AequeVox: Automated Fairness Testing of Speech
Recognition Systems
Sai Sathiesh Rajan
1
, Sakshi Udeshi
1
,Sudipta Chattopadhyay
1
Singapore University of Technology and Design
Abstract. Automatic Speech Recognition (ASR) systems have become
ubiquitous. They can be found in a variety of form factors and are in-
creasingly important in our daily lives. As such, ensuring that these sys-
tems are equitable to different subgroups of the population is crucial. In
this paper, we introduce, AequeVox, an automated testing framework
for evaluating the fairness of ASR systems. AequeVox simulates differ-
ent environments to assess the effectiveness of ASR systems for different
populations. In addition, we investigate whether the chosen simulations
are comprehensible to humans. We further propose a fault localization
technique capable of identifying words that are not robust to these vary-
ing environments. Both components of AequeVox are able to operate
in the absence of ground truth data.
We evaluated AequeVox on speech from four different datasets using
three different commercial ASRs. Our experiments reveal that non-native
English, female and Nigerian English speakers generate 109%, 528.5%
and 156.9% more errors, on average than native English, male and UK
Midlands speakers, respectively. Our user study also reveals that 82.9% of
the simulations (employed through speech transformations) had a com-
prehensibility rating above seven (out of ten), with the lowest rating
being 6.78. This further validates the fairness violations discovered by
AequeVox. Finally, we show that the non-robust words, as predicted
by the fault localization technique embodied in AequeVox, show 223.8%
more errors than the predicted robust words across all ASRs.
1 Introduction
Automated speech recognition (ASR) systems have made great strides in a vari-
ety of application areas e.g. smart home devices, robotics and handheld devices,
among others. The wide variety of applications have made ASR systems serve in-
creasingly diverse groups of people. Consequently, it is crucial that such systems
behave in a non-discriminatory fashion. This is particularly important because
assistive technologies powered by ASR systems are often the primary mode of
interaction for users with certain disabilities [21]. Consequently, it is critical that
an ASR system employed in such systems is effective in diverse environments
and across a wide variety of speakers (e.g. male, female, native English speak-
ers, non-native English speakers) since they are often deployed in safety-critical
scenarios [19].
arXiv:2110.09843v2 [cs.LG] 13 Jan 2022
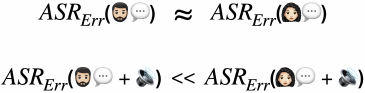
2 S. Rajan et al.
Fig. 1: Fairness Testing in AequeVox
In this paper, we are broadly concerned with the fairness properties in ASR
systems. Specifically, we investigate whether speech from one group is more ro-
bustly recognised as compared to another group. For instance, consider the exam-
ple shown in Figure 1 for a system ASR. The metric ASR
Err
captures the error
rate induced by ASR. Consider speech from two groups of speakers i.e. male and
female. We assume that the ASR has similar error rates for both the groups of
speakers, as illustrated in the upper half of Figure 1. We now apply a small,
constant perturbation on the speech provided by the two groups. Such a per-
turbation can be, for instance, addition of small noise, exemplifying the natural
conditions that the ASR systems may need to work in (e.g. a noisy environment).
If we observe that the ASR
Err
increases disproportionately for one of the speaker
groups, as compared to the other, then we consider such a behaviour a violation
of fairness (see the second half of Figure 1). Intuitively, Figure 1 exemplifies the
violations of Equality of Outcomes [39] in the context of ASR systems, where the
male group is provided with a higher quality of service in a noisy environment
as compared to the female group. Automatically discovering such scenarios of
unfairness via simulating the ASR service in diverse environment is the main
contribution of our AequeVox framework.
AequeVox facilitates fairness testing without having any access to ground
truth transcription data. Although, text-to-speech (TTS) can be used for gener-
ating speech, we argue that it is not suitable for accurately identifying the bias
towards speech coming from a certain group. Specifically, speakers may inten-
tionally use enunciation, intonation, different degrees of loudness or other aspects
of vocalization to articulate their message. Additionally, speakers unintentionally
communicate their social characteristics such as their place of origin (through
their accent), gender, age and education. This is unique to human speech and
TTS systems cannot faithfully capture all the complexities inherent to human
speech. Therefore, we believe that fairness testing of ASR systems should involve
speech data from human speakers.
We note that human speech (and the ASRs) may be subject to adverse en-
vironments (e.g. noise) and it is critical that the fairness evaluation considers
such adverse environments. To facilitate the testing of ASR systems in adverse
environments, we model the speech signal as a sinusoidal wave and subject it
to eight different metamorphic transformations (e.g. noise, drop, low/high pass
filter) that are highly relevant in real life. Furthermore, in the absence of man-
ually transcribed speech, we use a differential testing methodology to expose
fairness violations. In particular, AequeVox identifies the bias in ASR systems
via a two step approach: Firstly, AequeVox registers the increase in error rates
for speech from two groups when subjected to a metamorphic transformation.
AequeVox 3
Subsequently, if the increase in the error rate of one group exceeds the other by a
given threshold, AequeVox classifies this as a violation of fairness. To the best
of our knowledge, we are unaware of any such differential testing methodology.
As a by product of our AequeVox framework, we highlight words that con-
tribute to errors by comparing the word counts from the original speech. This
information can be further used to improve the ASR system.
Existing works [18,52] isolate certain sensitive attributes (e.g. gender) and
use such attributes to test for fairness. Isolating these attributes is difficult in
speech data, making it challenging to apply existing techniques to evaluate the
fairness of ASR systems. AequeVox tackles this by formalizing a unique fair-
ness criteria targeted at ASR systems. Despite some existing efforts in testing
ASR systems [6,14], these are not directly applicable for fairness testing. Ad-
ditionally, some of these works require manually labelled speech transcription
data [14]. Finally, differential testing via TTS [6] is not appropriate to deter-
mine the bias towards certain speakers, as they might use different vocalization
that might be impossible (and perhaps irrational) to generate via a TTS. In
contrast, AequeVox works on speech signals directly and defines transforma-
tions directly on these signals. AequeVox also does not require any access to
manually labelled speech data for discovering fairness violations. In summary,
we make the following contributions in the paper:
1. We formalize a notion of fairness for ASR systems. This formalization draws
parallels between the Equality of Outcomes [39] and the quality of service
provided by ASR systems in varying environments.
2. We present AequeVox, which systematically combines metamorphic trans-
formations and differential testing to highlight whether speech from a cer-
tain group (e.g. female) is subject to fairness violations by ASR systems.
AequeVox neither requires access to ground truth transcription data nor
does it require access to the ASR model structures.
3. We propose a fault localization method to identify the different words con-
tributing to fairness errors.
4. We evaluate AequeVox with three different ASR systems namely Google
Cloud, Microsoft Azure and IBM Watson. We use speech from the Speech Ac-
cent Archive [58], the Ryerson Audio-Visual Database of Emotional Speech
and Song (RAVDESS) [33], Multi speaker Corpora of the English Accents in
the British Isles (Midlands) [12], and a Nigerian English speech dataset [3].
Our evaluation reveals that speech from non-native English speakers and
female speakers exhibit higher fairness violations as compared to native En-
glish speakers and male speakers, respectively.
5. We validate the fault localization of AequeVox by showing that the identi-
fied faulty words generally introduce more errors to ASR systems even when
used within speech generated via TTS systems. The inputs to the TTS sys-
tem are randomly generated sentences that conform to a valid grammar.
6. We evaluate (via the user study) the human comprehensibility score of the
transformations employed by AequeVox on the speech signal. The lowest
comprehensibility score was 6.78 and 82.9% of the transformations had a
comprehensibility score of more than seven.

4 S. Rajan et al.
Table 1: Notations used
Notation Description
GR
B
Base group
GR
k
k ∈ (1, n). Various comparison group
MT Metamorphic transformations
ASR Automatic Speech Recognition system under test
τ A user specified threshold beyond which the difference in word error rate for the base and comparison
groups is considered a violation of individual fairness
2 Background
In this section, we introduce the necessary background information.
Fairness in ASR Systems: A recent work, FairSpeech [28], uses conversa-
tional speech from black and white speakers to find that the word error rate for
individuals who speak African American Vernacular English (AAVE) is nearly
twice as large in all cases.
Testing ASR Systems: The major testing focus, till date has been on image
recognition systems and large language models. Few papers have probed ASR
systems. One such work, Deep-Cruiser [14] applies metamorphic transformations
to audio samples to perform coverage-guided testing on ASR systems. Iwama et
al. [25] also perform automated testing on the basic recognition capabilities of
ASR systems to detect functional defects. CrossASR [6] is another recent paper
that applies differential testing to ASR systems.
The Gap in Testing ASR Systems: There is little work on automated meth-
ods to formalise and test fairness in ASR systems. In this work, we present Ae-
queVox to test the fairness of ASR systems with respect to different population
groups. It accomplishes this with the aid of differential testing of speech samples
that have gone through metamorphic transformations of varying intensity. Our
experimentation suggests that speech from different groups of speakers receives
significantly different quality of service across ASR systems. In the subsequent
sections, we describe the design and evaluation of our AequeVox system.
3 Methodology
In this section, we discuss AequeVox in detail. In particular, we motivate and
formalize the notion of fairness in ASR systems. Then, we discuss our methodol-
ogy to systematically find the violation of fairness in ASR systems. The notations
used are described in Table 1.
Motivation: Equality of outcomes [39] describes a state in which all people have
approximately the same material wealth and income, or in which the general
economic conditions of everyone’s lives are alike. For a software system, equality
of outcomes can be thought of as everyone getting the same quality of service
from the software they are using. For a lot of software services, providing the
same quality of service is baked into the system by design. For example, the
AequeVox 5
results of a search engine only depend on the query. The quality of the result
generally does not depend on any sensitive attributes such as race, age, gender
and nationality. In the context of an ASR, the quality of service does depend
on these sensitive attributes. This inferior quality of service may be especially
detrimental in safety-critical settings such as emergency medicine [19] or air
traffic management [29,22].
In our work, we show that the quality of service provided by ASR systems
is vastly different depending on one’s gender/nationality/accent. Suppose there
are two groups of people using an ASR system, males and females. They have
approximately the same level of service when using this service at their homes.
However, once they step into a different environment such as a noisy street, the
quality of service drops notably for the female users, but does not drop noticeably
for the male users. This is a violation of the principle of equality of outcomes
(as seen for software systems) and more specifically, group fairness [15]. Such
a scenario is unfair (violation of group fairness) because some groups enjoy a
higher quality of service than others.
In our work, we aim to automate the discovery of this unfairness. We do this
by simulating the environment where the behaviour of ASR systems are likely to
vary. The simulated environment is then enforced in speech from different groups.
Finally, we measure how different groups are served in different environments.
Formalising Fairness in ASRs: In this section, we formalise the notion of
fairness in the context of automated speech recognition systems (ASRs). The
fairness definition in ASRs is as follows:
|ASR
Err
(GR
i
) − ASR
Err
(GR
j
)| ≤ τ
(1)
Here, GR
i
and GR
j
capture speech from distinct groups of people. If the er-
ror rates induced by ASR for group GR
i
(ASR
Err
(GR
i
)) and for group GR
j
(ASR
Err
(GR
j
)) differ beyond a certain threshold, we consider this scenario to
be unfair. Such a notion of unfairness was studied in a recent work [28].
In this work, we want to explore whether different groups are fairly treated
under varying conditions. Intuitively, we subject speech from different groups to
a variety of simulated environments. We then measure the word error rates of the
speech in such simulated environments and check if certain groups fare better
than others. Formally, we capture the notion of fairness targeted by AequeVox
as follows:
D
i
← ASR
Err
(GR
i
) − ASR
Err
(GR
i
+ δ)
D
j
← ASR
Err
(GR
j
) − ASR
Err
(GR
j
+ δ)
|D
i
− D
j
| ≤ τ
(2)
Here we perturb the speech of the two groups (GR
i
and GR
j
) by adding some
δ to the speech. We compare the degradation in the speech (D
i
and D
j
). If the
degradation faced by one group is far greater than the one faced by the other,
we have a fairness violation. This is because speech from both groups ought to
face similar degradation when subject to similar environments (simulated by δ
perturbation) when equality of outcomes [39] holds. More specifically, this is a

6 S. Rajan et al.
Algorithm 1 AequeVox Fairness Testing
1: procedure Fairness_Testing(GR
B
, MT , GR
1
, · · · , GR
n
, τ, ASR
1
, ASR
2
)
2: Error_Set ← ∅
3: for T ∈ MT do
4: GR
T
B
← T (GR
B
)
5: L computes the average word level levenshtein distance
6: between the outputs of ASR
1
and ASR
2
7: d
B
← L(ASR
1
(GR
B
), ASR
2
(GR
B
))
8: d
T
B
← L(ASR
1
(GR
T
B
), ASR
2
(GR
T
B
))
9: D
B
← d
T
B
− d
B
10: for k ∈ (1, n) do
11: GR
T
k
← T (GR
k
)
12: d
k
← L(ASR
1
(GR
k
), ASR
2
(GR
k
))
13: d
T
k
← L(ASR
1
(GR
T
k
), ASR
2
(GR
T
k
))
14: D
k
← d
T
k
− d
k
15: if D
B
− D
k
> τ then
16: Error_Set ← Error_Set ∪ (GR
B
, GR
k
, T )
17: end if
18: end for
19: end for
20: return Error_Set
21: end procedure
group fairness violation because the quality of service (outcome) depends on the
group [15,54].
Example: To motivate our system, let us sketch out an example. Consider texts
of approximately the same length spoken by two sets of speakers whose native
languages are L
1
and L
2
respectively. Let us assume that both sets of speakers
read out a text in English. AequeVox uses two ASR systems and obtains the
transcript of this speech. AequeVox then employs differential testing to find
the word-level levenshtein distance [31] between these two sets of transcripts.
Let us also assume that the average word-level levenshtein distance is two and
four for L
1
and L
2
native speakers, respectively.
AequeVox then simulates a noisy environment by adding noise to the speech
and obtains the transcript of this transformed speech. Let us assume now that
the average levenshtein distance for this transformed speech is 4 and 25 for L
1
and L
2
native speakers, respectively. It is clear that the degradation for the
speech of native L
2
speakers is much more severe. In this case, the quality of
service that L
2
native speakers receive in noisy environments is worse than L
1
native speakers. This is a violation of fairness which AequeVox aims to detect.
The working principle behind AequeVox holds even if the spoken text is
different. This is because AequeVox just measures the relative degradation in
ASR performance for a set of speakers. For large datasets, we are able to measure
the average degradation in ASR performance with respect to different groups of
speakers (e.g. male, female, native, non-native English speakers).
Metamorphic Transformations of Sound: The ability to operate in a wide
range of environments is crucial in ASR systems as they are deployed in safety-
critical settings such as medical emergency services [19] and air traffic manag-
ment [22], [29], which are known to have interference and noise. Metamorphic
speech transformations serve to simulate such scenarios. The key insight for our
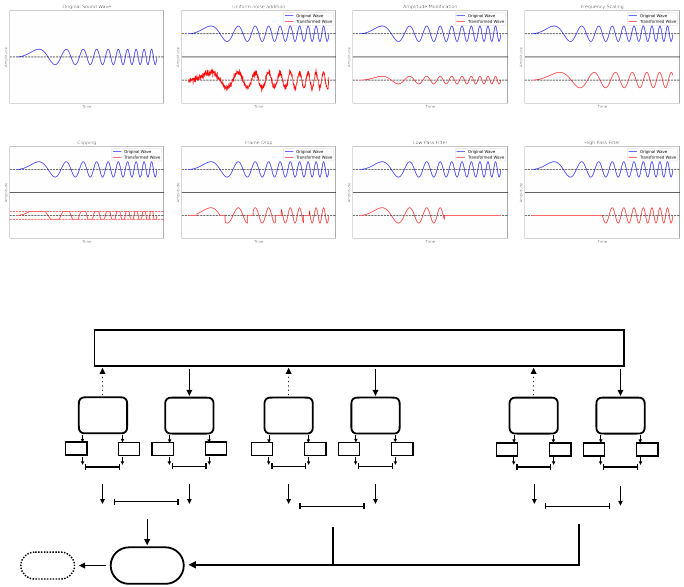
AequeVox 7
(a) (b) (c) (d)
(e) (f) (g) (h)
Fig. 2: Sound wave transformations
Metamorphic Transformations (MT)
GR
B
GR
T
B
ASR
1
GR
1
GR
T
1
GR
n
GR
T
n
…
ASR
2
ASR
1
ASR
2
ASR
1
ASR
2
ASR
1
ASR
2
ASR
1
ASR
2
ASR
1
ASR
2
d
B
d
T
B
d
1
d
T
1
d
n
d
T
n
D
B
D
1
D
n
k ∈ (1, n)
D
B
−D
k
> τ
True
Error Set
Fig. 3: AequeVox System Overview
metamorphic transformations comes from how waves are represented and what
can happen to these waves when they’re transmitted in different mediums. We
realise this insight in the fairness testing system for ASR systems. To the best
of our knowledge AequeVox is the first work that combines this insight from
acoustics, software testing and software fairness to evaluate the fairness of ASR
systems. AequeVox uses the addition of noise (Figure 2 (b)), amplitude mod-
ification (Figure 2 (c)), frequency modification (Figure 2 (d)), amplitude clip-
ping (Figure 2 (e)), frame drops (Figure 2 (f)), low-pass filters (Figure 2 (g)),
and high-pass filters (Figure 2 (h)) as metamorphic speech transformations. We
choose these transformations because they are the most common distortions for
sound in various environments [2]. The details of the transformations are in
Appendix B.
System Overview: Algorithm 1 provides an outline of our overall test gener-
ation process. We realise the notion of fairness described in Equation (2) using
differential testing. The error rates (ASR
Err
) for a particular speech clip are
found by finding the difference between the outputs of two ASR systems, ASR
1
and ASR
2
. It is important to note that we make a design choice to use differ-
ential testing to find the error rate (ASR
Err
). This helps us eliminate the need
for ground truth transcription data which is both labor intensive and expensive
8 S. Rajan et al.
to obtain. Furthermore, AequeVox realises the δ seen in Equation (2) by using
metamorphic transformations for speech (see Figure 3). These speech metamor-
phic transformations represent the various simulated environments for which Ae-
queVox wants to measure the quality of service for different groups. Addition-
ally, the user can customise this δ per their requirements. In our implementation
we use eight distinct metamorphic transformations as δ (see Figure 2). Specif-
ically, we investigate how fairly do two ASR systems (ASR
1
and ASR
2
) treat
groups (GR
T
k
| k ∈ {1, 2, · · · n}) with respect to a base group (GR
B
). AequeVox
achieves this by taking a dataset of speech which contains data from two or more
different groups (e.g. male and female speakers, Native English and Non-native
English speakers) and modifies these speech snippets through a set of trans-
formations (M T ). These are then divided into base group transformed speech
(GR
T
B
) and the transformed speech for other groups (GR
T
k
| k ∈ {1, 2, · · · n}).
As seen in Algorithm 1, the average word-level levenshtein distance (word-level
levenshtein distance divided by the number of words in the longer transcript)
between the outputs of the two ASR systems is captured by d
B
and d
T
B
for
the original and transformed speech respectively. Similarly, for the comparison
groups GR
T
k
(k ∈ {1, 2, · · · n}) the word-level levenshtein distance is captured by
d
k
and d
T
k
. The higher the levenshtein distance the larger the error in terms
of differential testing. In other words, larger error in differential testing would
mean that the ASR systems disagree on a higher number of words.
To capture the degradation in the quality of service for the speech subjected
to simulated environments (MT ), we compute the difference between the word-
level levenshtein distance for the original and transformed speech. Specifically,
we compute D
B
as d
T
B
− d
B
and D
k
as d
T
k
− d
k
(k ∈ {1, 2, · · · n}) for the base and
comparison groups, respectively. The higher this metric (D
B
and D
k
), the more
severe the degradation in ASR quality of service because of the transformation T .
We compare these metrics and if D
B
exceeds D
k
by some threshold τ , we
classify this as an error for the base group (GR
B
) and more specifically a violation
of fairness (see Figure 3). In our experiments we set each of the groups in our
dataset as the base group (GR
B
) and run the AequeVox technique to find
errors with respect to that base group. The lower the errors (as computed via
the violation of the assertion D
B
− D
k
≤ τ), the fairer the ASR systems are
with respect to groups GR
B
. As an example, let us say Russian speakers are the
base group (GR
B
), English speakers are the comparison group (GR
k
) and the
value of τ is 0.1. If D
B
is strictly greater than D
k
by 0.1, then fairness violation
is counted for the Russian speakers. Otherwise, no fairness errors are recorded.
Fault Localisation: AequeVox introduces a word-level fault localisation tech-
nique, which does not require any access to ground truth data. We first illustrate
a use case of this fault localisation technique.
Example: Let us consider a corpus of English sentences by a group of speakers
(say GR) who speak language L
1
natively. AequeVox builds a dictionary for
all the words in the transcript obtained from ASR
1
. An excerpt from such a
dictionary appears as follows: {brother : 16, nice : 25, is : 33, · · · }. This means
the words brother, nice and is were seen 16, 25 and 33 times in the transcript
AequeVox 9
Algorithm 2 AequeVox Fault Localizer
1: procedure Fault_Localizer(WC , WC
T
θ
, ω, param
T
)
2: Drop_Count ← ∅
3: Non_Robust_Words ← ∅
4: for word ∈ WC .keys() do
5: init_count ← WC [word]
6: Returns the minimum count of word across all the parameter
7: of transformation T
8: min_count ← get_min(WC
T
θ
[word], param
T
)
9: count_diff ← max ((init_count − min_count), 0)
10: if count_diff > ω then
11: Non_Robust_Words ← Non_Robust_Words ∪ {word}
12: end if
13: Drop_Count ← Drop_Count ∪ {count_dif f }
14: end for
15: return Non_Robust_Words, Drop_Count
16: end procedure
ASR
Word Level
Fault Localizer
GR
GR
T
θ
W C
W C
T
θ
Average
Drop
Non Robust
Words
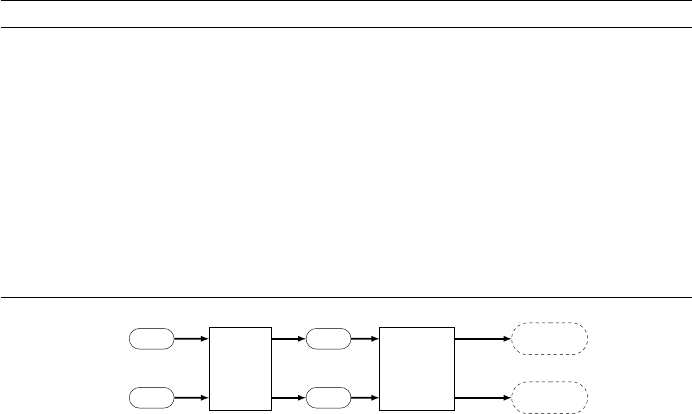
Fig. 4: AequeVox Fault Localization Overview
respectively. Now, assume AequeVox simulates a noisy environment by adding
noise with various signal to noise (SNR) ratios as follows: {10, 8, 6, 4, 2 }. This
is the parameter for the transformation (param
T
).
Once AequeVox obtains the transcript of these transformed inputs, it cre-
ates dictionaries similar to the ones seen in the preceding paragraph. Let the
relevant subset of the dictionary for SNR two (2) be {brother : 1, nice : 23,
is : 32, · · · }. We use this to determine that the utterance of the word brother
is not robust for noise addition for the group GR. This is because, the word
brother appears significantly less in the transcript for the modified speech, as
compared to the transcript for the original speech.
AequeVox fault localisation overview: Algorithm 2 provides an overview
of the fault localization technique implemented in AequeVox. The goal of the
AequeVox fault localisation is to find words for a group (GR) that are not ro-
bust to the simulated environments. Specifically, AequeVox finds words which
are not recognised by the ASR when subjected to the appropriate speech trans-
formations.
The transformation is represented by T
θ
. Here, T ∈ MT is the transformation
and θ ∈ param
T
is the parameter of the transformation, which controls the
severity of the transformation.
As seen in Algorithm 2, AequeVox builds a word count dictionary for each
word in W C and W C
T
θ
for the original speech and for each θ ∈ param
T
re-
spectively. For each word, AequeVox finds the difference in the number of
appearances for a word in W C and in W C
T
θ
for θ ∈ param
T
. To compute the
difference, we locate the minimum number of appearances across all the trans-
formation parameters θ ∈ param
T
(i.e. min_count in Algorithm 2). This is to
locate the worst-case degradation across all transformation parameters. The dif-
10 S. Rajan et al.
ference is then calculated between min_count and the number of appearances of
the word in the original speech (i.e. init_count). If the difference exceeds some
user-defined threshold ω, then AequeVox classifies the respective words as non
robust w.r.t the group GR and transformation T .
We envision that practitioners can then review the data generated by fault lo-
calization (i.e. Algorithm 2) and target the non-robust words to further improve
their ASR systems for speech from underrepresented groups [26] and accom-
modate for speech variability [23]. In RQ3, we validate our fault localization
method empirically and in RQ4, we show how the proposed fault localization
method can be used to highlight fairness violations.
4 Datasets and Experimental Setup
ASR Systems under Test: We evaluate AequeVox on three commercial ASR
systems from Google Cloud Platform (GCP), IBM Cloud, and Microsoft Azure.
We use the standard models for GCP and Azure, and the BroadbandModel for
IBM. In all three cases, the audio samples were identically encoded as .wav files
using Linear 16 encoding.
In each of the following transformations, we vary a parameter, θ. We call this
the transformation parameter. Some of the transformations have abbreviations
within parentheses. Such abbreviations are used in later sections to refer to the
respective transformations.
Amplitude Scaling (Amp): For amplitude scaling, we scale the audio sequence
by a constant by multiplying each individual audio sample by θ.
Clipping: The audio samples are scaled such that their amplitude values are
bound by [−1, 1]. AequeVox then clips these samples such that the amplitude
range is [−θ, θ]. These clipped samples are then rescaled and encoded.
Drop/Frame: For Drop, AequeVox divides the audio into 20ms chunks. θ%
of these chunks are then randomly discarded (amplitude set to zero) from the
audio. For Frame, AequeVox divides the audio into θms chunks and 10% of
these chunks are then randomly discarded. No two adjacent chunks are discarded.
High Pass (HP)/ Low Pass (LP) Filter: Here we apply a butterworth [8]
filter of order two to the entire audio file with θ determining the cut-off frequency.
Noise Addition (Noise): θ represents signal to noise (SNR) ratio [27] of the
transformed audio signal. A lower θ means higher noise in the transformed audio.
Frequency Scaling (Scale): In this case, θ is the sampling frequency. The
lower the value of θ, the slower the audio. In this transformation, the audio is
slowed down θ times.
Table 2 lists all the different values used for θ. An additional parameter
(θ = 2.0) is used for Amp.
Datasets: We use the Speech Accent Archive (Accents) [58], the Ryerson Audio-
Visual Database of Emotional Speech and Song (RAVDESS) [33], Multi speaker

AequeVox 11
Table 2: Transformations Used
Transformation Type θ Used
Least Destructive −→ Most Destructive
Amplitude 0.5 0.4 0.3 0.2 0.1
Clipping 0.05 0.04 0.03 0.02 0.01
Drop 5 10 15 20 25
Frame 10 20 30 40 50
HP 500 600 700 800 900
LP 900 800 700 600 500
Noise 10 8 6 4 2
Scale 0.9 0.8 0.7 0.6 0.5
Table 3: Datasets Used
Dataset
Duration(s)
#Clips
#Distinct
Speakers
Accents 25-35 28 28
RAVDESS 3 32 8
Midlands 3-5 4 4
Nigerian English 4-6 4 4
Corpora of the English Accents in the British Isles (Midlands) [12], and a Nige-
rian English speech dataset [3] to evaluate AequeVox taking care to ensure
male and female speakers are equally represented. Table 3 provides additional
details about the setup.
5 Results
In this section, we discuss our evaluation of AequeVox in detail. In particular,
we structure our evaluation in the form of four research questions (RQ1 to
RQ4). The analysis of these research questions appears in the following sections.
RQ1: What is AequeVox’s efficacy?
We structure the analysis of this research question into three sections, each
corresponding to a dataset we have used in our analysis. All of the relevant data is
presented in Table 4. We first analyse the number of errors (used interchangeably
with fairness violations) for each case. Subsequently, we analyse the sensitivity of
the errors with respect to the values of τ (τ ∈ {0.01, 0.05, 0.1, 0.15}). Detecting
violations of fairness is regulated by parameter τ . Lower values of τ imply that
the degradation of word error rates between two groups should be similar, and
conversely higher values of τ allow for the difference in degradation of word error
rates to be more severe between two groups. Next, we analyse the sensitivity of
the pairs of the ASR systems under test. Concretely, we analyse the errors found
in the Microsoft Azure and IBM Watson (MS_IBM), Google Cloud and IBM
Watson (IBM_GCP), and Microsoft Azure and Google Cloud (MS_GCP) pairs.
Finally, we analyse the sensitivity of the AequeVox test generation with respect
to the eight different types of transformations implemented (see Figure 2).

12 S. Rajan et al.
Table 4: Errors Discovered by AequeVox
Accents RAVDESS
Nigerian/Midlands
English
English Ganda French Gujarati Indonesian Korean Russian Male Female Midlands Nigerian
Total Errors 312 844 413 406 311 1086 853 28 176 93 239
τ Sensitivity
0.01 168 381 267 232 178 499 354 12 92 36 75
0.05 75 245 99 101 85 340 227 8 53 26 65
0.10 43 145 39 49 34 172 161 5 21 17 55
0.15 26 73 8 24 14 75 111 3 10 14 44
ASR Sensitivity
MS IBM 36 369 128 126 64 388 303 10 57 30 86
GCP IBM 131 325 123 147 98 342 361 9 64 31 96
MS GCP 145 150 162 133 149 356 189 9 55 32 57
Transition Sensitivty
Clipping 4 81 38 159 72 182 237 0 24 50 3
Drop 8 113 33 29 40 184 45 0 21 4 33
Frame 14 106 61 25 36 170 26 1 13 13 19
Noise 5 128 54 86 22 217 213 0 24 5 43
LP 39 158 108 57 14 110 208 0 45 4 34
Amplitude 81 19 44 33 14 40 26 0 27 8 40
HP 114 168 29 9 61 87 57 9 20 1 51
Scale 47 71 46 8 52 96 41 18 2 8 16
It is important to note that that we excluded the two most destructive Scale
transformations. This is because the word error rate for these transformations
is 0.89 on average out of 1. This degradation may be attributed to the trans-
formation itself rather than the ASR. To avoid such cases, we exclude these
transformations from this research question.
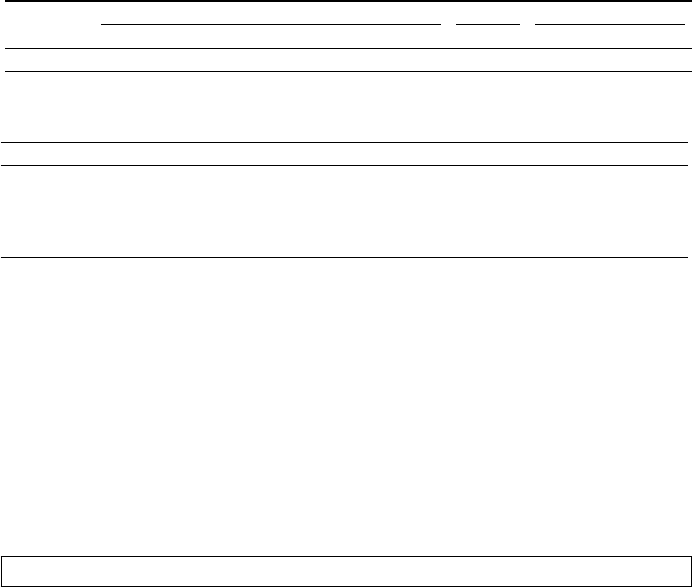
Accents Dataset: Native English speakers and Indonesian speakers have the
lowest number of errors. On average, speech from non-native English speakers
generates 109% more errors in comparison to speech from native English speak-
ers. For the two smallest values of τ , speech from the native English speakers
shows the least number of fairness violations. Speech from native English speak-
ers has the lowest, second lowest and third lowest errors for the pairs of ASRs,
(MS_IBM), (MS_GCP) and (IBM_GCP) respectively. Speech from native En-
glish speakers has the lowest errors for the clipping, two types of frame drops and
noise transformations and the second lowest errors for the low-pass filter trans-
formation. The remaining transformations, namely amplitude, high-pass filter
and scaling induce a comparable number of errors from native and non-native
English speakers.
Speech from non-native English speakers generally exhibits more fairness
violations in comparison to speech from native English speakers.
RAVDESS Dataset: Speech from male speakers has significantly lower errors
than speech from female speakers. On average, speech from female speakers
generates 528.57% more errors in comparison to speech from male speakers.
Speech from male speakers shows significantly fewer fairness violations for all
values of τ , and for all ASR pairs tested. Clipping, both types of frame drops,
noise, low-pass and amplitude induce significantly fewer errors on speech from
AequeVox 13
male speakers. However, speech from both groups have comparable number of
errors when subject to high-pass and scale transformations.
Speech from female speakers has significantly higher fairness violations in
comparison to speech from male speakers.
Midlands/Nigeria Dataset: Speech from UK Midlands English (ME) speak-
ers has significantly lower errors than speech from Nigerian English (NE) speak-
ers. On average, speech from NE speakers generates 156.9% more errors in com-
parison to speech from ME speakers. Speech from ME speakers has significantly
fewer fairness errors for all values of τ, and for all ASR pairs tested. For the
transformations scale, drop, noise, amplitude, low pass and high pass filters,
the speech from ME speakers has significantly fewer error than speech from NE
speakers. For the transformations, clipping and frame, we find that speech from
both groups have similar number of errors.
Speech from Nigerian English speakers has significantly more fairness errors
in comparison to speech from UK Midlands speakers.
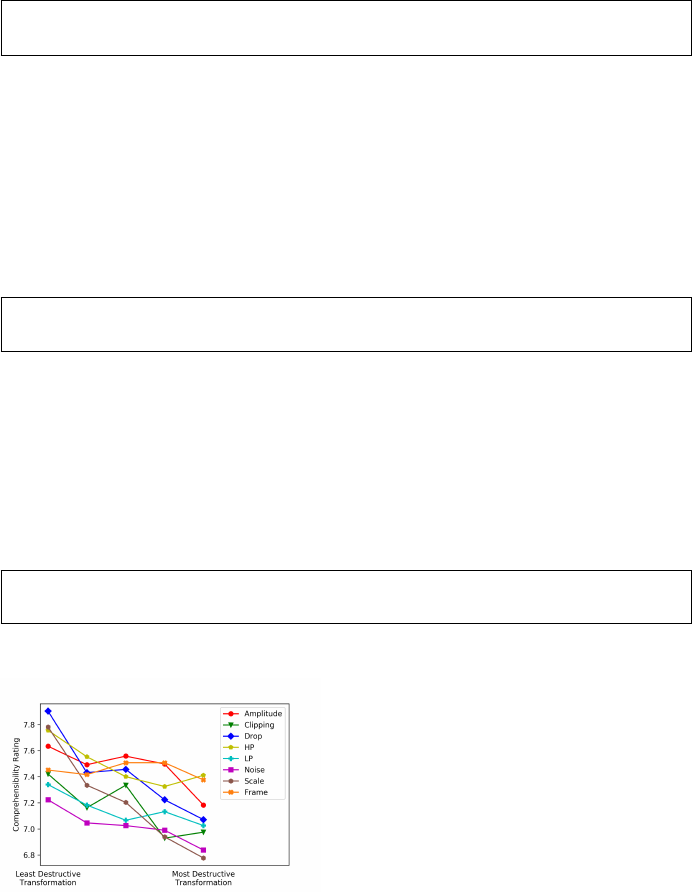
RQ2: What are the effects of transformations on comprehensibility?
To better understand the effects of the transformations (see Figure 2) on
the comprehensibility of the speech we conducted a user study. Speech of one
female native English speaker from the Accents [58] dataset was used. Survey
participants were presented with the original audio file along with a set of trans-
formed speech files in order of increasing intensity. All the transformations (see
Figure 2) and transformation parameters (see Table 2) were used. We asked 200
survey participants (sourced through Amazon mTurk) the following question:
How comprehensible is (transformed) Speech with respect
to the Original speech?
Fig. 5: Average Transformation
Comprehensibility Ratings
The rating of one (1) is Not Compre-
hensible at all and the rating of ten (10) is
Just as Comprehensible as the Original.
Unsurprisingly, as seen in Figure 5, in-
creasing the intensities of the transforma-
tion had a generally detrimental effect on
the comprehensibility of the speech. But
none of the transformations majorly affect
the comprehensibility of the speech. All of
the transformations had a average compre-
hensibility rating above 6.75 and 82.9% of
the transformations had a comprehensibil-
ity rating above 7.
The average degradation in comprehen-
sibility for the least destructive parameter across all transformations was 24.36%.
Noise was the most destructive at 27.75% and drop was the least destructive
(20.96%).
14 S. Rajan et al.
Table 5: Fairness errors where the transformations have a comprehensibility rat-
ing of at least 7.2
Accents RAVDESS
Nigerian/Midlands English
English Ganda French Gujarati Indonesian Korean Russian Male Female Midlands Nigerian
Total Errors
246 509 240 166 225 687 329 28 88 55 161
Table 6: Grammar-generated sentence examples
ASR Microsoft Google Cloud IBM Watson
Robust Ashley likes fresh smoothies Karen loves plastic straws William detests plastic cups
Paul adores spoons of cinnamon Donald hates big decisions Steven detests big flags
Non-robust Ashley detests thick smoothies John loves spoons of cinnamon Betty likes scoops of ice cream
Ryan likes slabs of cake Robert loves bags of concrete Amanda is fond of things like
groceries
The average degradation in comprehensibility for the most destructive pa-
rameter across all transformations was 29.18%. In this case, scaling was the most
destructive at 32.23% whereas drop was the least destructive with 25.88%.
Additionally, for each transformation, we analyse the percentage drop of com-
prehensibility between the least and the most destructive transformation param-
eters. The average drop is 4.82% across all transformations. The scaling and drop
transformations show high relative percentage drops of 10.05% and 8.32% respec-
tively. Amplitude, clipping, noise, high-pass and low-pass filters show closer to
average drops between 3.1% and 4.5%. Frame, on the other hand, shows very
low relative drops at 0.76%.
All the transformations, though destructive, are comprehensible by humans.
For safety critical applications, we recommend that future work test the
whole gamut of transformations. For other use cases, practitioners may choose
the transformations that satisfy their needs. To aid this, AequeVox allows the
users to choose the comprehensibility threshold of the transformations. As seen
in Table 5, our conclusion holds even if we choose the transformations with
higher comprehensibility threshold (7.2). In particular, we observe that speech
from native English speakers, male and UK Midlands Speakers generally exhibit
lower errors. The detailed sensitivity analysis for the errors is seen in Figure 7,
Figure 8 and Figure 9 in the appendix. Additional user study details are seen in
Appendix C.
RQ3: Are the outputs produced by AequeVox fault localiser valid?
To study the validity of the outputs of the fault localiser, we study the
number of errors for the predicted robust and non-robust words. We do this
by generating speech containing the predicted robust and non-robust words for
each ASR tested. We choose an ω of three, three and two for GCP, MS Azure
and IBM respectively to choose the non-robust words (see Algorithm 2). We
choose the robust words from the set of words that do not show any errors
in the presence of noise (count_diff = 0 in Algorithm 2) for these specific ASR

AequeVox 15
systems. Specifically, we test whether the robust and non-robust words identified
by the fault localiser in the Accents dataset are robust in the presence of noise.
Our goal is to show that if noise is added to speech containing these non-robust
words, the ASR will be less likely to recognise them. Vice-versa, if noise is added
to the predicted robust-words they are less likely to be affected.
To generate the speech from the output we generate sentences containing the
robust and non-robust words predicted by the fault localiser for each ASR using
a grammar and then use a text-to-speech (TTS) service to generate speech.
The actual randomly selected robust and non-robust words (in bold) and the
examples of the sentences generated by the grammar can be seen in Table 6.
The grammars themselves can be seen in Appendix D. We use the Google TTS
for MS Azure and we use the Microsoft Azure TTS for GCP and IBM to generate
the speech.
To evaluate the generality of outputs of the fault localisation technique, we
use the speech produced by the TTS and then add noise to that speech. This
speech is used to generate a transcript from the ASR and the transcript is used to
evaluate how many of the predicted robust and non-robust words are incorrect
in the transcript. We add the most noise possible to the TTS speech in our
AequeVox framework. Specifically, the signal to noise (SNR) ratio is 2. We use
the TTS generated speech for 50 sentences for each of the robust and non-robust
cases. Each sentence has either a robust or a non-robust word.
The results of the experiments are seen in Table 7. In the transcript of the
speech with noise added at SNR 2, robust words show zero error for the predicted
robust words for Microsoft and Google Cloud and 21 errors for IBM. The non-
robust words on the other hand had 23, 15 and 30 errors. Thus, the predicted
non-robust words have a higher propensity for errors than the robust words.
The outputs of the fault localisation techniques are general and valid.
Table 7: Transcript Errors
ASR
Transcript
Errors
Microsoft (MS)
Robust 0
Non-Robust 23
Google Cloud (GCP)
Robust 0
Non-Robust 15
IBM Watson (IBM)
Robust 21
Non-Robust 30
Table 8: Grammarly Scores
ASR
Overall
Score
Correctness Clarity
Microsoft (MS)
Robust 99
Looking
Good
Very
Clear
Non-Robust 99
Google Cloud (GCP)
Robust 100
Non-Robust 99
IBM Watson (IBM)
Robust 100
Non-Robust 96
Note on grammar validity: Since the grammars used by us to validate the
explanations of AequeVox are handcrafted, they may be prone to errors. To
verify these hand crafted grammars, we use 100 sentences produced by each

16 S. Rajan et al.
Table 9: Average words mispredictions in the Accents dataset using the Ae-
queVox localisation techniques
Accents
English Ganda French Gujarati Indonesian Korean Russian
ASR Sensitivity
GCP 1.21 1.51 1.21 1.17 1.07 1.55 1.64
IBM 1.03 1.94 1.38 1.35 1.48 1.92 1.70
MS Azure 0.47 0.66 0.40 0.48 0.36 0.87 0.63
Transition Sensitivity
Clipping 2.00 2.53 2.12 2.60 2.29 2.81 3.13
Drop 0.30 1.02 0.52 0.54 0.57 1.15 0.74
Frame 0.38 0.89 0.68 0.56 0.51 1.19 0.65
Noise 0.57 1.60 0.85 1.27 0.71 1.74 1.54
LP 1.72 2.22 1.90 1.79 1.58 1.98 2.13
Amplitude 0.17 0.15 0.11 0.12 0.06 0.20 0.16
HP 0.74 0.75 0.38 0.22 0.49 0.64 0.76
Scale 1.38 1.79 1.42 0.90 1.54 1.89 1.45
grammar and use the online tool Grammarly [4] to investigate the semantic and
syntactic correctness of the sentences and the clarity. The sentences generated
by the grammars have a high overall average score of 98.33 out of 100, with the
lowest being 96 (see Table 8). On the correctness and clarity measure, all the
sentences generated by the grammars score Looking Good and Very Clear.
RQ4: Can the fault localiser be used to highlight unfairness?
The goal of this RQ is to investigate if the output of Algorithm 2 can call at-
tention to bias between different groups. Specifically, we evaluate if some groups
show fewer faults, on average than others. To this end, we use the fault local-
isation algorithm (Algorithm 2) on the accents dataset and record the number
of words incorrect in the transcript, on average for each group of the accents
dataset. This is done for each ASR under test. It is also important to note that
this technique uses no ground truth data and requires no manual input. This
technique is designed to work with just the speech data and metadata (groups).
Table 9 shows the average word drops across all transformations for the
accents dataset for each ASR under test. Speech from native-English speakers
shows the lowest average word drops for the IBM Watson ASR and the third
lowest for GCP and MS Azure ASRs. We also investigate the average word drops
for each transformation in AequeVox averaged across all ASRs. Speech from
native English speakers has the lowest average word drops for the Clipping, two
types of frame drops and noise transformations and the second lowest errors
for the low-pass filter transformation. (see Table 9). For the rest of the trans-
formations, namely amplitude, high-pass filter and scaling, we find that both
speech from non-native English speakers and speech from native English speak-
ers have comparable average word drops (see Table 9). This result is consistent
with results seen in RQ1.
The technique seen in Algorithm 2 can be used to highlight bias in speech and
the results are consistent with RQ1.
AequeVox 17
6 Threats to Validity
User Study: In conducting the study, two assumptions were made. Firstly,
we assume that the degree to which comprehensibility changes when subject
to transformations is independent of the characteristics of the speaker’s voice.
Secondly, we assume that the speech is reflective of the broader English language.
In future work a larger scale user study could be performed to verify the results.
ASR Baseline Accuracy: AequeVox measures the degradation of the speech
to characterise the unfairness amongst groups and ASR systems. If the baseline
error rate is very high, then the room for further degradation is very low. As a
result, AequeVox expects ASR services to have a high baseline accuracy. To
mitigate this threat, we use state-of-the-art commercial ASR systems which have
high baseline accuracies.
Completeness and Speech Data: AequeVox is incomplete, by design, in
the discovery of fairness violations. AequeVox is limited by the speech data
and the groups of this speech data used to test these ASR systems. With new
data and new groups, it is possible to discover more fairness violations. The
practitioners need to provide data to discover these. In our view, this is a valid
assumption because the developers of these systems have a large (and growing)
corpus of such speech data. It is also important to note that AequeVox does
not need the ground truth transcripts for this speech data and such speech data
is easier to obtain.
Fault Localisation: To test AequeVox’s fault localisation, we identify the
robust and non-robust words in the speech and subsequently construct sentences
(with the aid of a grammar). These sentences are then converted to speech using a
text-to-speech (TTS) software and the performance of the robust and non- robust
words is measured. In the future, we would like to repeat the same experiment
with a fixed set of speakers, which allows us capture the peculiarities of speech
in contrast to the usage of TTS software.
7 Related Work
In the past few years, there has been significant attention in testing ML systems
[38,51,35,50,59,37,53,43,60,17,55,9,44,20]. Some of these works target coverage-
based testing [51,59,37,35] or leverage property driven testing [44], while others
focus effective testing in targeted domains e.g. text [53,43]. None of these works,
however, are directly applicable for testing ASR systems. In contrast, the goal
of AequeVox is to automatically discover violations of fairness in ASR systems
without access to ground truth data.
DeepCruiser [14] uses metamorphic transformations and performs coverage-
guided fuzzing to discover transcription errors in ASR systems. Concurrently,
CrossASR [6] uses text to generate speech from a TTS engine and subsequently
employs differential testing to find bugs in the ASR system. In contrast to these
systems, the goal of AequeVox is to automatically find violations of fairness
18 S. Rajan et al.
by measuring the degradation of transcription quality from the ASR when the
speech is transformed. AequeVox compares this degradation across various
groups of speakers and if the difference is substantial, AequeVox characterises
this as a fairness violation. Moreover, AequeVox neither requires access to
manually labelled speech data nor does it require any white/grey box access
to the ASR model. Works on audio adversarial testing [25], [11], [10], [40], [30]
aims to find an imperceptible perturbation that are specially crafted for an
audio file. In contrast, AequeVox aims to find fairness violations. Additionally,
AequeVox also proposes automatic fault localisation for ASR systems without
using a ground truth transcript.
Unlike AequeVox, recent works on fairness testing have focused on credit
rating [18,52,5,61,45,47,46,44], computer vision [13,7] or NLP systems [36,48]. In
the systems that deal with such data, it is possible to isolate certain sensitive at-
tributes (gender, age, nationality) and test for fairness based on these attributes.
It is challenging to isolate such sensitive attributes in speech data, necessitating
the need for a separate fairness testing framework specifically for speech data.
Frameworks such as LIME [41], SHAP [34], Anchor [42] and DeepCover [49]
attempt to reason why a model generates a specific output for a specific input. In
contrast to this, AequeVox’s fault localisation algorithm identifies utterances
spoken by a group which are likely to be not recognised by ASR systems in the
presence of a destructive interference (such as noise). Recent fault localization
approaches either aim to highlight the neurons [16] or training code [56] that
are responsible for a fault during inference. In contrast, AequeVox highlights
words that are likely to be transcribed wrongly without having any access to the
ground truth transcription and with only blackbox access to the ASR system.
8 Conclusion
In this work we introduce AequeVox, an automated fairness testing technique
for ASR systems. To the best of our knowledge, we are the first work that
explores considerations beyond error rates for discovering fairness violations.
We also show that the speech transformations used by AequeVox are largely
comprehensible through a user study. Additionally, AequeVox highlights words
where a given ASR system exhibits faults, and we show the validity of these
explanations. These faults can also be used to identify unfairness in ASR systems.
AequeVox is evaluated on three ASR systems and we use four distinct
datasets. Our experiments reveal that speech from non-native English, female
and Nigerian English speakers exhibit more errors, on average than speech from
native English, male and UK Midlands speakers, respectively. We also validate
the fault localization embodied in AequeVox by showing that the predicted
non-robust words exhibit 223.8% more errors than the predicted robust words
across all ASRs.
We hope that AequeVox drives further work on systematic fairness testing
of ASR systems. To aid future work, we make all our code and data publicly
available: https://github.com/sparkssss/AequeVox
AequeVox 19
References
1. https://ccrma.stanford.edu/~jos/sasp/Spectrum_Analysis_Sinusoids.html
2. Audio data augmentation (2021), https://www.kaggle.com/CVxTz/
audio-data-augmentation
3. Crowdsourced high-quality nigerian english speech data set (2021), http://
openslr.org/70/
4. Grammarly (2021), https://app.grammarly.com/
5. Aggarwal, A., Lohia, P., Nagar, S., Dey, K., Saha, D.: Black box fairness testing of
machine learning models. In: Proceedings of the 2019 27th ACM Joint Meeting on
European Software Engineering Conference and Symposium on the Foundations
of Software Engineering. pp. 625–635 (2019)
6. Asyrofi, M.H., Thung, F., Lo, D., Jiang, L.: Crossasr: Efficient differential testing
of automatic speech recognition via text-to-speech. In: 2020 IEEE International
Conference on Software Maintenance and Evolution (ICSME). pp. 640–650 (2020).
https://doi.org/10.1109/ICSME46990.2020.00066
7. Buolamwini, J., Gebru, T.: Gender shades: Intersectional accuracy disparities in
commercial gender classification. In: Conference on fairness, accountability and
transparency. pp. 77–91. PMLR (2018)
8. Butterworth, S., et al.: On the theory of filter amplifiers. Wireless Engineer 7(6),
536–541 (1930)
9. Calò, A., Arcaini, P., Ali, S., Hauer, F., Ishikawa, F.: Simultaneously searching and
solving multiple avoidable collisions for testing autonomous driving systems. In:
Proceedings of the 2020 Genetic and Evolutionary Computation Conference. pp.
1055–1063 (2020)
10. Carlini, N., Wagner, D.: Audio adversarial examples: Targeted attacks on speech-
to-text. In: 2018 IEEE Security and Privacy Workshops (SPW). pp. 1–7. IEEE
(2018)
11. Chen, G., Chen, S., Fan, L., Du, X., Zhao, Z., Song, F., Liu, Y.: Who is real
bob? adversarial attacks on speaker recognition systems. In: IEEE Symposium on
Security and Privacy (2021)
12. Demirsahin, I., Kjartansson, O., Gutkin, A., Rivera, C.: Open-source Multi-speaker
Corpora of the English Accents in the British Isles. In: Proceedings of The 12th
Language Resources and Evaluation Conference (LREC). pp. 6532–6541. European
Language Resources Association (ELRA), Marseille, France (May 2020), https:
//www.aclweb.org/anthology/2020.lrec-1.804
13. Denton, E., Hutchinson, B., Mitchell, M., Gebru, T., Zaldivar, A.: Image counter-
factual sensitivity analysis for detecting unintended bias (2019)
14. Du, X., Xie, X., Li, Y., Ma, L., Zhao, J., Liu, Y.: Deepcruiser: Automated guided
testing for stateful deep learning systems (2018)
15. Dwork, C., Hardt, M., Pitassi, T., Reingold, O., Zemel, R.: Fairness through aware-
ness. In: Proceedings of the 3rd innovations in theoretical computer science con-
ference. pp. 214–226 (2012)
16. Eniser, H.F., Gerasimou, S., Sen, A.: Deepfault: Fault localization for deep neural
networks. In: Hähnle, R., van der Aalst, W.M.P. (eds.) Fundamental Approaches
to Software Engineering - 22nd International Conference, FASE 2019, Held as Part
of the European Joint Conferences on Theory and Practice of Software, ETAPS
2019, Prague, Czech Republic, April 6-11, 2019, Proceedings. Lecture Notes in
Computer Science, vol. 11424, pp. 171–191. Springer (2019)
20 S. Rajan et al.
17. Feng, Y., Shi, Q., Gao, X., Wan, J., Fang, C., Chen, Z.: Deepgini: prioritizing
massive tests to enhance the robustness of deep neural networks. In: Proceedings
of the 29th ACM SIGSOFT International Symposium on Software Testing and
Analysis. pp. 177–188 (2020)
18. Galhotra, S., Brun, Y., Meliou, A.: Fairness testing: testing software for discrim-
ination. In: Proceedings of the 2017 11th Joint Meeting on Foundations of Soft-
ware Engineering, ESEC/FSE 2017, Paderborn, Germany, September 4-8, 2017.
pp. 498–510 (2017). https://doi.org/10.1145/3106237.3106277, http://doi.acm.
org/10.1145/3106237.3106277
19. Goss, F.R., Zhou, L., Weiner, S.G.: Incidence of speech recognition errors in the
emergency department. International journal of medical informatics 93, 70–73
(2016)
20. Guo, Q., Xie, X., Li, Y., Zhang, X., Liu, Y., Li, X., Shen, C.: Audee: Automated
testing for deep learning frameworks. In: Proceedings of the 35th IEEE/ACM
International Conference on Automated Software Engineering (ASE). pp. 486–498.
ACM (Dec 2020)
21. Hawley, M.S.: Speech recognition as an input to electronic assistive technology.
British Journal of Occupational Therapy 65(1), 15–20 (2002)
22. Helmke, H., Ohneiser, O., Mühlhausen, T., Wies, M.: Reducing controller workload
with automatic speech recognition. In: 2016 IEEE/AIAA 35th Digital Avionics
Systems Conference (DASC). pp. 1–10. IEEE (2016)
23. Huang, C., Chen, T., Li, S.Z., Chang, E., Zhou, J.L.: Analysis of speaker variability.
In: INTERSPEECH. pp. 1377–1380 (2001)
24. Huber, D.M., Runstein, R.E.: Modern recording techniques, pp. 416,487. CRC
Press (2013)
25. Iwama, F., Fukuda, T.: Automated testing of basic recognition capability for speech
recognition systems. In: 2019 12th IEEE Conference on Software Testing, Valida-
tion and Verification (ICST). pp. 13–24. IEEE (2019)
26. Jain, A., Upreti, M., Jyothi, P.: Improved accented speech recognition using accent
embeddings and multi-task learning. In: Interspeech. pp. 2454–2458 (2018)
27. Johnson, D.H.: Signal-to-noise ratio. Scholarpedia 1(12), 2088 (2006)
28. Koenecke, A., Nam, A., Lake, E., Nudell, J., Quartey, M., Mengesha, Z., Toups,
C., Rickford, J.R., Jurafsky, D., Goel, S.: Racial disparities in automated speech
recognition. Proceedings of the National Academy of Sciences 117(14), 7684–7689
(2020)
29. Kopald, H.D., Chanen, A., Chen, S., Smith, E.C., Tarakan, R.M.: Applying
automatic speech recognition technology to air traffic management. In: 2013
IEEE/AIAA 32nd Digital Avionics Systems Conference (DASC). pp. 6C3–1. IEEE
(2013)
30. Kreuk, F., Adi, Y., Cisse, M., Keshet, J.: Fooling end-to-end speaker verification
with adversarial examples. In: 2018 IEEE International Conference on Acoustics,
Speech and Signal Processing (ICASSP). pp. 1962–1966. IEEE (2018)
31. Levenshtein, V.I.: Binary codes capable of correcting deletions, insertions, and
reversals. In: Soviet physics doklady. vol. 10, pp. 707–710. Soviet Union (1966)
32. Li, J., Deng, L., Gong, Y., Haeb-Umbach, R.: An overview of noise-robust auto-
matic speech recognition. IEEE/ACM Transactions on Audio, Speech, and Lan-
guage Processing 22(4), 745–777 (2014)
33. Livingstone, S.R., Russo, F.A.: The ryerson audio-visual database of emotional
speech and song (ravdess): A dynamic, multimodal set of facial and vocal expres-
sions in north american english. PloS one 13(5), e0196391 (2018)
AequeVox 21
34. Lundberg, S.M., Lee, S.I.: A unified approach to interpreting model predictions.
In: Guyon, I., Luxburg, U.V., Bengio, S., Wallach, H., Fergus, R., Vishwanathan,
S., Garnett, R. (eds.) Advances in Neural Information Processing Systems 30,
pp. 4765–4774. Curran Associates, Inc. (2017), http://papers.nips.cc/paper/
7062-a-unified-approach-to-interpreting-model-predictions.pdf
35. Ma, L., Juefei-Xu, F., Zhang, F., Sun, J., Xue, M., Li, B., Chen, C., Su, T., Li, L.,
Liu, Y., Zhao, J., Wang, Y.: Deepgauge: multi-granularity testing criteria for deep
learning systems. In: Proceedings of the 33rd ACM/IEEE International Conference
on Automated Software Engineering, ASE 2018, Montpellier, France, September
3-7, 2018. pp. 120–131 (2018)
36. Ma, P., Wang, S., Liu, J.: Metamorphic testing and certified mitigation of fairness
violations in NLP models. In: Bessiere, C. (ed.) Proceedings of the Twenty-Ninth
International Joint Conference on Artificial Intelligence, IJCAI 2020. pp. 458–465
37. Odena, A., Olsson, C., Andersen, D., Goodfellow, I.: Tensorfuzz: Debugging neural
networks with coverage-guided fuzzing. In: International Conference on Machine
Learning. pp. 4901–4911. PMLR (2019)
38. Pei, K., Cao, Y., Yang, J., Jana, S.: Deepxplore: Automated whitebox testing
of deep learning systems. In: Proceedings of the 26th Symposium on Operating
Systems Principles, Shanghai, China, October 28-31, 2017. pp. 1–18 (2017)
39. Phillips, A.: Defending equality of outcome. Journal of political philosophy 12(1),
1–19 (2004)
40. Qin, Y., Carlini, N., Cottrell, G., Goodfellow, I., Raffel, C.: Imperceptible, robust,
and targeted adversarial examples for automatic speech recognition. In: Interna-
tional conference on machine learning. pp. 5231–5240. PMLR (2019)
41. Ribeiro, M.T., Singh, S., Guestrin, C.: "why should I trust you?": Explaining the
predictions of any classifier. In: Proceedings of the 22nd ACM SIGKDD Interna-
tional Conference on Knowledge Discovery and Data Mining, San Francisco, CA,
USA, August 13-17, 2016. pp. 1135–1144 (2016)
42. Ribeiro, M.T., Singh, S., Guestrin, C.: Anchors: High-precision model-agnostic
explanations. In: Proceedings of the AAAI Conference on Artificial Intelligence.
vol. 32 (2018)
43. Ribeiro, M.T., Wu, T., Guestrin, C., Singh, S.: Beyond accuracy: Behavioral test-
ing of NLP models with checklist. In: Jurafsky, D., Chai, J., Schluter, N., Tetreault,
J.R. (eds.) Proceedings of the 58th Annual Meeting of the Association for Compu-
tational Linguistics, ACL 2020, Online, July 5-10, 2020. pp. 4902–4912. Association
for Computational Linguistics (2020)
44. Sharma, A., Demir, C., Ngomo, A.C.N., Wehrheim, H.: Mlcheck-property-driven
testing of machine learning models. arXiv preprint arXiv:2105.00741 (2021)
45. Sharma, A., Wehrheim, H.: Testing machine learning algorithms for balanced data
usage. In: 2019 12th IEEE Conference on Software Testing, Validation and Verifi-
cation (ICST). pp. 125–135. IEEE (2019)
46. Sharma, A., Wehrheim, H.: Automatic fairness testing of machine learning models.
In: IFIP International Conference on Testing Software and Systems. pp. 255–271.
Springer (2020)
47. Sharma, A., Wehrheim, H.: Higher income, larger loan? monotonicity testing of
machine learning models. In: Proceedings of the 29th ACM SIGSOFT International
Symposium on Software Testing and Analysis. pp. 200–210 (2020)
48. Soremekun, E., Udeshi, S., Chattopadhyay, S.: Astraea: Grammar-based fairness
testing. arXiv preprint arXiv:2010.02542 (2020)
22 S. Rajan et al.
49. Sun, Y., Chockler, H., Huang, X., Kroening, D.: Explaining image classifiers using
statistical fault localization. In: Vedaldi, A., Bischof, H., Brox, T., Frahm, J. (eds.)
Computer Vision - ECCV 2020 - 16th European Conference, Glasgow, UK, August
23-28, 2020, Proceedings, Part XXVIII. Lecture Notes in Computer Science, vol.
12373, pp. 391–406. Springer (2020)
50. Sun, Y., Wu, M., Ruan, W., Huang, X., Kwiatkowska, M., Kroening, D.: Concolic
testing for deep neural networks. In: Proceedings of the 33rd ACM/IEEE Inter-
national Conference on Automated Software Engineering, ASE 2018, Montpellier,
France, September 3-7, 2018. pp. 109–119 (2018)
51. Tian, Y., Pei, K., Jana, S., Ray, B.: Deeptest: automated testing of deep-neural-
network-driven autonomous cars. In: Proceedings of the 40th International Con-
ference on Software Engineering, ICSE 2018, Gothenburg, Sweden, May 27 - June
03, 2018. pp. 303–314 (2018)
52. Udeshi, S., Arora, P., Chattopadhyay, S.: Automated directed fairness testing.
In: Proceedings of the 33rd ACM/IEEE International Conference on Automated
Software Engineering, ASE 2018, Montpellier, France, September 3-7, 2018. pp.
98–108 (2018)
53. Udeshi, S.S., Chattopadhyay, S.: Grammar based directed testing of machine learn-
ing systems. IEEE Transactions on Software Engineering (2019)
54. Verma, S., Rubin, J.: Fairness definitions explained. In: 2018 ieee/acm international
workshop on software fairness (fairware). pp. 1–7. IEEE (2018)
55. Wang, J., Chen, J., Sun, Y., Ma, X., Wang, D., Sun, J., Cheng, P.: Robot:
Robustness-oriented testing for deep learning systems. In: ICSE ’21: 43rd Interna-
tional Conference on Software Engineering (2021)
56. Wardat, M., Le, W., Rajan, H.: Deeplocalize: Fault localization for deep neural
networks. In: 43rd IEEE/ACM International Conference on Software Engineering,
ICSE 2021, Madrid, Spain, 22-30 May 2021. pp. 251–262. IEEE (2021)
57. Weik, M.: Communications standard dictionary. Springer Science & Business Me-
dia (2012)
58. Weinberger, S.H., Kunath, S.A.: The speech accent archive: towards a typology of
english accents. In: Corpus-based Studies in Language Use, Language Learning,
and Language Documentation, pp. 265–281. Brill Rodopi (2011)
59. Xie, X., Ma, L., Juefei-Xu, F., Xue, M., Chen, H., Liu, Y., Zhao, J., Li, B., Yin,
J., See, S.: Deephunter: a coverage-guided fuzz testing framework for deep neural
networks. In: Proceedings of the 28th ACM SIGSOFT International Symposium
on Software Testing and Analysis. pp. 146–157 (2019)
60. Xie, X., Zhang, Z., Chen, T.Y., Liu, Y., Poon, P.L., Xu, B.: Mettle: a metamor-
phic testing approach to assessing and validating unsupervised machine learning
systems. IEEE Transactions on Reliability 69(4), 1293–1322 (2020)
61. Zhang, J., Harman, M.: "ignorance and prejudice" in software fairness. In: Inter-
national Conference on Software Engineering. vol. 43. IEEE (2021)

AequeVox 23
A Additional Tables
Table 10: Average User Study Comprehensibility Scores
Transformation Average Comprehensibility Score
Least Destructive −→ Most Destructive
Amplitude 7.63 7.49 7.56 7.50 7.18
Clipping 7.42 7.16 7.34 6.93 6.97
Drop 7.90 7.43 7.46 7.22 7.07
Frame 7.45 7.42 7.51 7.51 7.38
HP 7.76 7.55 7.40 7.32 7.41
LP 7.34 7.18 7.07 7.13 7.03
Noise 7.22 7.05 7.03 6.99 6.84
Scale 7.78 7.34 7.20 6.94 6.78

24 S. Rajan et al.
B Sound Transformations
Sound Wave: To understand metamorphic transformations of sound, it is useful
to understand the sinusoidal representation of sound. A sound wave of a single
amplitude and frequency can be represented as follows:
y(t) = A sin(2πft + φ) (3)
where A is the amplitude, the peak deviation of the function from zero, f is the
ordinary frequency i.e. the number of oscillations (cycles) that occur each second
and φ is the phase which specifies (in radians) where in its cycle the oscillation
is at time t = 0.
It is known that any sound can be expressed as a sum of sinusoids [1]. The
transformations on sinusoidal wave can thus, be applied to any sound. Without
losing generality and for simplicity we only show the transformations for a sound
wave captured by a single sinusoidal wave. This is the wave of the form seen in
Equation (3). To have a variable frequency, we set f ∝
t
c
where c > 1 and c ∈ R.
This wave is seen in Figure 3 (a).
In the following, we describe the transformations used in our AequeVox
technique.
Noise Addition: Noise robust ASR systems is a classic field of research and
in the past thirty years there have been to the order of a hundred different
techniques to try and solve this problem [32]. Noise is also a natural phenomenon
in daily life and we may not expect signals used by ASR systems to be totally
clean. As a result, one expects an ASR system to take noise into account and
still be effective in noisy environments.
At each time step t in the sound wave, a random variable R ∼ D, where D is
some distribution, is added. As the range of R increases, the noise increases and
the signal to noise ratio decreases. The metamorphic transformation of adding
noise is seen in Figure 2 (b). Concretely the transformed function y
T
(t) can be
expressed as follows:
y
T
(t) = y(t) + R ∀t, R ∼ D (4)
Amplitude Modification: A sound wave’s amplitude relates to the changes
in pressure. A sound is perceived as louder if the amplitude increases and softer
if it decreases. We expect ASR systems to have minor degradations in perfor-
mance, if any across groups of loud and soft speakers. To this end, as seen
in Figure 2 (c)., we increase or decrease the amplitude of a sound wave as a
metamorphic transformation. Concretely the transformed function y
T
(t) can be
expressed as follows:
y
T
(t) = c ∗ y(t) ∀t, c ∈ R (5)
Frequency Scaling: In this type of distortion, the frequency of the audio signal
is scaled up or down by some constant factor. We expect ASR systems to be
AequeVox 25
largely robust to changes in frequency (slowing down or speeding up) in the
speech signal (see Figure 2 (d)). To this end, we modify the frequency of a sound
as a metamorphic transformation as follows:
y
T
(t) = y(c ∗ t) ∀t, c ∈ R (6)
Amplitude Clipping: Clipping is a form of distortion that limits the signal
once a threshold is exceeded. For sound, once the wave exceeds a certain ampli-
tude, the sound wave is clipped. Clipping occurs when the sound signal exceeds
the maximum dynamic range of an audio channel [24]. To simulate this, we use
clipping as a metamorphic transformation as follows (see Figure 2 (e)):
y
T
(t) =
c, y(t) > c,
y(t), −c < y(t) < c,
−c, y(t) < c,
∀t, c ∈ R (7)
Frame Drop: A common scenario with wireless communication is the dropping
of information (frames or samples in technical parlance [57]) due to interference
with other signals. This usually happens when a signal is modified in a disruptive
manner. A common example of this is a crosstalk on telephones. To simulate
this effect as a metamorphic transformation for the ASR system, AequeVox
randomly drops some frames and information to test for the robustness of the
system. This metamorphic transformation is seen in Figure 2 (f). Formally, the
transformation is captured as follows:
y
T
(t) =
(
y(t), t 6∈ FD,
0, t ∈ FD,
∀t (8)
where FD is a set which contains the values of t where the frames are dropped.
The set FD can be configured by the user, or randomly. There are two consid-
erations to be made when performing the transformation in Equation (8). The
first is the total percentage of the signal to be dropped, tot_drop. This means
that out of the total length of the signal, the transformation drops tot_drop%
of the signal. The second is frame_size, which controls the size of continuous
signal that is dropped. AequeVox considers both the aforementioned cases.
Specifically, in one case AequeVox keeps tot_drop constant and varies the
frame_size, while in the other, we keep f rame_size constant and vary the
tot_drop percentage.
High/Low-Pass filters: High-pass filters only let sounds with frequencies higher
than a certain threshold pass, and conversely low-pass filters only let sounds with
frequencies lower than a certain threshold pass. These filters are commonly used
in audio systems to direct frequencies of sound to certain types of speakers. This
is because speakers are designed for certain types of frequencies and sound waves
outside of those frequencies might damage these speakers. In our evaluation, to
simulate the source of sound being from one of such speakers, we use these fil-
ters as a metamorphic transformation. The low-pass filter transformation is seen
26 S. Rajan et al.
in Figure 2 (g) and the high pass filter transformation is seen in Figure 2 (h).
The transformation equation for the high-pass filter is seen in Equation (9) and
correspondingly, for the low-pass filter is seen in Equation (10). Θ
HP
and Θ
LP
are the high pass and low pass filter thresholds, respectively.
y
T
(t) =
(
y(t), f > Θ
HP
,
0, f < Θ
HP
,
∀t (9)
y
T
(t) =
(
y(t), f < Θ
LP
,
0, f > Θ
LP
,
∀t (10)
AequeVox 27
C User Study Setup Details
We conducted a user study using Amazon’s mTurk platform. In particular, 200
participants were presented with an audio file containing speech utterances by a
female native English speaker. In addition, the audio clip contained nearly all the
sounds in the English language to represent the full spectrum of the language,
as found in Speech Accent Archive [58]. Users were presented with the original
audio file along with a set of transformed speech files in order of increasing
intensity. For instance, in the case of the "Scale" transformation, participants
were first presented with a file that was slightly slowed down and subsequent
files were slowed down even further. Users then rated the comprehensibility of
the speech files in comparison to the original audio file. The rating was on a 1
to 10 scale, where "10" refers to the case where the modified speech file was just
as comprehensible as the original speech and "1" refers to the case where the
modified speech was not comprehensible at all.
Participants were required to rate the comprehensibility of the entire set of
transformations under study i.e. Amplitude, Clipping, Drop, Frame, Highpass,
Lowpass, Noise and Scale (see Figure 2). The average score of each transforma-
tion was used to determine the comprehensibility score. In general, we see that
the comprehensibility of the speech tends to go down as the intensity of the
transformation increases, as observed in Figure 5. We present a comprehensive
analysis of the user study results in RQ2.

28 S. Rajan et al.
D Additional Figures
GCP-Grammar → Robust-Gram | Non-Robust-Gram
Robust-Gram → Name Main-Verb ‘‘plastic’’ Noun1 |
Name Main-Verb ‘‘big’’ Noun2
Non-Robust-Gram → Name Main-Verb ‘‘bags’’ Noun3 |
Name Main-Verb ‘‘spoons’’ Noun4
Name → ‘‘Mary’’ | ‘‘James’’ | · · ·
Main-Verb → ‘‘loves’’ | ‘‘hates’’ | · · ·
Noun1 → ‘‘cups’’ | ‘‘containers’’ | · · ·
Noun2 → ‘‘flags’’ | ‘‘decisions’’ | · · ·
Noun3 → ‘‘of wool’’ | ‘‘of groceries’’ | · · ·
Noun4 → ‘‘of cinnamon’’ | ‘‘of sugar’’ | · · ·
(a)
MS-Grammar → Robust-Gram | Non-Robust-Gram
Robust-Gram → Name Main-Verb ‘‘fresh’’ Noun1 |
Name Main-Verb ‘‘spoons’’ Noun2
Non-Robust-Gram → Name Main-Verb ‘‘thick’’ Noun1 |
Name Main-Verb ‘‘slabs’’ Noun3
Name → ‘‘Mary’’ | ‘‘James’’ | · · ·
Main-Verb → ‘‘loves’’ | ‘‘hates’’ | · · ·
Noun1 → ‘‘sandwiches’’ | ‘‘cream’’ | · · ·
Noun2 → ‘‘of cinnamon’’ | ‘‘of sugar’’ | · · ·
Noun3 → ‘‘of ice cream’’ | ‘‘of cake’’ | · · ·
(b)
IBM-Grammar → Robust-Gram | Non-Robust-Gram
Robust-Gram → Name Main-Verb ‘‘plastic’’ Noun1 |
Name Main-Verb ‘‘big’’ Noun2
Non-Robust-Gram → Name Main-Verb ‘‘things’’ Noun3 |
Name Main-Verb ‘‘scoops’’ Noun4
Name → ‘‘Mary’’ | ‘‘James’’ | · · ·
Main-Verb → ‘‘loves’’ | ‘‘hates’’ | · · ·
Noun1 → ‘‘cups’’ | ‘‘containers’’ | · · ·
Noun2 → ‘‘flags’’ | ‘‘decisions’’ | · · ·
Noun3 → ‘‘like wool’’ | ‘‘like art’’ | · · ·
Noun4 → ‘‘of ice cream’’ | ‘‘of cream’’ | · · ·
(c)
Fig. 6: Grammars used by AequeVox to verify the generality of the Fault lo-
caliser predictions
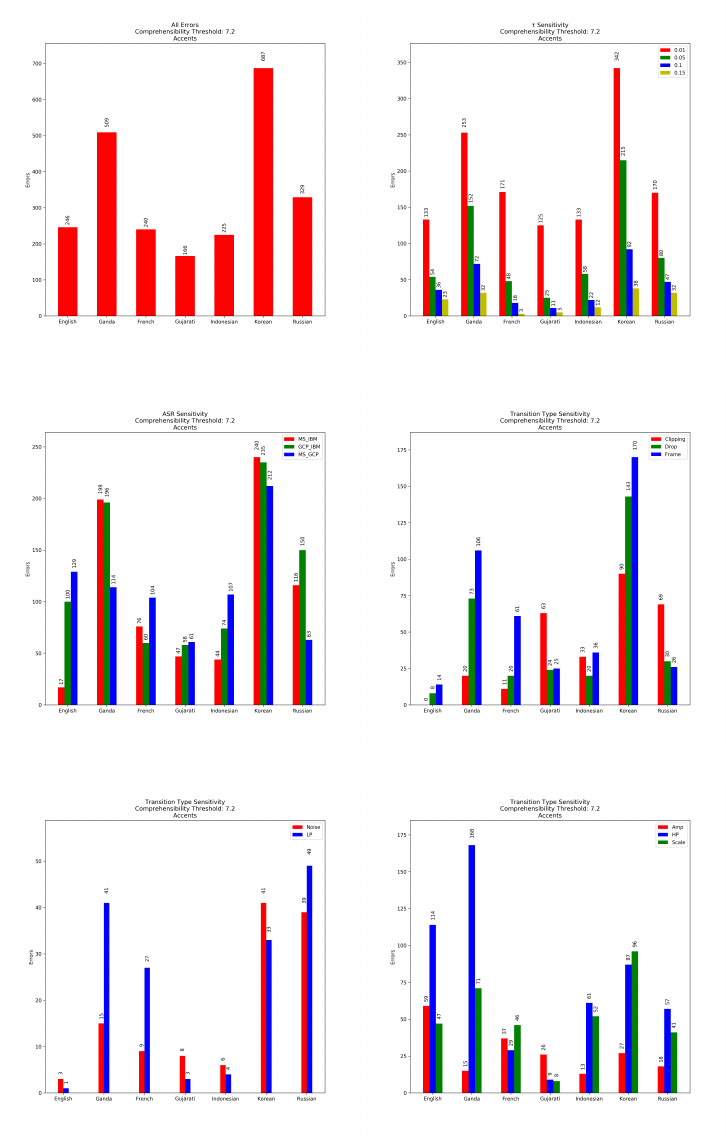
AequeVox 29
(a) (b)
(c) (d)
(e) (f)
Fig. 7: Sensitivity analysis for the Accents dataset (with comprehensibility
threshold 7.2 for transformations)
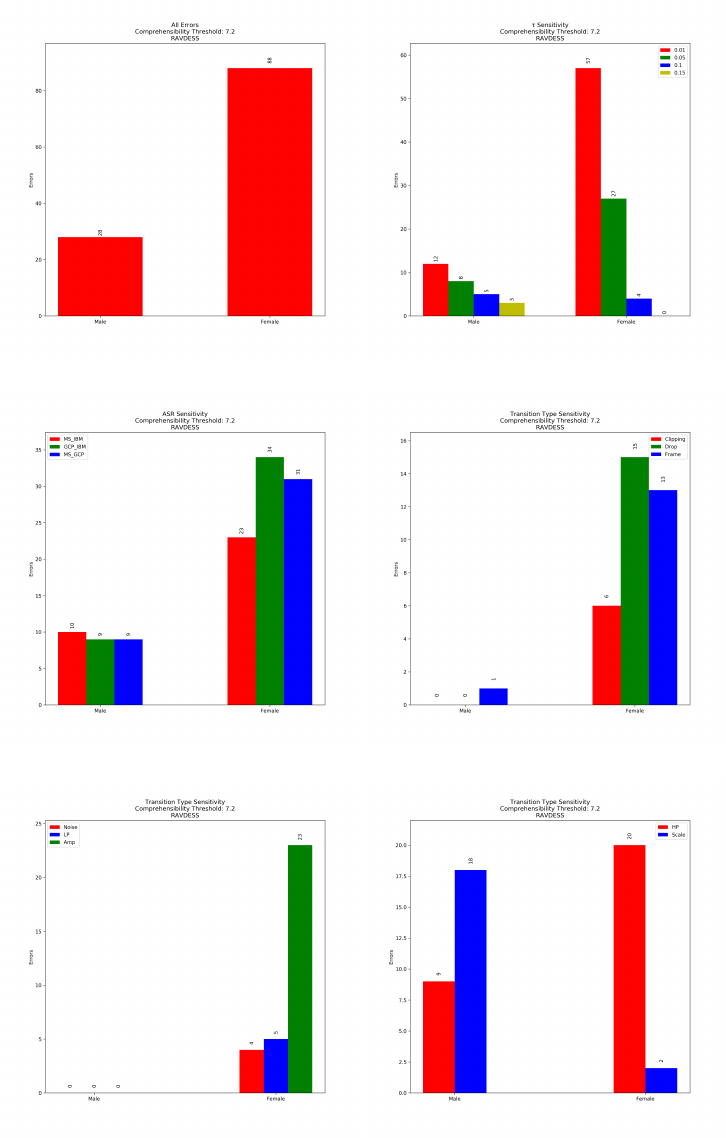
30 S. Rajan et al.
(a) (b)
(c) (d)
(e) (f)
Fig. 8: Sensitivity analysis for the RAVDESS dataset (with comprehensibility
threshold 7.2 for transformations)
AequeVox 31
(a) (b)
(c) (d)
(e) (f)
Fig. 9: Sensitivity analysis for the Nigerian English/UK Midlands English dataset
(with comprehensibility threshold 7.2 for transformations)
