields systematic acceleration.
Beyond [9], several works have inspired this paper. In particular, accelerated SDCA [26] is an
instance of an inexact accelerated proximal point algorithm, even though this was not explicitly
stated in [26]. Their proof of convergence relies on different tools than ours. Specifically, we use the
concept of estimate sequence from Nesterov [17], whereas the direct proof of [26], in the context
of SDCA, does not extend to non-strongly convex objectives. Nevertheless, part of their analysis
proves to be helpful to obtain our main results. Another useful methodological contribution was the
convergence analysis of inexact proximal gradient methods of [23]. Finally, similar ideas appear in
the independent work [8]. Their results overlap in part with ours, but both papers adopt different
directions. Our analysis is for instance more general and provides support for non-strongly convex
objectives. Another independent work with related results is [13], which introduce an accelerated
method for the minimization of finite sums, which is not based on the proximal point algorithm.
1
Note that our inexact criterion was also studied, among others, in [22], but the analysis of [22] led to the
conjecture that this criterion was too weak to warrant acceleration. Our analysis refutes this conjecture.
2

2 The Catalyst Acceleration
We present here our generic acceleration scheme, which can operate on any first-order or gradient-
based optimization algorithm with linear convergence rate for strongly convex objectives.
Linear convergence and acceleration. Consider the problem (1) with a µ-strongly convex func-
tion F , where the strong convexity is defined with respect to the ℓ
2
-norm. A minimization algo-
rithm M, generating the sequence of iterates (x
k
)
k≥0
, has a linear convergence rate if there exists
τ
M,F
in (0, 1) and a constant C
M,F
in R such that
F (x
k
) − F
∗
≤ C
M,F
(1 − τ
M,F
)
k
, (3)
where F
∗
denotes the minimum value of F . The quantity τ
M,F
controls the convergence rate: the
larger is τ
M,F
, the faster is convergence to F
∗
. However, for a given algorithm M, the quantity
τ
M,F
depends usually on the ratio L/µ, which is often called the condition number of F .
The catalyst acceleration is a general approach that allows to wrap algorithm M into an accelerated
algorithm A, which enjoys a faster linear convergence rate, with τ
A,F
≥ τ
M,F
. As we will also see,
the catalyst acceleration may also be useful when F is not strongly convex—that is, when µ = 0. In
that case, we may even consider a method M that requires strong convexity to operate, and obtain
an accelerated algorithm A that can minimize F with near-optimal convergence rate
˜
O(1/k
2
).
2
Our approach can accelerate a wide range of first-order optimization algorithms, starting from clas-
sical gradient descent. It also applies to randomized algorithms such as SAG, SAGA, SDCA, SVRG
and Finito/MISO, whose rates of convergence are given in expectation. Such methods should be
contrasted with stochastic gradient methods [15, 12], which minimize a different non-deterministic
function. Acceleration of stochastic gradient methods is beyond the scope of this work.
Catalyst action. We now highlight the mechanics of the catalyst algorithm, which is presented in
Algorithm 1. It consists of replacing, at iteration k, the original objective function F by an auxiliary
objective G
k
, close to F up to a quadratic term:
G
k
(x) , F (x) +
κ
2
kx − y
k−1
k
2
, (4)
where κ will be specified later and y
k
is obtained by an extrapolation step described in (6). Then, at
iteration k, the accelerated algorithm A minimizes G
k
up to accuracy ε
k
.
Substituting (4) to (1) has two consequences. On the one hand, minimizing (4) only provides an
approximation of the solution of (1), unless κ = 0; on the other hand, the auxiliary objective G
k
enjoys a better condition number than the original objective F , which makes it easier to minimize.
For instance, when M is the regular gradient descent algorithm with ψ = 0, M has the rate of
convergence (3) for minimizing F with τ
M,F
= µ/L. However, owing to the additional quadratic
term, G
k
can be minimized by M with the rate (3) where τ
M,G
k
= (µ + κ)/(L + κ) > τ
M,F
. In
practice, there exists an “optimal” choice for κ, which controls the time required by M for solving
the auxiliary problems (4), and the quality of approximation of F by the functions G
k
. This choice
will be driven by the convergence analysis in Sec. 3.1-3.3; see also Sec. C for special cases.
Acceleration via extrapolation and inexact minimization. Similar to the classical gradient de-
scent scheme of Nesterov [17], Algorithm 1 involvesan extrapolationstep (6). As a consequence, the
solution of the auxiliary problem (5) at iteration k + 1 is driven towards the extrapolated variable y
k
.
As shown in [9], this step is in fact sufficient to reduce the number of iterations of Algorithm 1 to
solve (1) when ε
k
= 0—that is, for running the exact accelerated proximal point algorithm.
Nevertheless, to control the total computational complexity of an accelerated algorithm A, it is nec-
essary to take into account the complexity of solving the auxiliary problems (5) using M. This
is where our approach differs from the classical proximal point algorithm of [9]. Essentially, both
algorithms are the same, but we use the weaker inexactness criterion G
k
(x
k
) −G
∗
k
≤ ε
k
, where the
sequence (ε
k
)
k≥0
is fixed beforehand, and only depends on the initial point. This subtle difference
has important consequences: (i) in practice, this condition can often be checked by computing dual-
ity gaps; (ii) in theory, the methods M we consider have linear convergence rates, which allows us
to control the complexity of step (5), and then to provide the computational complexity of A.
2
In this paper, we use the notation O(.) to hide constants. The notation
˜
O(.) also hides logarithmic factors.
3

Algorithm 1 Catalyst
input initial estimate x
0
∈ R
p
, parameters κ and α
0
, sequence (ε
k
)
k≥0
, optimization method M;
1: Initialize q = µ/(µ + κ) and y
0
= x
0
;
2: while the desired stopping criterion is not satisfied do
3: Find an approximate solution of the following problem using M
x
k
≈ arg min
x∈R
p
n
G
k
(x) , F (x) +
κ
2
kx − y
k−1
k
2
o
such that G
k
(x
k
) − G
∗
k
≤ ε
k
. (5)
4: Compute α
k
∈ (0, 1) from equation α
2
k
= (1 − α
k
)α
2
k−1
+ qα
k
;
5: Compute
y
k
= x
k
+ β
k
(x
k
− x
k−1
) with β
k
=
α
k−1
(1 − α
k−1
)
α
2
k−1
+ α
k
. (6)
6: end while
output x
k
(final estimate).
3 Convergence Analysis
In this section, we present the theoretical properties of Algorithm 1, for optimization methods M
with deterministic convergence rates of the form (3). When the rate is given as an expectation, a
simple extension of our analysis described in Section 4 is needed. For space limitation reasons, we
shall sketch the proof mechanics here, and defer the full proofs to Appendix B.
3.1 Analysis for µ-Strongly Convex Objective Functions
We first analyze the convergence rate of Algorithm 1 for solving problem 1, regardless of the com-
plexity required to solve the subproblems (5). We start with the µ-strongly convex case.
Theorem 3.1 (Convergence of Algorithm 1, µ-Strongly Convex Case).
Choose α
0
=
√
q with q = µ/(µ + κ) and
ε
k
=
2
9
(F (x
0
) − F
∗
)(1 − ρ)
k
with ρ <
√
q.
Then, Algorithm 1 generates iterates (x
k
)
k≥0
such that
F (x
k
) − F
∗
≤ C(1 −ρ)
k+1
(F (x
0
) − F
∗
) with C =
8
(
√
q −ρ)
2
. (7)
This theorem characterizes the linear convergence rate of Algorithm 1. It is worth noting that the
choice of ρ is left to the discretion of the user, but it can safely be set to ρ = 0.9
√
q in practice.
The choice α
0
=
√
q was made for convenience purposes since it leads to a simplified analysis, but
larger values are also acceptable, both from theoretical and practical point of views. Following an
advice from Nesterov[17, page 81] originally dedicated to his classical gradient descent algorithm,
we may for instance recommend choosing α
0
such that α
2
0
+ (1 − q)α
0
− 1 = 0.
The choice of the sequence (ε
k
)
k≥0
is also subject to discussion since the quantity F (x
0
) − F
∗
is
unknown beforehand. Nevertheless, an upper bound may be used instead, which will only affects
the corresponding constant in (7). Such upper bounds can typically be obtained by computing a
duality gap at x
0
, or by using additional knowledge about the objective. For instance, when F is
non-negative, we may simply choose ε
k
= (2/9)F (x
0
)(1 − ρ)
k
.
The proof of convergence uses the concept of estimate sequence invented by Nesterov [17], and
introduces an extension to deal with the errors (ε
k
)
k≥0
. To control the accumulation of errors, we
borrow the methodology of [23] for inexact proximal gradient algorithms. Our construction yields a
convergence result that encompasses both strongly convex and non-strongly convex cases. Note that
estimate sequences were also used in [9], but, as noted by [22], the proof of [9] only applies when
using an extrapolation step (6) that involves the true minimizer of (5), which is unknown in practice.
To obtain a rigorous convergence result like (7), a different approach was needed.
4
Theorem 3.1 is important, but it does not provide yet the global computational complexity of the full
algorithm, which includes the number of iterations performed by M for approximately solving the
auxiliary problems (5). The next proposition characterizes the complexity of this inner-loop.
Proposition 3.2 (Inner-Loop Complexity, µ-Strongly Convex Case).
Under the assumptions of Theorem 3.1, let us consider a method M generating iterates (z
t
)
t≥0
for
minimizing the function G
k
with linear convergence rate of the form
G
k
(z
t
) − G
∗
k
≤ A(1 − τ
M
)
t
(G
k
(z
0
) − G
∗
k
). (8)
When z
0
= x
k−1
, the precision ε
k
is reached with a number of iterations T
M
=
˜
O(1/τ
M
), where
the notation
˜
O hides some universal constants and some logarithmic dependencies in µ and κ.
This proposition is generic since the assumption (8) is relatively standard for gradient-based meth-
ods [17]. It may now be used to obtain the global rate of convergence of an accelerated algorithm.
By calling F
s
the objective function value obtained after performing s = kT
M
iterations of the
method M, the true convergence rate of the accelerated algorithm A is
F
s
−F
∗
= F
x
s
T
M
−F
∗
≤ C(1 −ρ)
s
T
M
(F (x
0
) −F
∗
) ≤ C
1 −
ρ
T
M
s
(F (x
0
) −F
∗
). (9)
As a result, algorithm A has a global linear rate of convergence with parameter
τ
A,F
= ρ/T
M
=
˜
O(τ
M
√
µ/
√
µ + κ),
where τ
M
typically depends on κ (the greater, the faster is M). Consequently, κ will be chosen to
maximize the ratio τ
M
/
√
µ + κ. Note that for other algorithms M that do not satisfy (8), additional
analysis and possibly a different initialization z
0
may be necessary (see Appendix D for example).
3.2 Convergence Analysis for Convex but Non-Strongly Convex Objective Functions
We now state the convergence rate when the objective is not strongly convex, that is when µ = 0.
Theorem 3.3 (Convergence of Algorithm 1, Convex, but Non-Strongly Convex Case).
When µ = 0, choose α
0
= (
√
5 − 1)/2 and
ε
k
=
2(F (x
0
) − F
∗
)
9(k + 2)
4+η
with η > 0. (10)
Then, Algorithm 1 generates iterates (x
k
)
k≥0
such that
F (x
k
) − F
∗
≤
8
(k + 2)
2
1 +
2
η
2
(F (x
0
) − F
∗
) +
κ
2
kx
0
− x
∗
k
2
!
. (11)
This theorem is the counter-part of Theorem 3.1 when µ = 0. The choice of η is left to the discretion
of the user; it empirically seem to have very low influence on the global convergence speed, as long
as it is chosen small enough (e.g., we use η = 0.1 in practice). It shows that Algorithm 1 achieves the
optimal rate of convergence of first-order methods, but it does not take into account the complexity
of solving the subproblems (5). Therefore, we need the following proposition:
Proposition 3.4 (Inner-Loop Complexity, Non-Strongly Convex Case).
Assume that F has bounded level sets. Under the assumptions of Theorem 3.3, let us consider a
method M generating iterates (z
t
)
t≥0
for minimizing the function G
k
with linear convergence rate
of the form (8). Then, there exists T
M
=
˜
O(1/τ
M
), such that for any k ≥ 1, solving G
k
with initial
point x
k−1
requires at most T
M
log(k + 2) iterations of M.
We can now draw up the global complexity of an accelerated algorithm A when M has a lin-
ear convergence rate (8) for κ-strongly convex objectives. To produce x
k
, M is called at most
kT
M
log(k + 2) times. Using the global iteration counter s = kT
M
log(k + 2), we get
F
s
− F
∗
≤
8T
2
M
log
2
(s)
s
2
1 +
2
η
2
(F (x
0
) − F
∗
) +
κ
2
kx
0
− x
∗
k
2
!
. (12)
If M is a first-order method, this rate is near-optimal, up to a logarithmic factor, when compared to
the optimal rate O(1 /s
2
), which may be the price to pay for using a generic acceleration scheme.
5
4 Acceleration in Practice
We show here how to accelerate existing algorithms M and compare the convergence rates obtained
before and after catalyst acceleration. For all the algorithms we consider, we study rates of conver-
gence in terms of total number of iterations (in expectation, when necessary) to reach accuracy ε.
We first show how to accelerate full gradient and randomized coordinate descent algorithms [21].
Then, we discuss other approaches such as SAG [24], SAGA [6], or SVRG [27]. Finally, we present
a new proximal version of the incremental gradient approaches Finito/MISO [7, 14], along with its
accelerated version. Table 4.1 summarizes the acceleration obtained for the algorithms considered.
Deriving the global rate of convergence. The convergence rate of an accelerated algorithm A is
driven by the parameter κ. In the strongly convex case, the best choice is the one that maximizes
the ratio τ
M,G
k
/
√
µ + κ. As discussed in Appendix C, this rule also holds when (8) is given in
expectation and in many cases where the constant C
M,G
k
is different than A(G
k
(z
0
)−G
∗
k
) from (8).
When µ = 0, the choice of κ > 0 only affects the complexity by a multiplicative constant. A rule
of thumb is to maximize the ratio τ
M,G
k
/
√
L + κ (see Appendix C for more details).
After choosing κ, the global iteration-complexity is given by Comp ≤ k
in
k
out
, where k
in
is an upper-
bound on the number of iterations performed by M per inner-loop, and k
out
is the upper-bound on
the number of outer-loop iterations, following from Theorems 3.1-3.3. Note that for simplicity, we
always consider that L ≫ µ such that we may write L − µ simply as “L” in the convergence rates.
4.1 Acceleration of Existing Algorithms
Composite minimization. Most of the algorithms we consider here, namely the proximal gradient
method [4, 19], SAGA [6], (Prox)-SVRG [27], can handle composite objectiveswith a regularization
penalty ψ that admits a proximal operator prox
ψ
, defined for any z as
prox
ψ
(z) , a rg min
y∈R
p
ψ(y) +
1
2
ky −zk
2
.
Table 4.1 presents convergence rates that are valid for proximal and non-proximal settings, since
most methods we consider are able to deal with such non-differentiable penalties. The exception is
SAG [24], for which proximal variants are not analyzed. The incremental method Finito/MISO has
also been limited to non-proximal settings so far. In Section 4.2, we actually introduce the extension
of MISO to composite minimization, and establish its theoretical convergence rates.
Full gradient method. A first illustration is the algorithm obtained when accelerating the regular
“full” gradient descent (FG), and how it contrasts with Nesterov’s accelerated variant (AFG). Here,
the optimal choice for κ is L − 2µ. In the strongly convex case, we get an accelerated rate of
convergence in
˜
O(n
p
L/µ log(1/ε)), which is the same as AFG up to logarithmic terms. A similar
result can also be obtained for randomized coordinate descent methods [21].
Randomized incremental gradient. We now consider randomized incremental gradient methods,
resp. SAG [24] and SAGA [6]. When µ > 0, we focus on the “ill-conditioned” setting n ≤ L/µ,
where these methods have the complexity O((L/µ) log(1/ε)). Otherwise, their complexitybecomes
O(n log(1/ε)), which is independent of the condition number and seems theoretically optimal [1].
For these methods, the best choice for κ has the form κ = a(L − µ)/(n + b) − µ, with (a, b) =
(2, −2) for SAG, (a, b) = (1/2, 1/2 ) for SAGA. A similar formula, with a constant L
′
in place of
L, holds for SVRG; we omit it here for brevity. SDCA [26] and Finito/MISO [7, 14] are actually
related to incremental gradient methods, and the choice for κ has a similar form with (a, b) = (1, 1).
4.2 Proximal MISO and its Acceleration
Finito/MISO was proposed in [7] and [14] for solving the problem (1) when ψ = 0 and when f is
a sum of n µ-strongly convex functions f
i
as in (2), which are also differentiable with L-Lipschitz
derivatives. The algorithm maintains a list of quadratic lower bounds—say (d
k
i
)
n
i=1
at iteration k—
of the functions f
i
and randomly updates one of them at each iteration by using strong-convexity
6

Comp. µ > 0 Comp. µ = 0 Catalyst µ > 0 Catalyst µ = 0
FG O
n
L
µ
log
1
ε
O
n
L
ε
˜
O
n
q
L
µ
log
1
ε
˜
O
n
L
√
ε
SAG [24]
O
L
µ
log
1
ε
˜
O
q
nL
µ
log
1
ε
SAGA [6]
Finito/MISO-Prox
not avail.
SDCA [25]
SVRG [27] O
L
′
µ
log
1
ε
˜
O
q
nL
′
µ
log
1
ε
Acc-FG [19] O
n
q
L
µ
log
1
ε
O
n
L
√
ε
no acceleration
Acc-SDCA [26]
˜
O
q
nL
µ
log
1
ε
not avail.
Table 1: Comparison of rates of convergence, before and after the catalyst acceleration, resp. in
the strongly-convex and non strongly-convex cases. To simplify, we only present the case where
n ≤ L/µ when µ > 0. For all incremental algorithms, there is indeed no acceleration otherwise.
The quantity L
′
for SVRG is the average Lipschitz constant of the functions f
i
(see [27]).
inequalities. The current iterate x
k
is then obtained by minimizing the lower-bound of the objective
x
k
= arg min
x∈R
p
(
D
k
(x) =
1
n
n
X
i=1
d
k
i
(x)
)
. (13)
Interestingly, since D
k
is a lower-bound of F we also have D
k
(x
k
) ≤ F
∗
, and thus the quantity
F (x
k
) − D
k
(x
k
) can be used as an optimality certificate that upper-bounds F(x
k
) − F
∗
. Further-
more, this certificate was shown to convergeto zero with a rate similar to SAG/SDCA/SVRG/SAGA
under the condition n ≥ 2L/µ. In this section, we show how to remove this condition and how to
provide support to non-differentiable functions ψ whose proximal operator can be easily computed.
We shall briefly sketch the main ideas, and we refer to Appendix D for a thorough presentation.
The first idea to deal with a nonsmooth regularizer ψ is to change the definition of D
k
:
D
k
(x) =
1
n
n
X
i=1
d
k
i
(x) + ψ(x),
which was also proposed in [7] without a convergence proof. Then, because the d
k
i
’s are quadratic
functions, the minimizer x
k
of D
k
can be obtained by computing the proximal operator of ψ at a
particular point. The second idea to remove the condition n ≥ 2L/µ is to modify the update of the
lower bounds d
k
i
. Assume that index i
k
is selected among {1, . . . , n} at iteration k, then
d
k
i
(x) =
(1 − δ)d
k−1
i
(x)+ δ(f
i
(x
k−1
)+h∇f
i
(x
k−1
), x − x
k−1
i+
µ
2
kx − x
k−1
k
2
) if i = i
k
d
k−1
i
(x) otherwise
Whereas the original Finito/MISO uses δ = 1, our new variant uses δ = min(1, µn/2(L − µ)).
The resulting algorithm turns out to be very close to variant “5” of proximal SDCA [25], which
corresponds to using a different value for δ. The main difference between SDCA and MISO-
Prox is that the latter does not use duality. It also provides a different (simpler) optimality cer-
tificate F (x
k
) − D
k
(x
k
), which is guaranteed to converge linearly, as stated in the next theorem.
Theorem 4.1 (Convergence of MISO-Prox).
Let (x
k
)
k≥0
be obtained by MISO-Prox, then
E[F (x
k
)] − F
∗
≤
1
τ
(1 − τ)
k+1
(F (x
0
) − D
0
(x
0
)) with τ ≥ min
n
µ
4L
,
1
2n
o
. (14)
Furthermore, we also have fast convergence of the certificate
E[F (x
k
) − D
k
(x
k
)] ≤
1
τ
(1 − τ)
k
(F
∗
− D
0
(x
0
)) .
The proof of convergence is given in Appendix D. Finally, we conclude this section by noting that
MISO-Prox enjoys the catalyst acceleration, leading to the iteration-complexity presented in Ta-
ble 4.1. Since the convergence rate (14) does not have exactly the same form as (8), Propositions 3.2
and 3.4 cannot be used and additional analysis, given in Appendix D, is needed. Practical forms of
the algorithm are also presented there, along with discussions on how to initialize it.
7
5 Experiments
We evaluate the Catalyst acceleration on three methods that have never been accelerated in the past:
SAG [24], SAGA [6], and MISO-Prox. We focus on ℓ
2
-regularized logistic regression, where the
regularization parameter µ yields a lower bound on the strong convexity parameter of the problem.
We use three datasets used in [14], namely real-sim, rcv1, and ocr, which are relatively large, with
up to n = 2 500 000 points for ocr and p = 47 152 variables for rcv1. We consider three regimes:
µ = 0 (no regularization), µ/L = 0.001/n and µ/L = 0.1 /n, which leads significantly larger
condition numbers than those used in other studies (µ/L ≈ 1/n in [14, 24]). We compare MISO,
SAG, and SAGA with their default parameters, which are recommended by their theoretical analysis
(step-sizes 1/L for SAG and 1/3L for SAGA), and study several accelerated variants. The values of
κ and ρ and the sequences (ε
k
)
k≥0
are those suggested in the previous sections, with η = 0.1 in (10).
Other implementation details are presented in Appendix E.
The restarting strategy for M is key to achieve acceleration in practice. All of the methods we com-
pare store n gradients evaluated at previous iterates of the algorithm. We always use the gradients
from the previous run of M to initialize a new one. We detail in Appendix E the initialization for
each method. Finally, we evaluated a heuristic that constrain M to always perform at most n iter-
ations (one pass over the data); we call this variant AMISO2 for MISO whereas AMISO1 refers to
the regular “vanilla” accelerated variant, and we also use this heuristic to accelerate SAG.
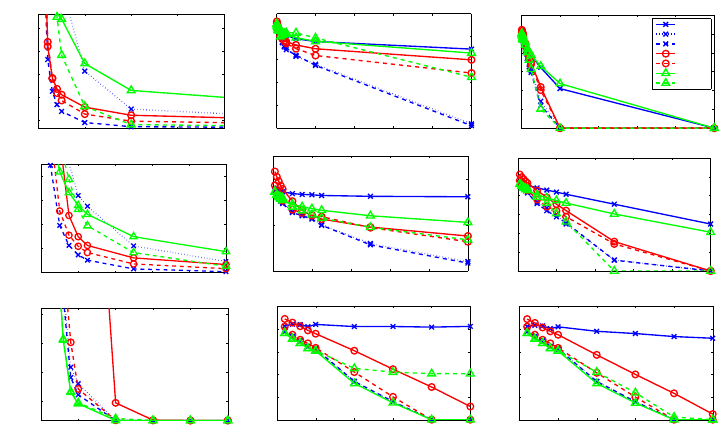
The results are reported in Table 1. We always obtain a huge speed-up for MISO, which suffers from
numerical stability issues when the condition number is very large (for instance, µ/L = 1 0
−3
/n =
4.10
−10
for ocr). Here, not only does the catalyst algorithm accelerate MISO, but it also stabilizes
it. Whereas MISO is slower than SAG and SAGA in this “small µ” regime, AMISO2 is almost
systematically the best performer. We are also able to accelerate SAG and SAGA in general, even
though the improvement is less significant than for MISO. In particular, SAGA without acceleration
proves to be the best method on ocr. One reason may be its ability to adapt to the unknown strong
convexity parameter µ
′
≥ µ of the objective near the solution. When µ
′
/L ≥ 1/n, we indeed obtain
a regime where acceleration does not occur (see Sec. 4). Therefore, this experiment suggests that
adaptivity to unknown strong convexity is of high interest for incremental optimization.
0 50 100 150 200
4
6
8
10
12
x 10
−3
#Passes, Dataset real-sim, µ = 0
Objective function
0 100 200 300 400 500
10
−8
10
−6
10
−4
10
−2
10
0
#Passes, Dataset real-sim, µ/L = 10
−3
/n
Relative duality gap
0 100 200 300 400 500
10
−10
10
−8
10
−6
10
−4
10
−2
10
0
#Passes, Dataset real-sim, µ/L = 10
−1
/n
Relative duality gap
MISO
AMISO1
AMISO2
SAG
ASAG
SAGA
ASAGA
0 20 40 60 80 100
0.096
0.098
0.1
0.102
0.104
#Passes, Dataset rcv1, µ = 0
Objective function
0 20 40 60 80 100
10
−4
10
−2
10
0
#Passes, Dataset rcv1, µ/L = 10
−3
/n
Relative duality gap
0 20 40 60 80 100
10
−10
10
−8
10
−6
10
−4
10
−2
10
0
#Passes, Dataset rcv1, µ/L = 10
−1
/n
Relative duality gap
0 5 10 15 20 25
0.4957
0.4958
0.4959
0.496
#Passes, Dataset ocr, µ = 0
Objective function
0 5 10 15 20 25
10
−10
10
−8
10
−6
10
−4
10
−2
10
0
#Passes, Dataset ocr, µ/L = 10
−3
/n
Relative duality gap
0 5 10 15 20 25
10
−10
10
−8
10
−6
10
−4
10
−2
10
0
#Passes, Dataset ocr, µ/L = 10
−1
/n
Relative duality gap
Figure 1: Objective function value (or duality gap) for different number of passes performed over
each dataset. The legend for all curves is on the top right. AMISO, ASAGA, ASAG refer to the
accelerated variants of MISO, SAGA, and SAG, respectively.
Acknowledgments
This work was supported by ANR (MACARON ANR-14-CE23-0003-01), MSR-Inria joint centre,
CNRS-Mastodons program (Titan), and NYU Moore-Sloan Data Science Environment.
8
References
[1] A. Agarwal and L. Bottou. A lower bound for the optimization of finite sums. In Proc. International
Conference on Machine Learning (ICML), 2015.
[2] F. Bach, R. Jenatton, J. Mairal, and G. Obozinski. Optimization with sparsity-inducing penalties. Foun-
dations and Trends in Machine Learning, 4(1):1–106, 2012.
[3] H. H. Bauschke and P. L. Combettes. Convex Analysis and Monotone Operator Theory in Hilbert Spaces.
Springer, 2011.
[4] A. Beck and M. Teboulle. A fast iterative shrinkage-thresholding algorithm for linear inverse problems.
SIAM Journal on Imaging Sciences, 2(1):183–202, 2009.
[5] D. P. Bertsekas. Convex Optimization Algorithms. Athena Scientific, 2015.
[6] A. J. Defazio, F. Bach, and S. Lacoste-Julien. SAGA: A fast incremental gradient method with support
for non-strongly convex composite objectives. In Adv. Neural Information Processing Systems (NIPS),
2014.
[7] A. J. Defazio, T. S. Caetano, and J. Domke. Finito: A faster, permutable incremental gradient method for
big data problems. In Proc. International Conference on Machine Learning (ICML), 2014.
[8] R. Frostig, R. Ge, S. M. Kakade, and A. Sidford. Un-regularizing: approximate proximal point algorithms
for empirical risk minimization. In Proc. International Conference on Machine Learning (ICML), 2015.
[9] O. G¨uler. New proximal point algorithms for convex minimization. SIAM Journal on Optimization,
2(4):649–664, 1992.
[10] B. He and X. Yuan. An accelerated inexact proximal point algorithm for convex minimization. Journal
of Optimization Theory and Applications, 154(2):536–548, 2012.
[11] J.-B. Hiriart-Urruty and C. Lemar´echal. Convex Analysis and Minimization Algorithms I. Springer, 1996.
[12] A. Juditsky and A. Nemirovski. First order methods for nonsmooth convex large-scale optimization.
Optimization for Machine Learning, MIT Press, 2012.
[13] G. Lan. An optimal randomized incremental gradient method. arXiv:1507.02000, 2015.
[14] J. Mairal. Incremental majorization-minimization optimization with application to large-scale machine
learning. SIAM Journal on Optimization, 25(2):829–855, 2015.
[15] A. Nemirovski, A. Juditsky, G. Lan, and A. Shapiro. Robust stochastic approximation approach to
stochastic programming. SIAM Journal on Optimization, 19(4):1574–1609, 2009.
[16] Y. Nesterov. A method of solving a convex programming problem with convergence rate O(1/k
2
). Soviet
Mathematics Doklady, 27(2):372–376, 1983.
[17] Y. Nesterov. Introductory Lectures on Convex Optimization: A Basic Course. Springer, 2004.
[18] Y. Nesterov. Efficiency of coordinate descent methods on huge-scale optimization problems. SIAM
Journal on Optimization, 22(2):341–362, 2012.
[19] Y. Nesterov. Gradient methods for minimizing composite functions. Mathematical Programming,
140(1):125–161, 2013.
[20] N. Parikh and S.P. Boyd. Proximal algorithms. Foundations and Trends in Optimization, 1(3):123–231,
2014.
[21] P. Richt´arik and M. Tak´aˇc. Iteration complexity of randomized block-coordinate descent methods for
minimizing a composite function. Mathematical Programming, 144(1-2):1–38, 2014.
[22] S. Salzo and S. Villa. Inexact and accelerated proximal point algorithms. Journal of Convex Analysis,
19(4):1167–1192, 2012.
[23] M. Schmidt, N. Le Roux, and F. Bach. Convergence rates of inexact proximal-gradient methods for
convex optimization. In Adv. Neural Information Processing Systems (NIPS), 2011.
[24] M. Schmidt, N. Le Roux, and F. Bach. Minimizing finite sums with the stochastic average gradient.
arXiv:1309.2388, 2013.
[25] S. Shalev-Shwartz and T. Zhang. Proximal stochastic dual coordinate ascent. arXiv:1211.2717, 2012.
[26] S. Shalev-Shwartz and T. Zhang. Accelerated proximal stochastic dual coordinate ascent for regularized
loss minimization. Mathematical Programming, 2015.
[27] L. Xiao and T. Zhang. A proximal stochastic gradient method with progressive variance reduction. SIAM
Journal on Optimization, 24(4):2057–2075, 2014.
[28] Y. Zhang and L. Xiao. Stochastic primal-dual coordinate method for regularized empirical risk minimiza-
tion. In Proc. International Conference on Machine Learning (ICML), 2015.
9

In this appendix, Section A is devoted to the construction of an object called estimate sequence,
originally introduced by Nesterov (see [17]), and introduce extensions to deal with inexact mini-
mization. This section contains a generic convergence result that will be used to prove the main
theorems and propositions of the paper in Section B. Then, Section C is devoted to the computation
of global convergence rates of accelerated algorithms, Section D presents in details the proximal
MISO algorithm, and Section E gives some implementation details of the experiments.
A Construction of the Approximate Estimate Sequence
The estimate sequence is a generic tool introduced by Nesterov for proving the convergence of
accelerated gradient-based algorithms. We start by recalling the definition given in [17].
Definition A.1 (Estimate Sequence [17]).
A pair of sequences (ϕ
k
)
k≥0
and (λ
k
)
k≥0
, with λ
k
≥ 0 and ϕ
k
: R
p
→ R, is called an estimate
sequence of function F if
λ
k
→ 0,
and for any x in R
p
and all k ≥ 0, we have
ϕ
k
(x) ≤ (1 − λ
k
)F (x) + λ
k
ϕ
0
(x).
Estimate sequences are used for proving convergence rates thanks to the following lemma
Lemma A.2 (Lemma 2.2.1 from [17]).
If for some sequence (x
k
)
k≥0
we have
F (x
k
) ≤ ϕ
∗
k
, min
x∈R
p
ϕ
k
(x),
for an estimate sequence (ϕ
k
)
k≥0
of F , then
F (x
k
) − F
∗
≤ λ
k
(ϕ
0
(x
∗
) − F
∗
),
where x
∗
is a minimizer of F .
The rate of convergence of F(x
k
) is thus directly related to the convergence rate of λ
k
. Constructing
estimate sequences is thus appealing, even though finding the most appropriate one is not trivial for
the catalyst algorithm because of the approximate minimization of G
k
in (5). In a nutshell, the main
steps of our convergence analysis are
1. define an “approximate” estimate sequence for F corresponding to Algorithm 1—that is,
finding a function ϕ that almost satisfies Definition A.1 up to the approximation errors ε
k
made in (5) when minimizing G
k
, and control the way these errors sum up together.
2. extend Lemma A.2 to deal with the approximationerrors ε
k
to derivea generic convergence
rate for the sequence (x
k
)
k≥0
.
This is also the strategy proposed by G¨uler in [9] for his inexact accelerated proximal point al-
gorithm, which essentially differs from ours in its stopping criterion. The estimate sequence we
choose is also different and leads to a more rigorous convergence proof. Specifically, we prove in
this section the following theorem:
Theorem A.3 (Convergence Result Derived from an Approximate Estimate Sequence).
Let us denote
λ
k
=
k−1
Y
i=0
(1 − α
i
), (15)
where the α
i
’s are defined in Algorithm 1. Then, the sequence (x
k
)
k≥0
satisfies
F (x
k
) − F
∗
≤ λ
k
p
S
k
+ 2
k
X
i=1
r
ε
i
λ
i
!
2
, (16)
where F
∗
is the minimum value of F and
S
k
= F (x
0
) − F
∗
+
γ
0
2
kx
0
− x
∗
k
2
+
k
X
i=1
ε
i
λ
i
where γ
0
=
α
0
((κ + µ)α
0
− µ)
1 − α
0
, (17)
where x
∗
is a minimizer of F .
10

Then, the theorem will be used with the following lemma from [17] to control the convergence rate
of the sequence (λ
k
)
k≥0
, whose definition follows the classical use of estimate sequences [17]. This
will provide us convergence rates both for the strongly convex and non-strongly convex cases.
Lemma A.4 (Lemma 2.2.4 from [17]).
If in the quantity γ
0
defined in (17) satisfies γ
0
≥ µ, then the sequence (λ
k
)
k≥0
from (15) satisfies
λ
k
≤ min
(1 −
√
q)
k
,
4
2 + k
q
γ
0
κ+µ
2
. (18)
We may now move to the proof of the theorem.
A.1 Proof of Theorem A.3
The first step is to construct an estimate sequence is typically to find a sequence of lower bounds
of F . By calling x
∗
k
the minimizer of G
k
, the following one is used in [9]:
Lemma A.5 (Lower Bound for F near x
∗
k
).
For all x in R
p
,
F (x) ≥ F (x
∗
k
) + hκ(y
k−1
− x
∗
k
), x − x
∗
k
i +
µ
2
kx − x
∗
k
k
2
. (19)
Proof. By strong convexity, G
k
(x) ≥ G
k
(x
∗
k
) +
κ+µ
2
kx − x
∗
k
k
2
, which is equivalent to
F (x) +
κ
2
kx − y
k
k
2
≥ F (x
∗
k
) +
κ
2
kx
∗
k
− y
k−1
k
2
+
κ + µ
2
kx − x
∗
k
k
2
.
After developing the quadratic terms, we directly obtain (19).
Unfortunately, the exact value x
∗
k
is unknown in practice and the estimate sequence of [9] yields
in fact an algorithm where the definition of the anchor point y
k
involves the unknown quantity x
∗
k
instead of the approximate solutions x
k
and x
k−1
as in (6), as also noted by others [22]. To obtain a
rigorous proof of convergence for Algorithm 1, it is thus necessary to refine the analysis of [9]. To
that effect, we construct below a sequence of functions that approximately satisfies the definition of
estimate sequences. Essentially, we replace in (19) the quantity x
∗
k
by x
k
to obtain an approximate
lower bound, and control the error by using the condition G
k
(x
k
) − G
k
(x
∗
k
) ≤ ε
k
. This leads us to
the following construction:
1. φ
0
(x) = F (x
0
) +
γ
0
2
kx − x
0
k
2
;
2. For k ≥ 1, we set
φ
k
(x) = (1 − α
k−1
)φ
k−1
(x) + α
k−1
[F (x
k
) + hκ(y
k−1
− x
k
), x − x
k
i +
µ
2
kx − x
k
k
2
],
where the value of γ
0
, given in (17) will be explained later. Note that if one replaces x
k
by x
∗
k
in
the above construction, it is easy to show that (φ
k
)
k≥0
would be exactly an estimate sequence for F
with the relation λ
k
given in (15).
Before extending Lemma A.2 to deal with the approximate sequence and conclude the proof of
the theorem, we need to characterize a few properties of the sequence (φ
k
)
k≥0
. In particular, the
functions φ
k
are quadratic and admit a canonical form:
Lemma A.6 (Canonical Form of the Functions φ
k
).
For all k ≥ 0, φ
k
can be written in the canonical form
φ
k
(x) = φ
∗
k
+
γ
k
2
kx − v
k
k
2
,
11

where the sequences (γ
k
)
k≥0
, (v
k
)
k≥0
, and (φ
∗
k
)
k≥0
are defined as follows
γ
k
= (1 − α
k−1
)γ
k−1
+ α
k−1
µ, (20)
v
k
=
1
γ
k
((1 − α
k−1
)γ
k−1
v
k−1
+ α
k−1
µx
k
− α
k−1
κ(y
k−1
− x
k
)) , (21)
φ
∗
k
= (1 − α
k−1
)φ
∗
k−1
+ α
k−1
F (x
k
) −
α
2
k−1
2γ
k
kκ(y
k−1
− x
k
)k
2
+
α
k−1
(1 − α
k−1
)γ
k−1
γ
k
µ
2
kx
k
− v
k−1
k
2
+ hκ(y
k−1
− x
k
), v
k−1
− x
k
i
, (22)
Proof. We have for all k ≥ 1 and all x in R
p
,
φ
k
(x) = (1 − α
k−1
)
φ
∗
k−1
+
γ
k−1
2
kx − v
k−1
k
2
+ α
k−1
F (x
k
) + hκ(y
k−1
− x
k
), x − x
k
i +
µ
2
kx − x
k
k
2
= φ
∗
k
+
γ
k
2
kx − v
k
k
2
.
(23)
Differentiate twice the relations (23) gives us directly (20). Since v
k
minimizes φ
k
, the optimality
condition ∇φ
k
(v
k
) = 0 gives
(1 − α
k−1
)γ
k−1
(v
k
− v
k−1
) + α
k−1
(κ(y
k−1
− x
k
) + µ(v
k
− x
k
)) = 0,
and then we obtain (21). Finally, apply x = x
k
to (23), which yields
φ
k
(x
k
) = (1 − α
k−1
)
φ
∗
k−1
+
γ
k−1
2
kx
k
− v
k−1
k
2
+ α
k−1
F (x
k
) = φ
∗
k
+
γ
k
2
kx
k
− v
k
k
2
.
Consequently,
φ
∗
k
= (1 − α
k−1
)φ
∗
k−1
+ α
k−1
F (x
k
) + (1 − α
k−1
)
γ
k−1
2
kx
k
− v
k−1
k
2
−
γ
k
2
kx
k
− v
k
k
2
(24)
Using the expression of v
k
from (21), we have
v
k
− x
k
=
1
γ
k
((1 − α
k−1
)γ
k−1
(v
k−1
− x
k
) − α
k−1
κ(y
k−1
− x
k
)) .
Therefore
γ
k
2
kx
k
− v
k
k
2
=
(1 − α
k−1
)
2
γ
2
k−1
2γ
k
kx
k
− v
k−1
k
2
−
(1 − α
k−1
)α
k−1
γ
k−1
γ
k
hv
k−1
− x
k
, κ(y
k−1
− x
k
)i +
α
2
k−1
2γ
k
kκ(y
k−1
− x
k
)k
2
.
It remains to plug this relation into (24), use once (20), and we obtain the formula (22) for φ
∗
k
.
We may now start analyzing the errors ε
k
to control how far is the sequence (φ
k
)
k≥0
from an exact
estimate sequence. For that, we need to understand the effect of replacing x
∗
k
by x
k
in the lower
bound (19). The following lemma will be useful for that purpose.
Lemma A.7 (Controlling the Approximate Lower Bound of F ).
If G
k
(x
k
) − G
k
(x
∗
k
) ≤ ε
k
, then for all x in R
p
,
F (x) ≥ F (x
k
) + hκ(y
k−1
−x
k
), x −x
k
i+
µ
2
kx −x
k
k
2
+ (κ + µ)hx
k
−x
∗
k
, x − x
k
i− ε
k
. (25)
Proof. By strong convexity, for all x in R
p
,
G
k
(x) ≥ G
∗
k
+
κ + µ
2
kx − x
∗
k
k
2
,
12

where G
∗
k
is the minimum value of G
k
. Replacing G
k
by its definition (5) gives
F (x) ≥ G
∗
k
+
κ + µ
2
kx − x
∗
k
k
2
−
κ
2
kx − y
k−1
k
2
= G
k
(x
k
) + (G
∗
k
− G
k
(x
k
)) +
κ + µ
2
kx − x
∗
k
k
2
−
κ
2
kx − y
k−1
k
2
≥ G
k
(x
k
) − ε
k
+
κ + µ
2
k(x − x
k
) + (x
k
− x
∗
k
)k
2
−
κ
2
kx − y
k−1
k
2
≥ G
k
(x
k
) − ε
k
+
κ + µ
2
kx − x
k
k
2
−
κ
2
kx − y
k−1
k
2
+ (κ + µ)hx
k
− x
∗
k
, x − x
k
i.
We conclude by noting that
G
k
(x
k
)+
κ
2
kx − x
k
k
2
−
κ
2
kx − y
k−1
k
2
=F (x
k
)+
κ
2
kx
k
− y
k−1
k
2
+
κ
2
kx − x
k
k
2
−
κ
2
kx − y
k−1
k
2
= F (x
k
) + hκ(y
k−1
− x
k
), x − x
k
i.
We can now show that Algorithm 1 generates iterates (x
k
)
k≥0
that approximately satisfy the condi-
tion of Lemma A.2 from Nesterov [17].
Lemma A.8 (Relation between (φ
k
)
k≥0
and Algorithm 1).
Let φ
k
be the estimate sequence constructed above. Then, Algorithm 1 generates iterates (x
k
)
k≥0
such that
F (x
k
) ≤ φ
∗
k
+ ξ
k
,
where the sequence (ξ
k
)
k≥0
is defined by ξ
0
= 0 and
ξ
k
= (1 − α
k−1
)(ξ
k−1
+ ε
k
− (κ + µ)hx
k
− x
∗
k
, x
k−1
− x
k
i).
Proof. We proceed by induction. For k = 0, φ
∗
0
= F (x
0
) and ξ
0
= 0.
Assume now that F (x
k−1
) ≤ φ
∗
k−1
+ ξ
k−1
. Then,
φ
∗
k−1
≥ F (x
k−1
) − ξ
k−1
≥ F (x
k
) + hκ(y
k−1
− x
k
), x
k−1
− x
k
i + (κ + µ)hx
k
− x
∗
k
, x
k−1
− x
k
i − ε
k
− ξ
k−1
= F (x
k
) + hκ(y
k−1
− x
k
), x
k−1
− x
k
i − ξ
k
/(1 − α
k−1
),
where the second inequality is due to (25). By Lemma A.6, we now have,
φ
∗
k
= (1 − α
k−1
)φ
∗
k−1
+ α
k−1
F (x
k
) −
α
2
k−1
2γ
k
kκ(y
k−1
− x
k
)k
2
+
α
k−1
(1 − α
k−1
)γ
k−1
γ
k
µ
2
kx
k
− v
k−1
k
2
+ hκ(y
k−1
− x
k
), v
k−1
− x
k
i
≥ (1 − α
k−1
) (F (x
k
) + hκ(y
k−1
− x
k
), x
k−1
− x
k
i) − ξ
k
+ α
k−1
F (x
k
)
−
α
2
k−1
2γ
k
kκ(y
k−1
− x
k
)k
2
+
α
k−1
(1 − α
k−1
)γ
k−1
γ
k
hκ(y
k−1
− x
k
), v
k−1
− x
k
i.
= F (x
k
) + (1 − α
k−1
)hκ(y
k−1
− x
k
), x
k−1
− x
k
+
α
k−1
γ
k−1
γ
k
(v
k−1
− x
k
)i
−
α
2
k−1
2γ
k
kκ(y
k−1
− x
k
)k
2
− ξ
k
= F (x
k
) + (1 − α
k−1
)hκ(y
k−1
− x
k
), x
k−1
− y
k−1
+
α
k−1
γ
k−1
γ
k
(v
k−1
− y
k−1
)i
+
1 −
(κ + 2µ)α
2
k−1
2γ
k
κk(y
k−1
− x
k
)k
2
− ξ
k
.
We now need to show that the choice of the sequences (α
k
)
k≥0
and (y
k
)
k≥0
will cancel all the terms
involving y
k−1
− x
k
. In other words, we want to show that
x
k−1
− y
k−1
+
α
k−1
γ
k−1
γ
k
(v
k−1
− y
k−1
) = 0, (26)
13

and we want to show that
1 − (κ + µ)
α
2
k−1
γ
k
= 0, (27)
which will be sufficient to conclude that φ
∗
k
+ ξ
k
≥ F (x
k
). The relation (27) can be obtained from
the definition of α
k
in (6) and the form of γ
k
given in (20). We have indeed from (6) that
(κ + µ)α
2
k
= (1 − α
k
)(κ + µ)α
2
k−1
+ α
k
µ.
Then, the quantity (κ + µ)α
2
k
follows the same recursion as γ
k+1
in (20). Moreover, we have
γ
1
= (1 − α
0
)γ
0
+ µα
0
= (κ + µ)α
2
0
,
from the definition of γ
0
in (17). We can then conclude by induction that γ
k+1
= (κ + µ)α
2
k
for
all k ≥ 0 and (27) is satisfied.
To prove(26), we assume that y
k−1
is chosen such that (26) is satisfied, and show that it is equivalent
to defining y
k
as in (6). By lemma A.6,
v
k
=
1
γ
k
((1 − α
k−1
)γ
k−1
v
k−1
+ α
k−1
µx
k
− α
k−1
κ(y
k−1
− x
k
))
=
1
γ
k
(1 − α
k−1
)
α
k−1
((γ
k
+ α
k−1
γ
k−1
)y
k−1
− γ
k
x
k−1
) + α
k−1
µx
k
− α
k−1
κ(y
k−1
− x
k
)
=
1
γ
k
(1 − α
k−1
)
α
k−1
((γ
k−1
+ α
k−1
µ)y
k−1
− γ
k
x
k−1
) + α
k−1
(µ + κ)x
k
− α
k−1
κy
k−1
=
1
γ
k
1
α
k−1
(γ
k
− µα
2
k−1
)y
k−1
−
(1 − α
k−1
)
α
k−1
γ
k
x
k−1
+
γ
k
α
k−1
x
k
− α
k−1
κy
k−1
=
1
α
k−1
(x
k
− (1 − α
k−1
)x
k−1
), (28)
As a result, using (26) by replacing k − 1 by k yields
y
k
= x
k
+
α
k−1
(1 − α
k−1
)
α
2
k−1
+ α
k
(x
k
− x
k−1
),
and we obtain the original equivalent definition of (6). This concludes the proof.
With this lemma in hand, we introduce the following proposition, which brings us almost to Theo-
rem A.3, which we want to prove.
Proposition A.9 (Auxiliary Proposition for Theorem A.3).
Let us consider the sequence (λ
k
)
k≥0
defined in (15). Then, the sequence (x
k
)
k≥0
satisfies
1
λ
k
(F (x
k
) − F
∗
+
γ
k
2
kx
∗
− v
k
k
2
) ≤ φ
0
(x
∗
) − F
∗
+
k
X
i=1
ε
i
λ
i
+
k
X
i=1
√
2ε
i
γ
i
λ
i
kx
∗
− v
i
k,
where x
∗
is a minimizer of F and F
∗
its minimum value.
Proof. By the definition of the function φ
k
, we have
φ
k
(x
∗
) = (1 − α
k−1
)φ
k−1
(x
∗
) + α
k−1
[F (x
k
) + hκ(y
k−1
− x
k
), x
∗
− x
k
i +
µ
2
kx
∗
− x
k
k
2
]
≤ (1 − α
k−1
)φ
k−1
(x
∗
) + α
k−1
[F (x
∗
) + ε
k
− (κ + µ)hx
k
− x
∗
k
, x
∗
− x
k
i],
where the inequality comes from (25). Therefore, by using the definition of ξ
k
in Lemma A.8,
φ
k
(x
∗
) + ξ
k
− F
∗
≤ (1 − α
k−1
)(φ
k−1
(x
∗
) + ξ
k−1
− F
∗
) + ε
k
− (κ + µ)hx
k
− x
∗
k
, (1 − α
k−1
)x
k−1
+ α
k−1
x
∗
− x
k
i
= (1 − α
k−1
)(φ
k−1
(x
∗
) + ξ
k−1
− F
∗
) + ε
k
− α
k−1
(κ + µ)hx
k
− x
∗
k
, x
∗
− v
k
i
≤ (1 − α
k−1
)(φ
k−1
(x
∗
) + ξ
k−1
− F
∗
) + ε
k
+ α
k−1
(κ + µ)kx
k
− x
∗
k
kkx
∗
− v
k
k
≤ (1 − α
k−1
)(φ
k−1
(x
∗
) + ξ
k−1
− F
∗
) + ε
k
+ α
k−1
p
2(κ + µ)ε
k
kx
∗
− v
k
k
= (1 − α
k−1
)(φ
k−1
(x
∗
) + ξ
k−1
− F
∗
) + ε
k
+
p
2ε
k
γ
k
kx
∗
− v
k
k,
14

where the first equality uses the relation (28), the last inequality comes from the strong convex-
ity relation ε
k
≥ G
k
(x
k
) − G
k
(x
∗
k
) ≥ (1/2)(κ + µ)kx
∗
k
− x
k
k
2
, and the last equality uses the
relation γ
k
= (κ + µ)α
2
k−1
.
Dividing both sides by λ
k
yields
1
λ
k
(φ
k
(x
∗
) + ξ
k
− F
∗
) ≤
1
λ
k−1
(φ
k−1
(x
∗
) + ξ
k−1
− F
∗
) +
ε
k
λ
k
+
√
2ε
k
γ
k
λ
k
kx
∗
− v
k
k.
A simple recurrence gives,
1
λ
k
(φ
k
(x
∗
) + ξ
k
− F
∗
) ≤ φ
0
(x
∗
) − F
∗
+
k
X
i=1
ε
i
λ
i
+
k
X
i=1
√
2ε
i
γ
i
λ
i
kx
∗
− v
i
k.
Finally, by lemmas A.6 and A.8,
φ
k
(x
∗
) + ξ
k
− F
∗
=
γ
k
2
kx
∗
− v
k
k
2
+ φ
∗
k
+ ξ
k
− F
∗
≥
γ
k
2
kx
∗
− v
k
k
2
+ F (x
k
) − F
∗
.
As a result,
1
λ
k
(F (x
k
) − F
∗
+
γ
k
2
kx
∗
− v
k
k
2
) ≤ φ
0
(x
∗
) − F
∗
+
k
X
i=1
ε
i
λ
i
+
k
X
i=1
√
2ε
i
γ
i
λ
i
kx
∗
− v
i
k. (29)
To control the error term on the right and finish the proof of Theorem A.3, we are going to bor-
row some methodology used to analyze the convergence of inexact proximal gradient algorithms
from [23], and use an extension of a lemma presented in [23] to bound the value of kv
i
−x
∗
k. This
lemma is presented below.
Lemma A.10 (Simple Lemma on Non-Negative Sequences).
Assume that the nonnegative sequences (u
k
)
k≥0
and (a
k
)
k≥0
satisfy the following recursion for all
k ≥ 0:
u
2
k
≤ S
k
+
k
X
i=1
a
i
u
i
, (30)
where (S
k
)
k≥0
is an increasing sequence such that S
0
≥ u
2
0
. Then,
u
k
≤
1
2
k
X
i=1
a
i
+
v
u
u
t
1
2
k
X
i=1
a
i
2
+ S
k
. (31)
Moreover,
S
k
+
k
X
i=1
a
i
u
i
≤
p
S
k
+
k
X
i=1
a
i
!
2
.
Proof. The first part—that is, Eq. (31)—is exactly Lemma 1 from [23]. The proof is in their ap-
pendix. Then, by calling b
k
the right-hand side of (31), we have that for all k ≥ 1, u
k
≤ b
k
.
Furthermore (b
k
)
k≥0
is increasing and we have
S
k
+
k
X
i=1
a
i
u
i
≤ S
k
+
k
X
i=1
a
i
b
i
≤ S
k
+
k
X
i=1
a
i
b
k
= b
2
k
,
and using the inequality
√
x + y ≤
√
x +
√
y, we have
b
k
=
1
2
k
X
i=1
a
i
+
v
u
u
t
1
2
k
X
i=1
a
i
2
+ S
k
≤
1
2
k
X
i=1
a
i
+
v
u
u
t
1
2
k
X
i=1
a
i
2
+
p
S
k
=
p
S
k
+
k
X
i=1
a
i
.
As a result,
S
k
+
k
X
i=1
a
i
u
i
≤ b
2
k
≤
p
S
k
+
k
X
i=1
a
i
!
2
.
15

We are now in shape to conclude the proof of Theorem A.3. We apply the previous lemma to (29):
1
λ
k
γ
k
2
kx
∗
− v
k
k
2
+ F (x
k
) − F
∗
≤ φ
0
(x
∗
) − F
∗
+
k
X
i=1
ε
i
λ
i
+
k
X
i=1
√
2ε
i
γ
i
λ
i
kx
∗
− v
i
k.
Since F (x
k
) − F
∗
≥ 0, we have
γ
k
2λ
k
kx
∗
− v
k
k
2
|
{z }
u
2
k
≤ φ
0
(x
∗
) − F
∗
+
k
X
i=1
ε
i
λ
i
|
{z }
S
k
+
k
X
i=1
√
2ε
i
γ
i
λ
i
kx
∗
− v
i
k
|
{z }
a
i
u
i
,
with
u
i
=
r
γ
i
2λ
i
kx
∗
− v
i
k and a
i
= 2
r
ε
i
λ
i
and S
k
= φ
0
(x
∗
) − F
∗
+
k
X
i=1
ε
i
λ
i
.
Then by Lemma A.10, we have
F (x
k
) − F
∗
≤ λ
k
S
k
+
k
X
i=1
a
i
u
i
!
≤ λ
k
p
S
k
+
k
X
i=1
a
i
!
2
= λ
k
p
S
k
+ 2
k
X
i=1
r
ε
i
λ
i
!
2
,
which is the desired result.
B Proofs of the Main Theorems and Propositions
B.1 Proof of Theorem 3.1
Proof. We simply use Theorem A.3 and specialize it to the choice of parameters. The initialization
α
0
=
√
q leads to a particularly simple form of the algorithm, where α
k
=
√
q for all k ≥ 0.
Therefore, the sequence (λ
k
)
k≥0
from Theorem A.3 is also simple. For all k ≥ 0, we indeed have
λ
k
= (1 −
√
q)
k
. To upper-bound the quantity S
k
from Theorem A.3, we now remark that γ
0
= µ
and thus, by strong convexity of F ,
F (x
0
) +
γ
0
2
kx
0
− x
∗
k
2
− F
∗
≤ 2(F (x
0
) − F
∗
).
Therefore,
p
S
k
+ 2
k
X
i=1
r
ε
i
λ
i
=
v
u
u
t
F (x
0
) +
γ
0
2
kx
0
− x
∗
k
2
− F
∗
+
k
X
i=1
ε
i
λ
i
+ 2
k
X
i=1
r
ε
i
λ
i
≤
r
F (x
0
) +
γ
0
2
kx
0
− x
∗
k
2
− F
∗
+ 3
k
X
i=1
r
ε
i
λ
i
≤
p
2(F (x
0
) − F
∗
) + 3
k
X
i=1
r
ε
i
λ
i
=
p
2(F (x
0
) − F
∗
)
1 +
k
X
i=1
s
1 − ρ
1 −
√
q
!
|
{z }
η
i
=
p
2(F (x
0
) − F
∗
)
η
k+1
− 1
η −1
≤
p
2(F (x
0
) − F
∗
)
η
k+1
η − 1
.
16

Therefore, Theorem A.3 combined with the previous inequality gives us
F (x
k
) − F
∗
≤ 2λ
k
(F (x
0
) − F
∗
)
η
k+1
η − 1
2
= 2
η
η −1
2
(1 − ρ)
k
(F (x
0
) − F
∗
)
= 2
√
1 − ρ
√
1 − ρ −
p
1 −
√
q
!
2
(1 − ρ)
k
(F (x
0
) − F
∗
)
= 2
1
√
1 − ρ −
p
1 −
√
q
!
2
(1 − ρ)
k+1
(F (x
0
) − F
∗
).
Since
√
1 − x +
x
2
is decreasing in [0, 1], we have
√
1 − ρ +
ρ
2
≥
p
1 −
√
q +
√
q
2
. Consequently,
F (x
k
) − F
∗
≤
8
(
√
q −ρ)
2
(1 − ρ)
k+1
(F (x
0
) − F
∗
).
B.2 Proof of Proposition 3.2
To control the number of calls of M, we need to upper bound G
k
(x
k−1
) − G
∗
k
which is given by
the following lemma:
Lemma B.1 (Relation between G
k
(x
k−1
) and ε
k−1
).
Let (x
k
)
k≥0
and (y
k
)
k≥0
be generated by Algorithm 1. Remember that by definition of x
k−1
,
G
k−1
(x
k−1
) − G
∗
k−1
≤ ε
k−1
.
Then, we have
G
k
(x
k−1
) − G
∗
k
≤ 2ε
k−1
+
κ
2
κ + µ
ky
k−1
− y
k−2
k
2
. (32)
Proof. We first remark that for any x, y in R
p
, we have
G
k
(x) − G
k−1
(x) = G
k
(y) − G
k−1
(y) + κhy − x, y
k−1
− y
k−2
i, ∀k ≥ 2,
which can be shown by using the respective definitions of G
k
and G
k−1
and manipulate the quadratic
term resulting from the difference G
k
(x) − G
k−1
(x).
Plugging x = x
k−1
and y = x
∗
k
in the previous relation yields
G
k
(x
k−1
) − G
∗
k
= G
k−1
(x
k−1
) − G
k−1
(x
∗
k
) + κhx
∗
k
− x
k−1
, y
k−1
− y
k−2
i
= G
k−1
(x
k−1
) − G
∗
k−1
+ G
∗
k−1
− G
k−1
(x
∗
k
) + κhx
∗
k
− x
k−1
, y
k−1
− y
k−2
i
≤ ε
k−1
+ G
∗
k−1
− G
k−1
(x
∗
k
) + κhx
∗
k
− x
k−1
, y
k−1
− y
k−2
i
≤ ε
k−1
−
µ + κ
2
kx
∗
k
− x
∗
k−1
k
2
+ κhx
∗
k
− x
k−1
, y
k−1
− y
k−2
i,
(33)
where the last inequality comes from the strong convexity inequality of
G
k−1
(x
∗
k
) ≥ G
∗
k−1
+
µ + κ
2
kx
∗
k
− x
∗
k−1
k
2
.
Moreover, from the inequality hx, yi ≤
1
2
kxk
2
+
1
2
kyk
2
, we also have
κhx
∗
k
− x
∗
k−1
, y
k−1
− y
k−2
i ≤
µ + κ
2
kx
∗
k
− x
∗
k−1
k
2
+
κ
2
2(κ + µ)
ky
k−1
− y
k−2
k
2
, (34)
and
κhx
∗
k−1
− x
k−1
, y
k−1
− y
k−2
i ≤
µ + κ
2
kx
∗
k−1
− x
k−1
k
2
+
κ
2
2(κ + µ)
ky
k−1
− y
k−2
k
2
≤ ε
k−1
+
κ
2
2(κ + µ)
ky
k−1
− y
k−2
k
2
.
(35)
Summing inequalities (33), (34) and (35) gives the desired result.
17

Next, we need to upper-boundthe term ky
k−1
−y
k−2
k
2
, which was also required in the convergence
proof of the accelerated SDCA algorithm [26]. We follow here their methodology.
Lemma B.2 (Control of the term ky
k−1
− y
k−2
k
2
.).
Let us consider the iterates (x
k
)
k≥0
and (y
k
)
k≥0
produced by Algorithm 1, and define
δ
k
= C(1 − ρ)
k+1
(F (x
0
) − F
∗
),
which appears in Theorem 3.1 and which is such that F (x
k
) − F
∗
≤ δ
k
. Then, for any k ≥ 3 ,
ky
k−1
− y
k−2
k
2
≤
72
µ
δ
k−3
.
Proof. We follow here [26]. By definition of y
k
, we have
ky
k−1
− y
k−2
k = kx
k−1
+ β
k−1
(x
k−1
− x
k−2
) − x
k−2
− β
k−2
(x
k−2
− x
k−3
)k
≤ (1 + β
k−1
)kx
k−1
− x
k−2
k + β
k−2
kx
k−2
− x
k−3
k
≤ 3 max {kx
k−1
− x
k−2
k, kx
k−2
− x
k−3
k},
where β
k
is defined in (6). The last inequality was due to the fact that β
k
≤ 1. Indeed, the specific
choice of α
0
=
√
q in Theorem A.3 leads to β
k
=
√
q−q
√
q+q
≤ 1 for all k. Note, however, that this
relation β
k
≤ 1 is true regardless of the choice of α
0
:
β
2
k
=
α
k−1
− α
2
k−1
2
α
2
k−1
+ α
k
2
=
α
2
k−1
+ α
4
k−1
− 2α
3
k−1
α
2
k
+ 2α
k
α
2
k−1
+ α
4
k−1
=
α
2
k−1
+ α
4
k−1
− 2α
3
k−1
α
2
k−1
+ α
4
k−1
+ qα
k
+ α
k
α
2
k−1
≤ 1,
where the last equality uses the relation α
2
k
+α
k
α
2
k−1
= α
2
k−1
+qα
k
from Algorithm 1. To conclude
the lemma, we notice that by triangle inequality
kx
k
− x
k−1
k ≤ kx
k
− x
∗
k + kx
k−1
− x
∗
k,
and by strong convexity of F
µ
2
kx
k
− x
∗
k
2
≤ F (x
k
) − F (x
∗
) ≤ δ
k
.
As a result,
ky
k−1
− y
k−2
k
2
≤ 9 max
kx
k−1
− x
k−2
k
2
, kx
k−2
− x
k−3
k
2
≤ 36 ma x
kx
k−1
− x
∗
k
2
, kx
k−2
− x
∗
k
2
, kx
k−3
− x
∗
k
2
≤
72
µ
δ
k−3
.
We are now in shape to conclude the proof of Proposition 3.2.
By Proposition B.1 and lemma B.2, we have for all k ≥ 3,
G
k
(x
k−1
) − G
∗
k
≤ 2ε
k−1
+
κ
2
κ + µ
72
µ
δ
k−3
≤ 2ε
k−1
+
72κ
µ
δ
k−3
.
Let (z
t
)
t≥0
be the sequence of using M to solve G
k
with initialization z
0
= x
k−1
. By assump-
tion (8), we have
G
k
(z
t
) − G
∗
k
≤ A (1 − τ
M
)
t
(G
k
(x
k−1
) − G
∗
k
) ≤ A e
−τ
M
t
(G
k
(x
k−1
) − G
∗
k
).
The number of iterations T
M
of M to guarantee an accuracy of ε
k
needs to satisfy
A e
−τ
M
T
M
(G
k
(x
k−1
) − G
∗
k
) ≤ ε
k
,
which gives
T
M
=
1
τ
M
log
A(G
k
(x
k−1
) − G
∗
k
)
ε
k
. (36)
18

Then, it remains to upper-bound
G
k
(x
k−1
) − G
∗
k
ε
k
≤
2ε
k−1
+
72κ
µ
δ
k−3
ε
k
=
2(1 − ρ) +
72κ
µ
·
9C
2
(1 − ρ)
2
=
2
1 − ρ
+
2592κ
µ(1 − ρ)
2
(
√
q − ρ)
2
.
Let us denote R the right-hand side. We remark that this upper bound holds for k ≥ 3. We now
consider the cases k = 1 and k = 2.
When k = 1, G
1
(x) = F (x) +
κ
2
kx −y
0
k
2
. Note that x
0
= y
0
, then G
1
(x
0
) = F (x
0
). As a result,
G
1
(x
0
) − G
∗
1
= F (x
0
) − F (x
∗
1
) −
κ
2
kx
∗
1
− y
0
k
2
≤ F (x
0
) − F (x
∗
1
) ≤ F (x
0
) − F
∗
.
Therefore,
G
1
(x
0
) − G
∗
1
ε
1
≤
F (x
0
) − F
∗
ε
1
=
9
2(1 − ρ)
≤ R.
When k = 2, we remark that y
1
− y
0
= (1 + β
1
)(x
1
− x
0
). Then, by following similar steps as in
the proof of Lemma B.2, we have
ky
1
− y
0
k
2
≤ 4kx
1
− x
0
k
2
≤
32δ
0
µ
,
which is smaller than
72δ
−1
µ
. Therefore, the previous steps from the case k ≥ 3 apply and
G
2
(x
1
)−G
∗
2
ε
2
≤ R. Thus, for any k ≥ 1,
T
M
≤
log (AR)
τ
M
, (37)
which concludes the proof.
B.3 Proof of Theorem 3.3.
We will again Theorem A.3 and specialize it to the choice of parameters. To apply it, the following
Lemma will be useful to control the growth of (λ
k
)
k≥0
.
Lemma B.3 (Growth of the Sequence (λ
k
)
k≥0
).
Let (λ
k
)
k≥0
be the sequence defined in (15) where (α
k
)
k≥0
is produced by Algorithm 1 with α
0
=
√
5−1
2
and µ = 0. Then, we have the following bounds for all k ≥ 0,
4
(k + 2)
2
≥ λ
k
≥
2
(k + 2)
2
.
Proof. Note that by definition of α
k
, we have for all k ≥ 1,
α
2
k
= (1 − α
k
)α
2
k−1
=
k
Y
i=1
(1 − α
i
)α
2
0
= λ
k+1
α
2
0
1 − α
0
= λ
k+1
.
With the choice of α
0
, the quantity γ
0
defined in (17) is equal to κ. By Lemma A.4, we have
λ
k
≤
4
(k+2)
2
for all k ≥ 0 and thus α
k
≤
2
k+3
for all k ≥ 1 (it is also easy to check numerically
that this is also true for k = 0 since
√
5−1
2
≈ 0.62 ≤
2
3
). We now have all we need to conclude the
lemma:
λ
k
=
k−1
Y
i=0
(1 − α
i
) ≥
k−1
Y
i=0
1 −
2
i + 3
=
2
(k + 2)(k + 1)
≥
2
(k + 2)
2
.
19
With this lemma in hand, we may now proceed and apply Theorem A.3. We have remarked in the
proof of the previous lemma that γ
0
= κ. Then,
p
S
k
+ 2
k
X
i=1
r
ε
i
λ
i
=
v
u
u
t
F (x
0
) − F
∗
+
κ
2
kx
0
− x
∗
k
2
+
k
X
i=1
ε
i
λ
i
+ 2
k
X
i=1
r
ε
i
λ
i
≤
r
F (x
0
) − F
∗
+
κ
2
kx
0
− x
∗
k
2
+ 3
k
X
i=1
r
ε
i
λ
i
≤
r
κ
2
kx
0
− x
∗
k
2
+
p
F (x
0
) − F
∗
1 +
k
X
i=1
1
(i + 2)
1+η/2
!
,
where the last inequality uses Lemma B.3 to upper-bound the ratio ε
i
/λ
i
. Moreover,
k
X
i=1
1
(i + 2)
1+η/2
≤
∞
X
i=2
1
i
1+η/2
≤
Z
∞
1
1
x
1+η/2
dx =
2
η
.
Therefore, by (16) from Theorem A.3,
F (x
k
) − F
∗
≤ λ
k
p
S
k
+ 2
k
X
i=1
r
ε
i
λ
i
!
2
≤
4
(k + 2)
2
p
F (x
0
) − F
∗
1 +
2
η
+
r
κ
2
kx
0
− x
∗
k
2
2
≤
8
(k + 2)
2
1 +
2
η
2
(F (x
0
) − F
∗
) +
κ
2
kx
0
− x
∗
k
2
!
.
The last inequality uses (a + b)
2
≤ 2(a
2
+ b
2
).
B.4 Proof of Proposition 3.4
When µ = 0, we remark that Proposition B.1 still holds but Lemma B.2 does not. The main difficulty
is thus to find another way to control the quantity ky
k−1
− y
k−2
k.
Since F (x
k
) − F
∗
is bounded by Theorem 3.3, we may use the bounded level set assumptions to
ensure that there exists B > 0 such that kx
k
− x
∗
k ≤ B for any k ≥ 0 where x
∗
is a minimizer
of F . We can now follow similar steps as in the proof of Lemma B.2, and show that
ky
k−1
− y
k−2
k
2
≤ 36B
2
.
Then by Proposition B.1,
G
k
(x
k−1
) − G
∗
k
≤ 2ε
k−1
+ 36κB
2
.
Since κ > 0, G
k
is strongly convex, then using the same argument as in the strongly convex case,
the number of calls for M is given by
1
τ
M
log
A(G
k
(x
k−1
) − G
∗
k
)
ε
k
. (38)
Again, we need to upper bound it
G
k
(x
k−1
) − G
∗
k
ε
k
≤
2ε
k−1
+ 36κB
2
ε
k
=
2(k + 1)
4+η
(k + 2)
4+η
+
162κB
2
(k + 2)
4+η
(F (x
0
) − F
∗
)
.
The right hand side is upper-bounded by O((k + 2)
4+η
). Plugging this relation into (38) gives the
desired result.
20

C Derivation of Global Convergence Rates
We give here a generic “template” for computing the optimal choice of κ to accelerate a given
algorithm M, and therefore compute the rate of convergence of the accelerated algorithm A.
We assume here that M is a randomized first-order optimization algorithm, i.e. the iterates (x
k
)
generated by M are a sequence of random variables; specialization to a deterministic algorithm is
straightforward. Also, for the sake of simplicity, we shall use simple notations to denote the stopping
time to reach accuracy ε. Definition and notation using filtrations, σ-algebras, etc. are unnecessary
for our purpose here where the quantity of interest has a clear interpretation.
Assume that algorithm M enjoys a linear rate of convergence, in expectation. There exists con-
stants C
M,F
and τ
M,F
such that the sequence of iterates (x
k
)
k≥0
for minimizing a strongly-convex
objective F satisfies
E [F (x
k
) − F
∗
] ≤ C
M,F
(1 − τ
M,F
)
k
. (39)
Define the random variable T
M,F
(ε) (stopping time) corresponding to the minimum number of
iterations to guarantee an accuracy ε in the course of running M
T
M,F
(ε) := inf {k ≥ 1, F (x
k
) − F
∗
≤ ε} (40)
Then, an upper bound on the expectation is provided by the following lemma.
Lemma C.1 (Upper Bound on the expectation of T
M,F
(ε)).
Let M be an optimization method with the expected rate of convergence (39). Then,
E[T
M
(ε)] ≤
1
τ
M
log
2C
M
τ
M
· ε
+ 1 =
˜
O
1
τ
M
log
C
M
ε
, (41)
where we have dropped the dependency in F to simplify the notation.
Proof. We abbreviate τ
M
by τ. Set
T
0
=
1
τ
log
1
1 − e
−τ
C
M
ε
.
For any k ≥ 0, we have
E[F (x
k
) − F
∗
] ≤ C
M
(1 − τ)
k
≤ C
M
e
−kτ
.
By Markov’s inequality,
P[F (x
k
) − F
∗
> ε] = P[T
M
(ε) > k] ≤
E[F (x
k
) − F
∗
]
ε
≤
C
M
e
−kτ
ε
. (42)
Together with the fact P ≤ 1 and k ≥ 0. We have
P[T
M
(ε) ≥ k + 1] ≤ min
C
M
ε
e
−kτ
, 1
.
Therefore,
E[T
M
(ε)] =
∞
X
k=1
P[T
M
(ε) ≥ k] =
T
0
X
k=1
P[T
M
(ε) ≥ k] +
∞
X
k=T
0
+1
P[T
M
(ε) ≥ k]
≤ T
0
+
∞
X
k=T
0
C
M
ε
e
−kτ
= T
0
+
C
M
ε
e
−T
0
τ
∞
X
k=0
e
−kτ
= T
0
+
C
M
ε
e
−τ T
0
1 − e
−τ
= T
0
+ 1.
As simple calculation shows that for any τ ∈ (0, 1),
τ
2
≤ 1 − e
−τ
and then
E[T
M
(ε)] ≤ T
0
+ 1 =
1
τ
log
1
1 − e
−τ
C
M
ε
+ 1 ≤
1
τ
log
2C
M
τε
+ 1.
21

Note that the previous lemma mirrors Eq. (36-37) in the proof of Prop. 3.1 in Appendix B. For all
optimization methods of interest, the rate τ
M,G
k
is independentof k and varies with the parameter κ.
We may now compute the iteration-complexity(in expectation) of the accelerated algorithm A—that
is, for a given ε, the expected total number of iterations performed by the method M. Let us now
fix ε > 0. Calculating the iteration-complexity decomposes into three steps:
1. Find κ that maximizes the ratio τ
M,G
k
/
√
µ + κ for algorithm M when F is µ-strongly
convex. In the non-strongly convex case, we suggest maximizing instead the ratio
τ
M,G
k
/
√
L + κ. Note that the choice of κ is less critical for non-strongly convex prob-
lems since it only affects multiplicative constants in the global convergence rate.
2. Compute the upper-bound of the number of outer iterations k
out
using Theorem 3.1 (for the
strongly convex case), or Theorem 3.3 (for the non-strongly convex case), by replacing κ
by the optimal value found in step 1.
3. Compute the upper-bound of the expected number of inner iterations
max
k=1,...,k
out
E[T
M,G
k
(ε
k
)] ≤ k
in
,
by replacing the appropriate quantities in Eq. 41 for algorithm M; for that purpose, the
proofs of Propositions 3.2 of 3.4 my be used to upper-bound the ratio C
M,G
k
/ε
k
, or another
dedicated analysis for M may be required if the constant C
M,G
k
does not have the required
form A(G
k
(z
0
) − G
∗
k
) in (8).
Then, the iteration-complexity (in expectation) denoted Comp. is given by
Comp ≤ k
in
× k
out
. (43)
D A Proximal MISO/Finito Algorithm
In this section, we present the algorithm MISO/Finito, and show how to extend it in two ways. First,
we propose a proximal version to deal with composite optimization problems, and we analyze its
rate of convergence. Second, we show how to remove a large sample condition n ≥ 2L/µ, which
was necessary for the convergence of the algorithm. The resulting algorithm is a variant of proximal
SDCA [25] with a different stepsize and a stopping criterion that does not use duality.
D.1 The Original Algorithm MISO/Finito
MISO/Finito was proposed in [14] and [7] for solving the following smooth unconstrained convex
minimization problem
min
x∈R
p
(
f(x) ,
1
n
n
X
i=1
f
i
(x)
)
, (44)
where each f
i
is differentiable with L-Lipschitz continuous derivatives and µ-strongly convex. At
iteration k, the algorithm updates a list of lower bounds d
k
i
of the functions f
i
, by randomly picking
up one index i
k
among {1, ··· , n} and performing the following update
d
k
i
(x) =
f
i
(x
k−1
) + h∇f
i
(x
k−1
), x − x
k−1
i +
µ
2
kx − x
k−1
k
2
if i = i
k
d
k−1
i
(x) otherwise
,
which is a lower bound of f
i
because of the µ-strong convexity of f
i
. Equivalently, one may perform
the following updates
z
k
i
=
x
k−1
−
1
µ
∇f
i
(x
k−1
) if i = i
k
z
k−1
i
otherwise
,
and all functions d
k
i
have the form
d
k
i
(x) = c
k
i
+
µ
2
kx − z
k
i
k
2
,
where c
k
i
is a constant. Then, MISO/Finito performs the following minimization to produce the
iterate (x
k
):
x
k
= arg min
x∈R
p
1
n
n
X
i=1
d
k
i
(x) =
1
n
n
X
i=1
z
k
i
,
22

which is equivalent to
x
k
← x
k−1
−
1
n
z
k
i
k
− z
k−1
i
k
.
In many machine learning problems, it is worth remarking that each function f
i
(x) has the spe-
cific form f
i
(x) = l
i
(hx, w
i
i) +
µ
2
kxk
2
. In such cases, the vectors z
k
i
can be obtained by storing
only O(n) scalars.
3
The main convergence result of [14] is that the procedure above converges with
a linear rate of convergence of the form (3), with τ
MISO
= 1/3n (also refined in 1/2n in [7]), when
the large sample size constraint n ≥ 2L/µ is satisfied.
Removing this condition and extending MISO to the composite optimization problem (1) is the
purpose of the next section.
D.2 Proximal MISO
We now consider the composite optimization problem below,
min
x∈R
p
(
F (x) =
1
n
n
X
i=1
f
i
(x) + ψ(x)
)
,
where the functions f
i
are differentiable with L-Lipschitz derivatives and µ-strongly convex. As in
typical composite optimization problems, ψ is convex but not necessarily differentiable. We assume
that the proximal operator of ψ can be computed easily. The algorithm needs to be initialized with
some lower bounds for the functions f
i
:
f
i
(x) ≥
µ
2
kx − z
0
i
k
2
+ c
0
i
, (A1)
which are guaranteed to exist due to the µ-strong convexity of f
i
. For typical machine learning
applications, such initialization is easy. For example, logistic regression with ℓ
2
-regularization sat-
isfies (A1) with z
0
i
= 0 and c
0
i
= 0. Then, the MISO-Prox scheme is given in Algorithm 2. Note
that if no simple initialization is available, we may consider any initial estimate ¯z
0
in R
p
and define
z
0
i
= ¯z
0
− (1/µ)∇f
i
(¯z
0
), which requires performing one pass over the data.
Then, we remark that under the large sample size condition n ≥ 2L/µ, we have δ = 1 and the
update of the quantities z
k
i
in (45) is the same as in the original MISO/Finito algorithm. As we will
see in the convergence analysis, the choice of δ ensures convergence of the algorithm even in the
small sample size regime n < 2L/µ.
Relation with Proximal SDCA [25]. The algorithm MISO-Prox is almost identical to variant 5
of proximal SDCA [25], which performs the same updates with δ = µn/(L + µn) instead of δ =
min(1,
µn
2(L−µ)
). It is however not clear that MISO-Prox actually performs dual ascent steps in the
sense of SDCA since the proof of convergence of SDCA cannot be directly modified to use the
stepsize of proximal MISO and furthermore, the convergence proof of MISO-Prox does not use the
concept of duality. Another difference lies in the optimality certificate of the algorithms. Whereas
Proximal-SDCA provides a certificate in terms of linear convergence of a duality gap based on
Fenchel duality, Proximal-SDCA ensures linear convergence of a gap that relies on strong convexity
but not on the Fenchel dual (at least explicitly).
Optimality Certificate and Stopping Criterion. Similar to the original MISO algorithm, Prox-
imal MISO maintains a list (d
k
i
) of lower bounds of the functions f
i
, which are updated in the
following fashion
d
k
i
(x) =
(1 − δ)d
k−1
i
(x)+ δ
f
i
(x
k−1
)+h∇f
i
(x
k−1
), x − x
k−1
i+
µ
2
kx − x
k−1
k
2
if i = i
k
d
k−1
i
(x) otherwise
(46)
3
Note that even though we call this algorithm MISO (or Finito), it was called MISOµ in [14], whereas
“MISO” was originally referring to an incremental majorization-minimization procedure that uses upper bounds
of the functions f
i
instead of lower bounds, which is appropriate for non-convex optimization problems.
23
Algorithm 2 MISO-Prox: an improved MISO algorithm with proximal support.
input (z
0
i
)
i=1,...,n
such that (A1) holds; N (number of iterations);
1: initialize ¯z
0
=
1
n
P
n
i=1
z
0
i
and x
0
= prox
ψ/µ
[¯z
0
];
2: define δ = min
1,
µn
2(L−µ)
;
3: for k = 1, . . . , N do
4: randomly pick up an index i
k
in {1, . . . , n};
5: update
z
k
i
=
(
(1 − δ)z
k−1
i
+ δ
x
k−1
−
1
µ
∇f
i
(x
k−1
)
if i = i
k
z
k−1
i
otherwise
¯z
k
= ¯z
k−1
−
1
n
z
k
i
k
− z
k−1
i
k
=
1
n
n
X
i=1
z
k
i
x
k
= prox
ψ/µ
[¯z
k
].
(45)
6: end for
output x
N
(final estimate).
Then, the following function is a lower bound of the objective F :
D
k
(x) =
1
n
n
X
i=1
d
k
i
(x) + ψ(x), (47)
and the update (45) can be shown to exactly minimize D
k
. As a lower bound of F , we have
that D
k
(x
k
) ≤ F
∗
and thus
F (x
k
) − F
∗
≤ F (x
k
) − D
k
(x
k
).
The quantity F (x
k
) − D
k
(x
k
) can then be interpreted as an optimality gap, and the analysis below
will show that it converges linearly to zero. In practice, it also provides a convenient stopping
criterion, which yields Algorithm 3.
Algorithm 3 MISO-Prox with stopping criterion.
input (z
0
i
, c
0
i
)
i=1,...,n
such that (A1) holds; ε (target accuracy);
1: initialize ¯z
0
=
1
n
P
n
i=1
z
0
i
and c
′0
i
= c
0
i
+
µ
2
k¯z
0
k
2
for all i in {1, . . . , n} and x
0
= prox
ψ/µ
[¯z
0
];
2: Define δ = min
1,
µn
2(L−µ)
and k = 0;
3: while
1
n
P
n
i=1
f
i
(x
k
) − c
′k
i
+ µh¯z
k
, x
k
i −
µ
2
kx
k
k
2
> ε do
4: for l = 1, . . . , n do
5: k ← k + 1;
6: randomly pick up an index i
k
in {1, . . . , n};
7: perform the update (45);
8: update
c
′k
i
=
(1 − δ)c
′k−1
i
+ δ
f
i
(x
k−1
) − h∇f
i
(x
k−1
), x
k−1
i +
µ
2
kx
k−1
k
2
if i = i
k
c
′k−1
i
otherwise
.
(48)
9: end for
10: end while
output x
N
(final estimate such that F (x
N
) − F
∗
≤ ε).
To explain the stopping criterion in Algorithm 3, we remark that the functions d
k
i
are quadratic and
can be written
d
k
i
(x) = c
k
i
+
µ
2
kx − z
k
i
k
2
= c
′k
i
− µhx, z
k
i
i +
µ
2
kxk
2
, (49)
24
where the c
k
i
’s are some constants and c
′k
i
= c
k
i
+
µ
2
kz
k
i
k
2
. Equation (48) shows how to update
recursively these constants c
′k
i
, and finally
D
k
(x
k
) =
1
n
n
X
i=1
c
′k
i
!
− µhx
k
, ¯z
k
i +
µ
2
kx
k
k
2
+ ψ(x
k
),
and
F (x
k
) − D
k
(x
k
) =
1
n
n
X
i=1
f
i
(x
k
) − c
′k
i
!
+ µhx
k
, ¯z
k
i −
µ
2
kx
k
k
2
,
which justifies the stopping criterion. Since computing F(x
k
) requires scanning all the data points,
the criterion is only computed every n iterations.
Convergence Analysis. The convergence of MISO-Prox is guaranteed by Theorem 4.1 from the
main part of paper. Before we prove this theorem, we note that this rate is slightly better than the
one proven in MISO [14], which converges as (1 −
1
3n
)
k
. We start by recalling a classical lemma
that provides useful inequalities. Its proof may be found in [17].
Lemma D.1 (Classical Quadratic Upper and Lower Bounds).
For any function g : R
p
→ R which is µ-strongly convex and differentiable with L-Lipschitz deriva-
tives, we have for all x, y in R
p
,
µ
2
kx − yk
2
≤ g(x) − g(y) + h∇g(y), x − yi ≤
L
2
kx − yk
2
.
To start the proof, we need a sequence of upper and lower bounds involving the functions D
k
and
D
k−1
. The first one is given in the next lemma
Lemma D.2 (Lower Bound on D
k
).
For all k ≥ 1 and x in R
p
,
D
k
(x) ≥ D
k−1
(x) −
δ(L − µ)
2n
kx − x
k−1
k
2
, ∀x ∈ R
p
. (50)
Proof. For any i ∈ {1, . . . , n}, f
i
satisfies the assumptions of Lemma D.1, and we have for all k ≥
0, x in R
p
, and for i = i
k
,
d
k
i
(x) = (1 − δ)d
k−1
i
(x) + δ[f
i
(x
k−1
) + h∇f
i
(x
k−1
), x − x
k−1
i +
µ
2
kx − x
k−1
k
2
]
≥ (1 − δ)d
k−1
i
(x) + δf
i
(x) −
δ(L − µ)
2
kx − x
k−1
k
2
≥ d
k−1
i
(x) −
δ(L − µ)
2
kx − x
k−1
k
2
,
where the definition of d
k
i
is given in (46). The first inequality uses Lemma D.1, and the last
one uses the inequality f
i
≥ d
k−1
i
. From this inequality, we can obtain (50) by simply using
D
k
(x) =
P
n
i=1
d
k
i
(x) + ψ(x) = D
k−1
(x) +
1
n
d
k
i
k
(x) − d
k−1
i
k
(x)
.
Next, we prove the following lemma to compare D
k
and D
k−1
.
Lemma D.3 (Relation between D
k
and D
k−1
).
For all k ≥ 0, for all x and y in R
p
,
D
k
(x) − D
k
(y) = D
k−1
(x) − D
k−1
(y) − µh¯z
k
− ¯z
k−1
, x − yi. (51)
Proof. Remember that the functions d
k
i
are quadratic and have the form (49), that D
k
is defined
in (47), and that ¯z
k
minimizes
1
n
P
n
i=1
d
k
i
. Then, there exists a constant A
k
such that
D
k
(x) = A
k
+
µ
2
kx − ¯z
k
k
2
+ ψ(x).
This gives
D
k
(x) − D
k
(y) =
µ
2
kx − ¯z
k
k
2
−
µ
2
ky − ¯z
k
k
2
+ ψ(x) − ψ(y). (52)
25

Similarly,
D
k−1
(x) − D
k−1
(y) =
µ
2
kx − ¯z
k−1
k
2
−
µ
2
ky − ¯z
k−1
k
2
+ ψ(x) − ψ(y). (53)
Subtracting (52) and (53) gives (51).
Then, we are able to control the value of D
k
(x
k−1
) in the next lemma.
Lemma D.4 (Controlling the value D
k
(x
k−1
)).
For any k ≥ 1,
D
k
(x
k−1
) − D
k
(x
k
) ≤
µ
2
k¯z
k
− ¯z
k−1
k
2
. (54)
Proof. Using Lemma D.3 with x = x
k−1
and y = x
k
yields
D
k
(x
k−1
) − D
k
(x
k
) = D
k−1
(x
k−1
) − D
k−1
(x
k
) − µh¯z
k
− ¯z
k−1
, x
k−1
− x
k
i.
Moreover x
k−1
is the minimum of D
k−1
which is µ-strongly convex. Thus,
D
k−1
(x
k−1
) +
µ
2
kx
k
− x
k−1
k
2
≤ D
k−1
(x
k
).
Adding the two previous inequalities gives the first inequality below
D
k
(x
k−1
) − D
k
(x
k
) ≤ −
µ
2
kx
k
− x
k−1
k
2
− µh¯z
k
− ¯z
k−1
, x
k−1
− x
k
i ≤
µ
2
k¯z
k
− ¯z
k−1
k
2
,
and the last one comes from the basic inequality
1
2
kak
2
+ ha, bi +
1
2
kbk
2
≥ 0.
We have now all the inequalities in hand to prove Theorem 4.1.
Proof of Theorem 4.1.
We start by giving a lower bound of D
k
(x
k−1
) − D
k−1
(x
k−1
).
Take x = x
k−1
in (51). Then, for all y in R
p
,
D
k
(x
k−1
) − D
k−1
(x
k−1
) = D
k
(y) − D
k−1
(y) + µh¯z
k
− ¯z
k−1
, y −x
k−1
i
by (50) ≥ −
δ(L − µ)
2n
ky − x
k−1
k
2
+ µh¯z
k
− ¯z
k−1
, y −x
k−1
i
Choose y that maximizes the above quadratic function, i.e.
y = x
k−1
+
nµ
δ(L − µ)
(¯z
k
− ¯z
k−1
),
and then
D
k
(x
k−1
) − D
k−1
(x
k−1
) ≥
nµ
2
2δ(L − µ)
k¯z
k
− ¯z
k−1
k
2
by (54) ≥
nµ
δ(L − µ)
[D
k
(x
k−1
) − D
k
(x
k
)] .
(55)
Then, we start introducing expected values.
By construction
D
k
(x
k−1
) = D
k−1
(x
k−1
) +
δ
n
(f
i
k
(x
k−1
) − d
k−1
i
k
(x
k−1
)).
After taking expectation, we obtain the relation
E[D
k
(x
k−1
)] =
1 −
δ
n
E[D
k−1
(x
k−1
)] +
δ
n
E[F (x
k−1
)]. (56)
We now introduce an important quantity
τ =
1 −
δ(L − µ)
nµ
δ
n
,
26

and combine (55) with (56) to obtain
τE[F (x
k−1
)] − E[D
k
(x
k
)] ≤ −(1 − τ)E[D
k−1
(x
k−1
)].
We reformulate this relation as
τ (E[F (x
k−1
)] − F
∗
) + (F
∗
− E[D
k
(x
k
)]) ≤ (1 − τ) (F
∗
− E[D
k−1
(x
k−1
)]) . (57)
On the one hand, since F (x
k−1
) ≥ F
∗
, we have
F
∗
− E[D
k
(x
k
)] ≤ (1 − τ ) (F
∗
− E[D
k−1
(x
k−1
)]) .
This is true for any k ≥ 1, as a result
F
∗
− E[D
k
(x
k
)] ≤ (1 − τ )
k
(F
∗
− D
0
(x
0
)) . (58)
On the other hand, since F
∗
≥ D
k
(x
k
), then
τ (E[F (x
k−1
)] − F
∗
) ≤ (1 − τ ) (F
∗
− E[D
k−1
(x
k−1
)]) ≤ (1 − τ)
k
(F
∗
− D
0
(x
0
)) ,
which gives us the relation (14) of the theorem. We conclude giving the choice of δ. We choose it to
maximize the rate of convergence, which turns to maximize τ. This is a quadratic function, which
is maximized at δ =
nµ
2(L−µ)
. However, by definition δ ≤ 1. Therefore, the optimal choice of δ is
given by
δ = min
n
1,
nµ
2(L − µ)
o
.
Note now that
1. When
nµ
2(L−µ)
≤ 1, we have δ =
nµ
2(L−µ)
and τ =
µ
4(L−µ)
.
2. When 1 ≤
nµ
2(L−µ)
, we have δ = 1 and τ =
1
n
−
L−µ
n
2
µ
≥
1
2n
.
Therefore, τ ≥ min
1
2n
,
µ
4(L−µ)
, which concludes the first part of the theorem.
To prove the second part, we use (58) and (14), which gives
E[F (x
k
) − D
k
(x
k
)] = E[F (x
k
)] − F
∗
+ F
∗
− E[D
k
(x
k
)]
≤
1
τ
(1 − τ)
k+1
(F
∗
− D
0
(x
0
) + (1 − τ)
k
(F
∗
− D
0
(x
0
))
=
1
τ
(1 − τ)
k
(F
∗
− D
0
(x
0
)).
D.3 Accelerating MISO-Prox
The convergence rate of MISO (or also SDCA) requires a special handling since it does not satisfy
exactly the condition (8) from Proposition 3.2. The rate of convergence is linear, but with a constant
proportional to F
∗
−D
0
(x
0
) instead of F (x
0
) − F
∗
for many classical gradient-based approaches.
To achieve acceleration, we show in this section how to obtain similar guarantees as Proposition 3.2
and 3.4—that is, how to solve efficiently the subproblems (5). This essentially requires the right
initialization each time MISO-Prox is called. By initialization, we mean initializing the variables z
0
i
.
Assume that MISO-Prox is used to obtain x
k−1
from Algorithm 1 with G
k−1
(x
k−1
) −G
∗
k
≤ ε
k−1
,
and that one wishes to use MISO-Prox again on G
k
to compute x
k
. Then, let us call D
′
the lower-
bound of G
k−1
produced by MISO-Prox when computing x
k−1
such that
x
k−1
= arg min
x∈R
p
(
D
′
(x) =
1
n
n
X
i=1
d
′
i
(x) + ψ(x)
)
,
with
d
′
i
(x) =
µ + κ
2
kx − z
′
i
k
2
+ c
′
i
.
27

Note that we do not index these quantities with k−1 or k for the sake of simplicity. The convergence
of MISO-Prox may ensure that not only do we have G
k−1
(x
k−1
) −G
∗
k
≤ ε
k−1
, but in fact we have
the stronger condition G
k−1
(x
k−1
) − D
′
(x
k−1
) ≤ ε
k−1
. Remember now that
G
k
(x) = G
k−1
(x) +
κ
2
kx − y
k−1
k
2
−
κ
2
kx − y
k−2
k
2
,
and that D
′
is a lower-bound of G
k−1
. Then, we may set for all i in {1, . . . , n}
d
0
i
(x) = d
′
i
(x) +
κ
2
kx − y
k−1
k
2
−
κ
2
kx − y
k−2
k
2
,
which is equivalent to initializing the new instance of MISO-Prox with
z
0
i
= z
′
i
+
κ
κ + µ
(y
k−1
− y
k−2
),
and by choosing appropriate quantities c
0
i
. Then, the following function is a lower bound of G
k
D
0
(x) =
1
n
n
X
i=1
d
0
i
(x) + ψ(x).
and the new instance of MISO-Prox to minimize G
k
and compute x
k
will produce iterates, whose
first point, which we call x
0
, minimizes D
0
. This leads to the relation
x
0
= prox
ψ/(κ+µ)
¯z
0
= prox
ψ/(κ+µ)
¯z
′
+
κ
κ + µ
(y
k−1
− y
k−2
)
,
where we use the notation ¯z
0
=
1
n
P
n
i=1
z
0
i
and ¯z
′
=
1
n
P
n
i=1
z
′
i
as in Algorithm 2.
Then, it remains to show that the quantity G
∗
k
− D
0
(x
0
) is upper bounded in a similar fashion as
G
k
(x
k−1
) −G
∗
k
in Propositions 3.2 and 3.4 to obtain a similar result for MISO-Prox and control the
number of inner-iterations. This is indeed the case, as stated in the next lemma.
Lemma D.5 (Controlling G
k
(x
k−1
) − G
∗
k
for MISO-Prox).
When initializing MISO-Prox as described above, we have
G
∗
k
− D
0
(x
0
) ≤ ε
k−1
+
κ
2
2(κ + µ)
ky
k−1
− y
k−2
k
2
.
Proof. By strong convexity, we have
D
0
(x
0
) +
κ
2
kx
0
− y
k−2
k
2
−
κ
2
kx
0
− y
k−1
k
2
= D
′
0
(x
0
) ≥ D
′
0
(x
k−1
) +
κ + µ
2
kx
0
− x
k−1
k
2
.
Consequently,
D
0
(x
0
) ≥ D
′
(x
k−1
) −
κ
2
kx
0
− y
k−2
k
2
+
κ
2
kx
0
− y
k−1
k
2
+
κ + µ
2
kx
0
− x
k−1
k
2
= D
0
(x
k−1
) +
κ
2
kx
k−1
− y
k−2
k
2
−
κ
2
kx
k−1
− y
k−1
k
2
−
κ
2
kx
0
− y
k−2
k
2
+
κ
2
kx
0
− y
k−1
k
2
+
κ + µ
2
kx
0
− x
k−1
k
2
= D
0
(x
k−1
) − κhx
0
− x
k−1
, y
k−1
− y
k−2
i +
κ + µ
2
kx
0
− x
k−1
k
2
≥ D
0
(x
k−1
) −
κ
2
2(κ + µ)
ky
k−1
− y
k−2
k
2
,
where the last inequality is using a simple relation
1
2
kak
2
+ 2ha, bi +
1
2
kbk
2
≥ 0. As a result,
G
∗
k
− D
0
(x
0
) ≤ G
∗
k
− D
0
(x
k−1
) +
κ
2
2(κ + µ)
ky
k−1
− y
k−2
k
2
≤ G
k
(x
k−1
) − D
0
(x
k−1
) +
κ
2
2(κ + µ)
ky
k−1
− y
k−2
k
2
= G
k−1
(x
k−1
) − D
′
(x
k−1
) +
κ
2
2(κ + µ)
ky
k−1
− y
k−2
k
2
≤ ε
k−1
+
κ
2
2(κ + µ)
ky
k−1
− y
k−2
k
2
28

We remark that this bound is half of the bound shown in (32). Hence, a similar argument gives
the bound on the number of inner iterations. We may finally compute the iteration-complexity of
accelerated MISO-Prox.
Proposition D.6 (Iteration-Complexity of Accelerated MISO-Prox).
When F is µ-strongly convex, the accelerated MISO-Prox algorithm achieves the accuracy ε with
an expected number of iteration upper bounded by
O
min
(
L
µ
,
s
nL
µ
)
log
1
ε
log
L
µ
!
.
Proof. When n > 2(L − µ)/µ, there is no acceleration. The optimal value for κ is zero, and we
may use Theorem 4.1 and Lemma C.1 to obtain the complexity
O
L
µ
log
L
µ
F (x
0
) − D
0
(x
0
)
ε
.
When n < 2(L − µ)/µ, there is an acceleration, with κ = 2(L − µ)/µ − µ. Let us compute the
global complexity using the “template” presented in Appendix C. The number of outer iteration is
given by
k
out
= O
s
L
nµ
log
F (x
0
) − F
∗
ε
!
.
At each inner iteration, we initialize with the value x
0
described above, and we use Lemma D.5:
G
∗
k
− D
0
(x
0
) ≤ ε
k−1
+
κ
2
ky
k−1
− y
k−2
k
2
.
Then,
G
∗
k
− D
0
(x
0
)
ε
k
≤
R
2
,
where
R =
2
1 − ρ
+
2592κ
µ(1 − ρ)
2
(
√
q − ρ)
2
= O
L
nµ
2
!
.
With Miso-Prox, with have τ
G
k
=
1
2n
, thus the expected number of inner iteration is given by
Lemma C.1:
k
in
= O(n log(n
2
R)) = O
n log
L
µ
.
As a result,
Comp = O
s
nL
µ
log
F (x
0
) − F
∗
ε
log
L
µ
!
.
To conclude, the complexity of the accelerated algorithm is given by
O
min
(
L
µ
,
s
nL
µ
)
log
1
ε
log
L
µ
!
.
E Implementation Details of Experiments
In the experimental section, we compare the performance with and without acceleration for three
algorithms SAG, SAGA and MISO-Prox on l
2
-logistic regression problem. In this part, we clarify
some details about the implementation of the experiments.
Firstly, we normalize the observed data before running the regression. Then we apply Catalyst using
parameters according to the theoretical settings. Standard analysis of the logistic function shows that
the Lipschitz gradient parameter L is 1/4 and strongly convex parameter µ = 0 when there is no
29

regularization. Adding properly a l
2
term generates the strongly-convexregimes. Severalparameters
need to be fixed at the beginning stage. The parameter κ is set to its optimal value suggested by
theory, which only depends on n, µ and L. More precisely, κ writes as κ = a(L − µ)/(n + b) −µ,
with (a, b) = (2, −2) for SAG, (a, b) = (1/2, 1 /2) for SAGA and (a, b) = (1, 1) for MISO-
Prox. The parameter α
0
is initialized as the positive solution of x
2
+ (1 − q)x − 1 = 0 where
q =
p
µ/(µ + κ). Furthermore, since the objective function is always positive, F (x
0
) − F
∗
can
be upper bounded by F (x
0
) which allow us to set the ε
k
= (2/9)F (x
0
)(1 − ρ)
k
in the strongly
convex case and ε
k
= 2F (x
0
)/9(k + 2)
4+η
in the non-strongly convex case. Finally, we set the
free parameter in the expression of ε
k
as follows. We simply set ρ = 0.9
√
q in the strongly convex
case and η = 0.1 in the non strongly convex case.
To solve the subproblem at each iteration, the step-sizes parameter for SAG, SAGA and MISO are set
to the values suggested by theory, which only depend on µ, L and κ. All of the methods we compare
store n gradients evaluated at previous iterates of the algorithm. For MISO, the convergenceanalysis
in Appendix D leads to the initialization x
k−1
+
κ
µ+κ
(y
k−1
−y
k−2
) that moves x
k−1
closer to y
k−1
and further away from y
k−2
. We found that using this initial point for SAGA was giving slightly
better results than x
k−1
.
30
