DeepGamble: Towards unlocking real-time player
intelligence using multi-layer instance segmentation
and attribute detection
Danish Syed
* †
University of Michigan
Naman Gandhi
*
ZS Associates
Arushi Arora
*
ZS Associates
Nilesh Kadam
ZS Associates
Abstract—Annually the gaming industry spends approximately
$15 billion in marketing reinvestment. However, this amount is
spent without any consideration for the skill and luck of the
player. For a casino, an unskilled player could fetch ∼ 4×
more revenue than a skilled player. This paper describes a
video recognition system that is based on an extension of
the Mask R-CNN model. Our system digitizes the game of
blackjack by detecting cards and player bets in real time and
processes decisions they took in order to create accurate player
personas. Our proposed supervised learning approach consists
of a specialized three-stage pipeline that takes images from two
viewpoints of the casino table and does instance segmentation to
generate masks on proposed regions of interests. These predicted
masks along with derivative features are used to classify image
attributes that are passed onto the next stage to assimilate
the gameplay understanding. Our end-to-end model yields an
accuracy of ∼95% for main bet detection and ∼98% for card
detection in a controlled environment trained using transfer
learning approach with 900 training examples. Our approach is
generalizable and scalable and shows promising results in varied
gaming scenarios and test data. Such granular level gathered
data, helped in understanding player’s deviation from optimal
strategy and thereby separate the skill of the player from the
luck of the game. Our system also assesses the likelihood of card
counting by correlating player’s betting pattern to the deck’s
scaled count. Such a system lets casinos flag fraudulent activity
and calculate expected personalized profitability for each player
and tailor their marketing reinvestment decisions.
Index Terms—player intelligence, instance segmentation,
monte-carlo simulation, blackjack, wager detection, strategy
evaluation, card counting
I. INTRODUCTION
In this paper, we present DeepGamble, a video recognition
system that assesses players as they play a game of blackjack.
To create personalized hold% of any player, we need to
understand 1) betting behavior/patterns, 2) player decisions vs.
the optimal strategy, and 3) likelihood of fraud. A foundational
step in this journey is to digitize the gameplay. Unlike slot
machines where data per handle pull can be analyzed, table
games cannot access this per hand play.
We propose a video recognition solution that digitizes the
table gameplay. Proposed solution is built using a multi-stage
machine learning pipeline that does instance segmentation
* indicates equal contribution
† this work was done when author was at ZS Associates
(chips & cards) along with predicting secondary image at-
tributes (chip denomination, card face value, orientation and
much more). This digitized information opens up multiple
analytical avenues that can help creatively assess value and
market a table game player.
Proposed system was piloted with a live executive audience
of an industry veteran entertainment client, where the execu-
tives were invited over in multiple sessions to play 15 hands
of blackjack per player and the system recorded and analyzed
the bets they made, the cards that were dealt to them, and
the decisions they took. All this information was processed
in real time. At the end of each session, the instant analysis
results: average bet, game outcomes, blackjack skill level and
evaluation of potential card counting were shared.
II. MOTIVATION
When a player games at a slot machine, the casino has
perfect information about that player’s wager, the number of
handle-pulls, length of play. However, if a player prefers to
play a table game, the casino must use guesswork from dealers
and supervisors to estimate the player’s value to the casino -
which may be off by huge margins (as high as 90%). This
margin of error can significantly distort the level of marketing
reinvestment which the player receives in the form of free play,
giveaways, comps. Overestimating a player’s value can destroy
the lifetime profitability of the casino and underestimating it
can negatively impact the player’s loyalty.
While accurate main bet wager valuation remains a priority,
not all bets are equal, and side bet hold% can be 10× main bet.
To exemplify, for a basic blackjack having main bet strategy
only, casinos have a hold% of 0.5% while on a buster blackjack
with side bet [1], casino’s hold can go as high as 6%.
In addition to wager size and bet type, player decisions
also profoundly impact player valuation. To quantify it, we
ran Monte-Carlo simulations by extending the work of Se-
blau’s blackjack simulator [2] to understand the impact of
player decisions on theo
1
they generate. With game rules
and strategies as specified in [3], we simulated 60 hands/hour
with $50 wagers in each hand and understood the impact on
1
Theo is the theoretical value that a player will lose if they played for a
certain amount of time with a certain number of bets in a game.
arXiv:2012.08011v1 [cs.CV] 14 Dec 2020

theo by varying the gameplay strategies. If currently available
hardware systems were to evaluate such a player, such a
system would state this player as $49 average bet player, while
in reality player’s decisions altered the casino hold and taking
suboptimal strategies increases the theo by at max by ∼ 8.9×
which makes this suboptimal player more profitable to the
casinos. The impact of different blackjack strategies on the
player’s theo can be seen in Figure 1. Thus, effective gameplay
valuation will help casinos calculate a personalized hold%
based on the player’s observed strategy (skill) and segment
players by skill level and ultimately separate skill from luck.
Fig. 1. Impact of various blackjack strategies on a player’s theo compared
with currently available systems.
III. RELATED WORK
Computer vision gives an ideal, simple, fast, and inex-
pensive solution. However, there is little-published work in
the direction of unlocking player intelligence. Notably, since
the early 2000s, we see some advancements as we see a
combination of hardware and software used to solve this.
Below sections describe the efforts taken by the industry.
A. RFID Based Methods
Recent efforts from large entertainment houses are focused
on radio-frequency identification tags (RFID) embedded in
chips [4], [5]. We also did an empirical study at our client’s lo-
cation to assess player’s value using their existing RFID setup
as described in the Section II. Our findings suggested that even
hardware based systems have a 2% error (Figure 1). Despite
high accuracy, these solutions are not as prevalent because
they are prohibitively expensive and susceptible to fraud and
table-failure. Due to the blind broadcast nature of RFID, these
systems have been plagued with security concerns that players
would be able to broadcast a compromised signal, possibly
representing different chip denominations. While encryption
within the chips can provide an extra layer of security, this
dramatically increases the cost of each chip.
B. Computer Vision Based Methods
Clear Deal [1] used a combination of line detection, corner
detection and template matching to detect the value of the
cards as they are dealt throughout the game. The system
analyzed the quality of the shuffle carried out by the dealer by
comparing the deal across hands and detected card counting
by monitoring game decisions and comparing them with basic
strategy. However, this system had no way of monitoring the
size or variation of bets placed by the player.
Zaworka [6] tracked a Blackjack game by detecting cards
and players’ chip stacks as they bet, in real time. Overall
accuracy was 97.5% for detecting playing cards and chip
stacks, even with occlusion. However, the system only detected
the presence, not the values of cards and chip stacks. The
system used an electronic chip tray, which is an additional
investment across the enterprise. Template matching and a
combination of heuristics were used by Zheng [7] to match
cards invariant to rotation, but the technique did not handle
face cards well, did not model chips or bet sizes, and did not
produce a final usable system.
Generic object recognition has seen much use in the past
decade [8]. There are a number of discriminative approaches
proposed, perhaps the most common of which is the use of
invariant features [9], most notably the scale invariant feature
transform (SIFT) [10].
C. Other Commercially Available Methods
There are a few commercial attempts to market systems for
card counting monitoring. Tangam Gaming [11] produces an
automated card recognition system that requires the use of
specialized hardware such as RFID. The MindPlay21 system
relied on a range of specialized hardware which included 14
cameras, invisible ink, and RFID tags. Cameras were used
to scan the cards as they were dealt, as each card had been
marked with a unique barcode painted in special ink [12].
The cost of $20,000 per table, the unreliable components and
the slow speed of operation led to the company going out
of business in 2005. There are many patents also suitably
guarding this space thereby inhibiting a large-scale commercial
solution [13]–[15]. In the 2017 edition of the G2E conference,
VizExplorer [16] launched its new tableViz
TM
with ChipVue
TM
product, and this solution provided reliable bet recognition
data for a few table games. tableViz
TM
system struggled
to maintain high-accuracy and wasn’t developed actively,
whereas ChipVue
TM
product released a new version in 2019
edition of G2E conference [17] that continues to just provide
accurate bet assessment.
D. Comparison to our System
The maturity of solutions in terms of accurate card detec-
tion, coupled with building a gameplay understanding is still
in its nascent stages for the past two decades.
By tailgating on the recent advancements in Deep learning
focused with attention to the Convolution neural networks
to solve the problem of assimilating strategic gameplay in-
formation at the player level, we propose a system called
DeepGamble with the reference solution architecture (Refer
Figure 2).
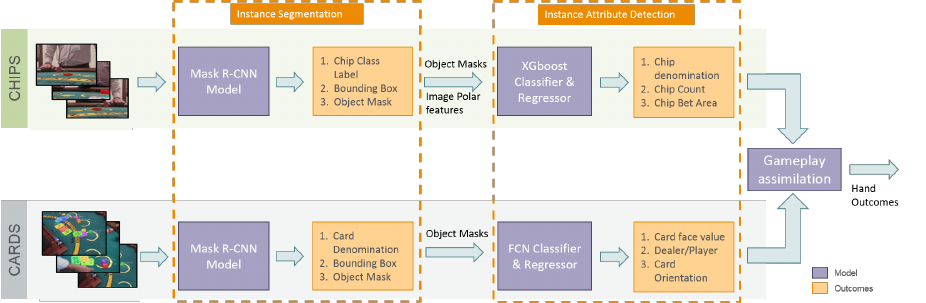
Fig. 2. DeepGamble Model Pipeline. The instance segmentation pipelines have two streams - chips and cards detection. Instance attribute detection module
for chips uses XGBoost, and for cards, a single FCNN is used. Results are used for gameplay assimilation.
IV. DEEPGAMBLE
In this section, we outline all the components of the
DeepGamble system. Our system understands the hand out-
comes of a game of blackjack by understanding multitude of
objects placed on the table and their spatial relationships in
three sequential steps 1) Instance Segmentation, 2) Instance
Attribute Detection, and 3) Gameplay Assimilation.
A. Instance Segmentation
To build the gameplay understanding, we focus on detecting
via two vantage points - chipboard viewpoint (using Chip de-
tection pipeline) and overhead viewpoint (using Card detection
pipeline) as stated in the Figure 2. This task of segmentation is
accomplished using Mask R-CNN - an instance segmentation
network. We refer the readers to the to the original publication
for architectural and technical details [18].
Our system segregated the detection of chips and cards via
two separate models as through a single viewpoint we cannot
capture the more delicate nuances of the objects. To elaborate,
from the chipboard viewpoint, we cannot necessarily see all
the cards that are kept close to the players, whereas, from the
overhead viewpoint, we do not see the depth of the main bet
chips for the players. Hence trade-off of multiple models vs.
accuracy of detection led us down the path of separate models
as our design principle.
We did domain-based fine-tuning for the two separate
Mask R-CNN models prepared for chip and card dataset to
identify the chip stacks with their denomination and cards
with their face-value respectively, as shown in Figure 2.
Training instance segmentation models: We trained two
separate Mask R-CNN models: 1) chip detection model, and
2) card detection model by using the weights of the model
pre-trained on COCO dataset [19], [20]. The Mask R-CNN
models were trained using Keras 2.1 functional API [21]
running on Tensorflow backend [22] with NVIDIA CuDNN
GPU acceleration libraries [23]. We used SGD algorithm to
train 80 epochs (stopped using early stopping and scheduled
with learning rate scheduler that uses an inverse time decay
schedule with initial value of 0.01) for all images in the
training set. We used four P100 Nvidia GPUs to train the
model with the throughput of two images per GPU in a batch,
thus effectively using a batch size of 8, and also included the
combination of early stopping and model checkpoint callbacks
to reduce overfitting.
Additionally, to make the training more robust, we per-
formed real-time data augmentation to the image using Imgaug
[24], where each image was randomly applied one of the
transformations: contrast normalization, gaussian blur, rota-
tion, translation, or shear.
B. Instance Attribute Detection
Post instance identification, predicted masks and derivative
features are passed on to their respective second layer models
for further instance attribute prediction. We predicted the chip
count of stack, the card orientation and the relative placement
of objects on the table.
Secondary attributes for chip detection module: We
used eXtreme Gradient Boosting (XGBoost) algorithm [25]
for counting the number of chips in a stack and classifying
the bet placement area (main bet, side bet, or others). Both
the models expected a set of derived features from the first
stage model - namely width and height of the chip stack
and relative polar coordinates (radius, theta) as highlighted
in Figure 2, these features were calculated using the masks
generated from the first stage model.
Secondary attributes for card detection module: We
created a six layer Fully Convolution Neural Network (FCNN)
from ground up for detecting the hand (player(s) or dealer), the
orientation of cards (vertical/horizontal) and placement area of
chips (main bet/side bet). Detection of placement of chips in
the bet areas is far more vivid and clear from the top vantage
point as opposed to from the chipboard level.
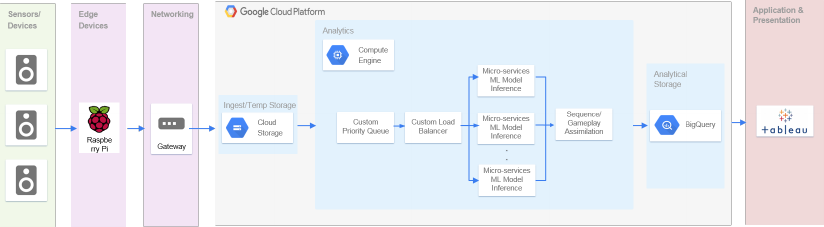
Fig. 3. DeepGamble System Architecture. High-resolution cameras, Raspberry Pis are connected via a gateway to the Google Cloud Platform where inference
models are deployed as micro-services to perform inference in real-time. After assimilating the game play, results are pushed to Google BigQuery for further
analysis and real-time dashboards are generated.
C. Gameplay Assimilation
Both Instance segmentation and Instance attribute detection
provided a frame level analysis of the objects - bets placed
and cards dealt. It became imperative to create a unified view
of the hand from individual frame level results to understand
the gameplay and evaluate the player decisions. This step
integrated the outputs of the chip and card models from
previous steps and stitched the predicted images to create a
retrospective hand replay video.
Chips: To estimate the player’s initial bet value, we majority
voted on the predicted value of the main bet after we have
received at least 70% of the frames for each player (to factor
in for the fact that the images might be lost in transit).
Cards: Unlike chips, where we work with most frames, for
cards we need all frames of the hand to start the sequence
assimilation as the order of the cards dealt serves as an
essential feature in assessing player’s skill. Per the rules of
the game, we know that each player will be initially dealt
two cards in a circular fashion until the dealer’s first card is
revealed.
A tricky situation arises as previous cards dealt to the
players become partially obstructed upon placement of a new
card, so we only have a few frames window where we observe
the cards unobstructed. Hence, we majority voted on the cards
detected in each frame in its window of unobstructed view.
The trigger to majority vote happened only at state change of
cards on the table.
Post the first two cards, the gameplay progression can take
multiple paths as players have an intervention and a decision
to make. At this point, we evaluate each player’s decision and
strategy.
The gameplay naturally shifts to the dealer after the dealer’s
hole card is revealed and they start to draw their cards. We
used the spatial features of the bounding box to detect the
sequence of the dealer cards as they are generally translated
on the axis to accommodate a new card being dealt. The hole
card is opened to the left of the first card. Dealer’s third card
and others are dealt to the right of the first card. Due to the
overhead camera position, this spatial distance decreased as we
moved from left to right thus enabling us to identify the correct
card. Per the table game, usually the dealer stands on 17s, and
no further cards are dealt. At this point, we evaluated the game
outcomes and assessed the net win/loss amount. (Evaluation
detailed in Section VII-A)
V. SYSTEM ARCHITECTURE
We now describe the system architecture of our solution
DeepGamble. Our solution is created and deployed on scalable
Google Cloud Platform and is designed to operate in real
time. Figure 3 outlines a high-level system architecture for
DeepGamble. The blackjack table was outfitted with small,
inexpensive computing devices (raspberry pi), high-resolution
cameras, and other supporting hardware. The cameras were
secured on the table by housing them in 3D printed holders.
The workflow of the DeepGamble system consists of the
following steps as shown in Figure 3:
1) The cameras connected to the Raspberry Pis capture the
images at 10 fps.
2) The images from all sensors are brought to local network
storage, and from there these images are uploaded to
Google Cloud Storage.
3) The pointer reference to these images are pushed in a
priority queue to make sure that even if an image from
the previous hand arrived late due to network issues, it
gets processed first.
4) The inference models are deployed as micro-services
which pulls the enqueued pictures with the help of a
custom load balancer and process them parallelly in an
asynchronous manner.
5) Each frame as it gets predicted is pushed to Google
BigQuery and post completion of a hand the frames are
assimilated to create a unified understanding of the hand.
6) The application layer accesses the consolidated hands’
data from BigQuery to power our proposed applications.
The asynchronous, parallel and scalable nature of our cloud-
based architecture enable us to generate real-time inferences.
VI. EXPERIMENTS
In this section, we present an extensive evaluation of
DeepGamble. First, we describe the dataset used for training
and evaluation. Then, we discuss metrics used for evaluating

each component and overall pipeline of DeepGamble. Finally,
we share the performance of DeepGamble system on holdout
dataset.
Fig. 4. Annotation example for overhead POV. Ten of spades is annotated as
- {10, h, p2} - card denomination, card orientation, card location (player 2).
Side bet is annotated as - {chips, s, p2} - chip flag, chip stack bet area, chip
stack location
A. Dataset
The open-source labeled datasets did not contain our
domain-specific data elements i.e, chips and cards. Hence we
resorted to using transfer learning. We leveraged the COCO
public dataset [19] for object detection and segmentation. We
captured and annotated ∼900 images from our two different
points of views - chipboard and overhead POV. We used
open-source labelme [26] software to annotate polygons for
the objects in each frame.
Chipboard POV: Two cameras were installed on the table
to capture the bet area of their corresponding player with a
resolution of 2000 ∗ 1006 pixels. Each object polygon was
assigned a comma separated string label with three attributes:
1) Chip stack color (red, green, blue, or black), 2) Chip stack
bet area (main, side, or others) and 3) Chip stack count.
Overhead POV: The camera installed on the tower captures
the whole table from the top with the same resolution as
chipboard view. The polygon annotation string also had three
attributes: 1) Card denomination (1 to 13) OR a chip flag in
case of chip stack, 2) Card orientation (horizontal or vertical)
or chip stack bet area (main or side) and 3) Card or chip stack
location (player or dealer). These attributes were extracted
from the string while training, an example of the annotation
is shown in the Figure 4.
Pipeline validation dataset: To evaluate the performance
of our two independent pipelines (Chip detection & Card
detection as shown in the Figure 2) we collected images based
on a predefined set of object combinations.
For Chip detection pipeline, we captured 1200 images with
all the possible combinations of different denomination chips
(red, green, blue & black). By making an exhaustive validation
dataset, we were able to find various nuances in the model
and training. One example could be the misclassification of
black chips as red due to the high frequency of red chips in
the training data. Also, the dim lighting of the casino floor
confuses the red chips with black.
Similarly, for Cards pipeline, we recorded 150 hands
(∼70 images per hand) translating to 600 unique gameplay
scenarios with each card value in obstructed and unobstructed
positions. The table sizes were varied which caused a few
player cards to be misclassified as dealer cards and vice-versa.
As the misclassification generally happened post the fourth
card was dealt to a player/dealer, we used the nature of the
game and dealing to allocate the cards to the player or dealer
correctly.
B. Evaluation & Results
We will now look at the evaluation of the individual
components of the model pipeline and then move onto the
overall evaluation of the two independent sub-pipelines(chip
and card). Since there is very less published work on table
gaming systems which are capable of digitizing the whole
game of blackjack, we relied on our industry understanding
to evaluate our model. However, we compared our chip and
card detection pipeline with the work done by Krists et al.
[27] which was evaluated in a constrained setup.
Evaluation metric of instance segmentation: For instance
segmentation task, the standard metric for evaluation is a
multi-task loss on each sampled ROI. It is defined as:
L = L
cls
+ L
box
+ L
mask
(1)
The classification loss L
cls
, bounding-box loss L
box
and
mask loss L
mask
are identical as those defined in [18].
Evaluation metrics for instance attribute detection: We
predicted four attributes from the second layer models, two
from both the pipelines consisting of classification and regres-
sion. For chip stack bet area, card location and card orientation
we used multi-class logarithmic loss, and for the chip stack
count, we used root mean squared error (RMSE) to evaluate
their performance.
After tuning each component at the micro level, we
tested the performance of the two pipelines on our synthetic
validation dataset. We devised metrics of business significance
that evaluated the performance of the pipelines as a whole.
Evaluation of Chip detection pipeline: To holistically
evaluate the Chip detection pipeline, we used the chip evalua-
tion data set as mentioned in Section VI-A. We evaluated the

Fig. 5. Gameplay Evaluation: Player’s bets, card sequence, initial strategy and outcome of the player(s) & dealer are evaluated.
main bet accuracy for the overall bet and also across individual
color in the stack as shown in Table I. Krists et al. [27] used
a BumbleBee2 stereo camera to calculate the size of the bet.
Even though they were able to achieve 99% accuracy on a
small dataset, their chip setup was limited to a single color
stack whereas our model achieved 95% bet color detection
accuracy on a realistic setup (with multiple color stacks in
main bet area).
TABLE I
BET DETECTION ACCURACY
Main Bet (overall & color wise) Accuracy
Overall Stack 95%
Red Stack 98.83%
Green Stack 99.6%
Blue Stack 100%
Black Stack 99.5%
Although our bet accuracy results were satisfactory, we
wanted to understand the effectiveness of our chip detection
pipeline in terms of bet size calculation. Hence, we further
evaluated the mean absolute percentage error (MAPE) of main
bet chip count and value-weighted chip count (since an error
in a higher denomination chips would be less desirable) as
shown in Table II. Our final model had an error of 7.35% on
value weighted chip count (same as total bet value), we also
believe that our chip evaluation can act as a strong baseline
to benchmark progress.
TABLE II
BET VALUE MAPE
Main Bet(Count & Value weighted) MAPE
Chip count 7.12%
Value weighted chip count 7.35%
Evaluation of Card detection pipeline: For cards, we were
interested in identifying the card outlines, the accuracy of the
card position, orientation and the face value of the topmost
unobstructed card only as we always had few frames in which
a card was visible with no obstructions. To evaluate the card
pipeline, we used the card evaluation dataset as mentioned
in VI-A. We looked at the accuracy of identifying the card
outline, the unobstructed card value - separate by face cards
and non face cards (value≤10). For face cards - J, Q, K -
as long as the face card was identified, it was marked as
accurate as these cards hold the same numerical value of 10 in
blackjack and do not affect the game outcome. It was essential
to correctly identify the player/dealer cards and the orientation
(horizontal or vertical) of the card as these affect the outcome
of the hand - Win/Loss/Stand/Push. The accuracy numbers for
150 hands are listed in Table III.
TABLE III
CARD DETECTION ACCURACY FOR DIFFERENT COMPONENTS OF
DEEPGAMBLE AND THE MODEL PROPOSED BY KRISTS et al. [27].
Accuracy Metrics DeepGamble Krists et al.
Single Card Outline 100% 100%
Multiple Card Outline 100% 100%
Overall Card Value 98% 99.75%
Face Card Value 100% –
Non-face Card Value 96% –
Player Card Position 99% –
Dealer Card Position 98% –
Card Orientation(h or v) 95% –
In a parallel system [27], tested under controlled environ-
ment - with only 400 images; essentially testing each card
10 times - the author reported a card face value accuracy of
99.75%. Whereas our proposed system, which was tested in
near-real life scenario - with multiple combinations of actual
players and dealers achieved a comparable accuracy of card
face value of 98% and in few nuances even higher. Currently,
there are no empirical benchmarks for evaluating the additional
accuracy metrics like - side bets, card positions, orientation
and game outcome.
For the side bets, we considered a boolean flag for whether a
side bet was placed or not. We were 98% accurate in detecting
the side bet for players.
VII. APPLICATIONS
In this section, we will discuss the application stack built
upon the computer vision pipeline. Modules in application
stack work in parallel and leverage the predictions of the hands
stored in Google BigQuery to create analytical dashboards.
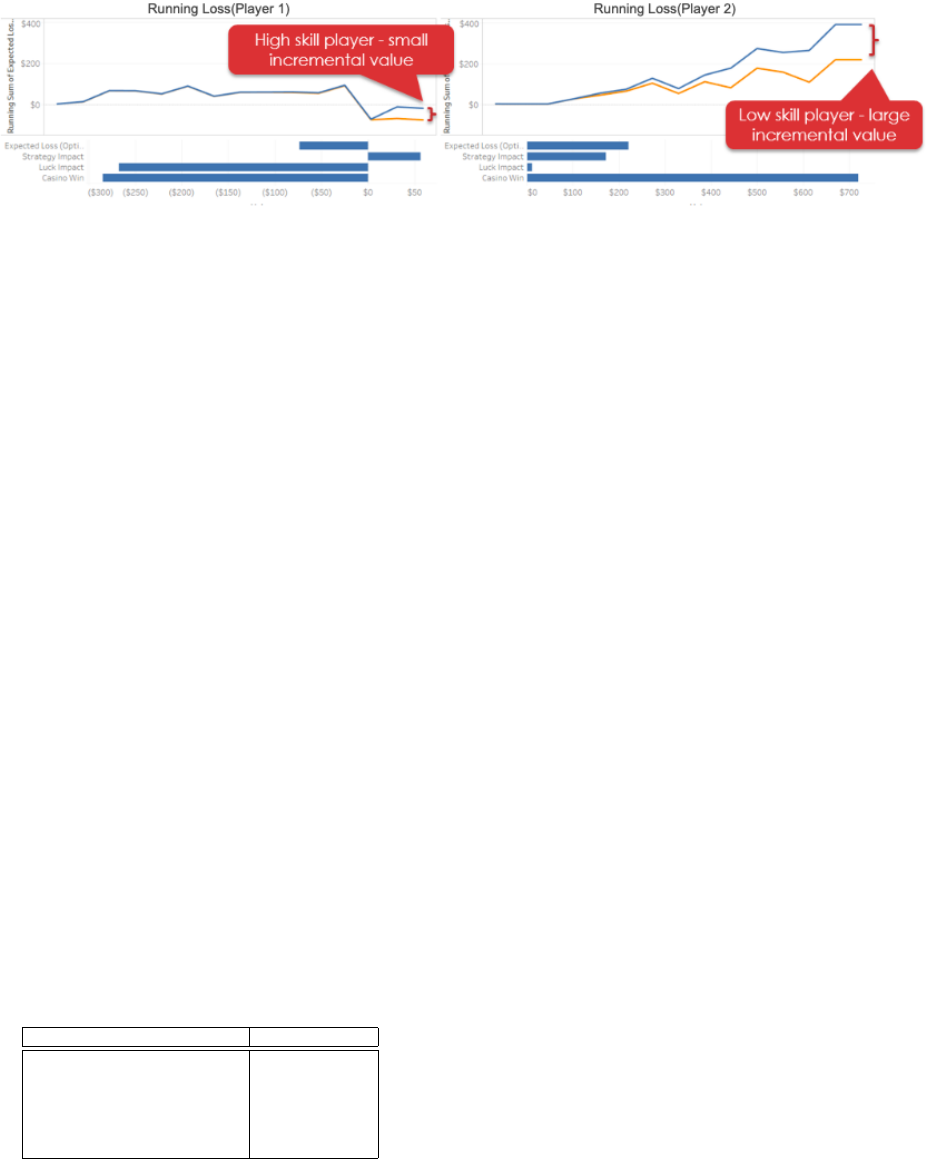
Fig. 6. Player skill dashboard: The orange line is the optimal strategy, and the blue line is the player’s actual strategy. As Player 1 follows the optimal
strategy for most hands and deviates very less from it, he is not penalized for his strategy, but as he had better luck, he ends up with an overall win. Player
2 deviates from the optimal strategy, is penalized for his low skill and thus ends up offering the casino a large incremental value from the expected loss.
A. Gameplay Evaluation
A player has to take a strategic decision post two cards
are dealt to them. The decision could be whether to hit for
another card, stand on his current hand, double his bets for
the third card or split the hand and play two hands. We will
now describe the markers we used to identify the player’s
strategy:
• Hit - If the third card dealt to the player is placed in the
vertical orientation.
• Double Down - If the third card dealt to the player is
placed in the horizontal orientation, and there were two
chip stacks in the main bet area.
• Split - A player is only allowed to split if their first two
cards are of the same face value. They also placed another
chip stack in the main bet area, and both cards were
visible in the unobstructed view.
• Stand - In case the player decided to stand on their
current hand, they will not be dealt a third card.
The aim is to reach closer to the total of 21 on your hands,
without going over and making sure the player’s total is higher
than the dealer’s hand total. Usually, the dealer must draw to
a total of 17. Screenshot of the evaluated gameplay - hand
outcome, strategy and net win/loss of a hand is shown in
Figure 5. The hand outcome based on the dealer and player
hand’s total is shown in Table VII-A.
TABLE IV
OUTCOME BASED ON PLAYER AND DEALER HAND TOTAL
Total Player Outcome
Player > 21 Bust
Player > Dealer Won
Player = Dealer Push
Player < Dealer Loss
Dealer > 21 and Player ≤ 21 Won
Player Hits 21 on First 2 cards Blackjack
B. Skill Evaluation
An ideal or basic strategy is defined using the player’s first
two cards and dealer’s face card. Such a strategy dictates that
given a situation, should we hit, stand or double-down. This
ideal strategy can be derived by simulating a large number of
hands. These set of rules or strategy were simulated using the
Seblau’s blackjack simulator [2] to find the optimal pathway.
The skill level of a player could be assessed based on their
deviation from this ideal strategy. Adherence to the ideal
strategy will deem the player adroit. Figure 6 compares two
players and their skill.
Skill differences dramatically impact player’s value that’s
why high-rollers are closely monitored by the floor supervisors
for more personalized evaluation. However, today the same
hold is assumed for all the ordinary players since there is no
actionable and scalable intelligence.
C. Card Counting Detection
The basic theory behind card counting is simple – the player
is at an advantage when more face cards are remaining in the
deck because the dealer is more likely to bust. A player can
take advantage of this fact by keeping track of the cards that
have come out of the shoe and adjusting their bet accordingly.
The most common system of card-counting is called the
“high-low” system [28]. Players determine their bet size using
the scaled count [28] at the start of each hand, betting more on
hands that start with a higher scaled count to lower the house
advantage. To determine whether a player is counting cards,
we have to look at the relationship between the scaled count(x)
and the hold percent(y) of a casino at any given point. This
was achieved by using the Seblau’s blackjack simulator [2],
we generated the data for the variation in scaled count(x) and
its effect on the hold percentage(y). It was an extremely close
linear fit(R
2
= 0.98326). Using the linear relationship in Eq.
2, we can calculate the expected hold of every hand given the
scaled count(x).
y = −0.00474x + 0.00512 (2)
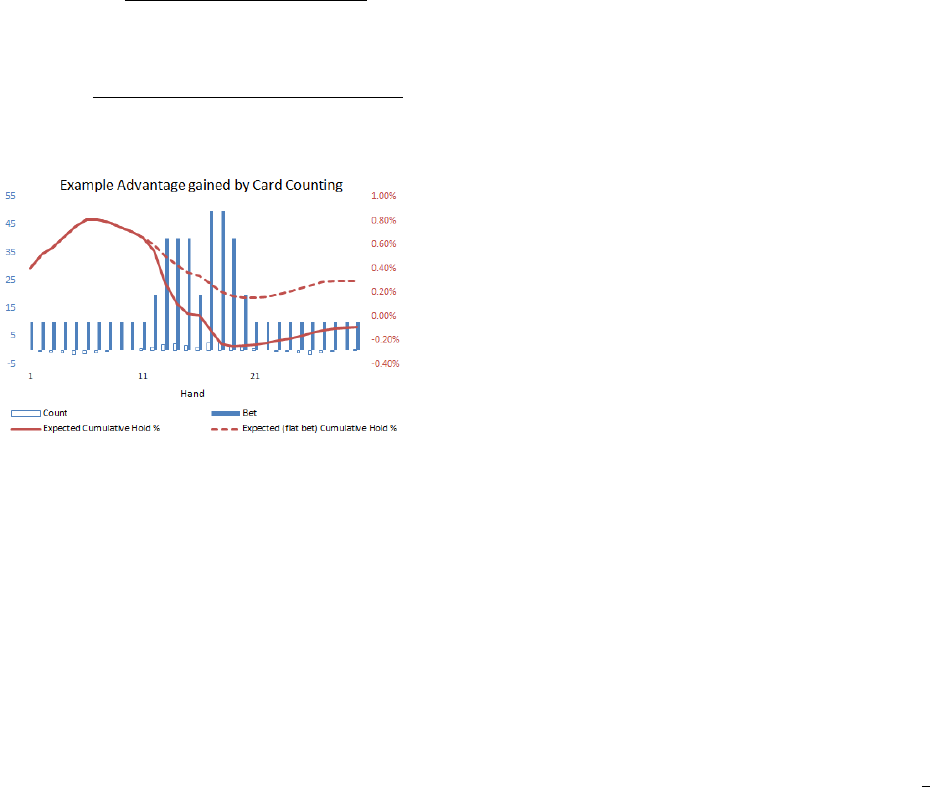
Testing the card counting module: We designed an ex-
periment where a player counted the cards and placed the bet
higher as the scaled count rose in the player’s favor. We com-
pared this player’s trajectory with a flat bet player’s journey
(a constant bet for every hand) to evaluate the competitive
advantage gained as shown in Figure 7.
The cumulative expected hold percent(H
player
) and flat bet
cumulative hold percent(H
flatbet
) for N hands are calculated
using Eq. 3 & Eq. 4 respectively.
H
player
=
P
N
i=0
Bet
i
∗ ExpectedHold
i
T otalAmountBet
(3)
H
flatbet
=
AverageBet ∗
P
N
i=0
ExpectedHold
i
T otalAmountBet
(4)
Fig. 7. The gap between these two lines isolates the advantage the player
created by tracking the count and betting accordingly. In this particular case,
the card counting and bet variation shifts the advantage for the house to a
slight advantage for the player.
VIII. CONCLUSION
In this work, we presented a Mask R-CNN based approach
for a new domain of assessing the player’s worth as they
play a game of blackjack. Our method, DeepGamble, takes
images from two viewpoints - chipboard and overhead, to
predict average bet, game outcome, blackjack skill level and
the likelihood of card counting in real time. The proposed
method can easily adapt to different blackjack tables with
different payout rules. Minimal fine-tuning might be needed
as we change scales and perspectives. Extensive experiments
on multiple hands (∼ 150) demonstrated the efficiency and
effectiveness of the proposed method over the state-of-the-art.
We do understand that as dealing style varies from dealer
to dealer, we may have a lot of occlusion in the frames due to
dealer’s hand, which currently our model is able to discard as
fewer feature maps in Mask R-CNN fire on hands of different
sizes. In future work, we want to directly embed the occlusion
of hand as a weighting layer into Mask R-CNN. It will produce
different weights to combine feature map outputs at every pixel
depending on the occlusion.
ACKNOWLEDGMENT
The authors would like to thank Arun Shastri, Rasvan
Dirlea, Mike Francis, Akshat Rajvanshi, Manoj Bheemineni,
Brendan Riley, Geoff Cohn, Jayendu Sharma, Thompson
Nguyen and others who contributed, supported, guided and
collaborated with us during the development and deployment
of our system.
REFERENCES
[1] W. Cooper and K. M. Dawson-Howe, “Automatic blackjack monitor-
ing,” in Proceedings of Irish Machine Vision and Image Processing
Conference (IMVIP 2004). Dublin, Ireland: Association for Computing
Machinery, 2004, pp. 248–254.
[2] S. Auberger, “Blackjack-simulator with omega ii card counting,” 2018.
[Online]. Available: https://github.com/seblau/BlackJack-Simulator
[3] S. Michael, “Buster blackjack side bet house advantage study,” https:
//wizardofodds.com/games/blackjack/side-bets/buster-blackjack/, 2016.
[4] K. Hecht and L. Storch, “Sequenced antenna array for determining
where gaming chips with embedded rfid tags are located on a blackjack,
poker or other gaming table and for myriad other rfid applications,” U.S.
Patent: US20070035399A1, 2005.
[5] H.-S. Yang and C. S. Pyo, “System and method for managing casino
chip using rfid,” U.S. Patent: US8591320B2, 2012.
[6] A. Zaworka and S. Scherer, “Machine vision driven real-time blackjack
analysis,” in Proceedings of 24th workshop of the AAPR, 2000.
[7] C. Zheng and R. Green, “Playing card recognition using rotational
invariant template matching,” in Proceedings of Image and Vision
Computing New Zealand, 2007.
[8] J. Ponce, M. Hebert, C. Schmid, and A. Zisserman, Toward Category-
Level Object Recognition. Springer, 2006, vol. 4170.
[9] K. Mikolajczyk and C. Schmid, “A performance evaluation of local
descriptors,” IEEE Transactions on Pattern Analysis and Machine Intel-
ligence, vol. 27(10), pp. 1615–1630, 2005.
[10] D. G. Lowe, “Distinctive image features from scale-invariant keypoints,”
International Journal of Computer Vision, vol. 60, pp. 91–110, 2004.
[11] “Tangam systems,” http://tangamgaming.com/.
[12] T. Daniel, “Who’s holding the aces now?” http://blackjackuniverse.com/
pages/news/mindplay.html, 2003.
[13] S. E. Inc, “Casino table monitoring/tracking system,” Canada Patent:
CA2463254C, 2002.
[14] S. G. Inc, “Method and apparatus for using upstream communication in
a card shuffler,” U.S. Patent: US10226687B2, 2016.
[15] I. G. T. SHFL Enterteiment Inc, “Gambling chip recognition system,”
U.S. Patent: US5781647A, 1997.
[16] VizExplorer, https://www.vizexplorer.com/.
[17] A. Labs, https://www.chipvue.com/.
[18] K. He, G. Gkioxari, P. Doll
´
ar, and R. B. Girshick, “Mask r-cnn,” 2017
IEEE International Conference on Computer Vision (ICCV), pp. 2980–
2988, 2017.
[19] T.-Y. Lin, M. Maire, S. J. Belongie, B. Lubomir D. title=Microsoft
COCO: Common Objects in Context, R. B. Girshick, J. Hays, P. Perona,
D. Ramanan, P. Doll
´
ar, and C. L. Zitnick, in ECCV, 2014.
[20] W. Abdulla, “Mask r-cnn for object detection and instance segmentation
on keras and tensorflow,” https://github.com/matterport/Mask
RCNN,
2017.
[21] F. Chollet et al., “Keras,” https://keras.io, 2015.
[22] M. Abadi, A. Agarwal, P. Barham, E. Brevdo, Z. Chen, C. Citro, G. S.
Corrado, A. Davis, J. Dean, M. Devin, S. Ghemawat, I. Goodfellow,
A. Harp, G. Irving, M. Isard, Y. Jia, R. Jozefowicz, L. Kaiser,
M. Kudlur, J. Levenberg, D. Man
´
e, R. Monga, S. Moore, D. Murray,
C. Olah, M. Schuster, J. Shlens, B. Steiner, I. Sutskever, K. Talwar,
P. Tucker, V. Vanhoucke, V. Vasudevan, F. Vi
´
egas, O. Vinyals,
P. Warden, M. Wattenberg, M. Wicke, Y. Yu, and X. Zheng,
“TensorFlow: Large-scale machine learning on heterogeneous systems,”
2015, software available from tensorflow.org. [Online]. Available:
http://tensorflow.org/
[23] S. Chetlur, C. Woolley, P. Vandermersch, J. Cohen, J. Tran, B. Catanzaro,
and E. Shelhamer, “cudnn: Efficient primitives for deep learning,” CoRR,
vol. abs/1410.0759, 2014.
[24] J. Alexander, “Imgaug,” https://github.com/aleju/imgaug, 2018.
[25] T. Chen and C. Guestrin, “Xgboost: A scalable tree boosting system,”
in KDD, 2016.
[26] B. C. Russell, A. Torralba, K. P. Murphy, and W. T. Freeman, “Labelme:
A database and web-based tool for image annotation,” International
Journal of Computer Vision, vol. 77, pp. 157–173, 2007.
[27] K. Zutis and J. Hoey, “Who’s counting? real-time blackjack monitoring
for card counting detection,” 10 2009, pp. 354–363.
[28] S. Michael, “Blackjack card counting strategy, high low,” https://
wizardofodds.com/games/blackjack/card-counting/high-low/, 2008.
