
11646 IEEE TRANSACTIONS ON VEHICULAR TECHNOLOGY, VOL. 68, NO. 12, DECEMBER 2019
A Cooperative Driving Strategy for Merging at
On-Ramps Based on Dynamic Programming
Huaxin Pei , Shuo Feng ,YiZhang, Member, IEEE,andDanyaYao, Member, IEEE
Abstract—Cooperative driving emerges as a promising way to
improve efficiency and safety for Connected and Automated Ve-
hicles (CAVs). Its key idea is to design a strategy to schedule the
movements of neighboring vehicles. The typical cooperative driving
strategies can be categorized into two categories. The first category
is optimal strategy, which aims to find the globally optimal passing
order of vehicles, but the computational cost of this strategy grows
significantly with the increasing number of vehicles. The second
category is sub-optimal strategy, which uses heuristic rules or other
methods to export an acceptable local optimal solution within a
limited computation time. However, there usually lacks a rigorous
theoretical guarantee of the performances, and further validation
is always required for practical applications. To overcome all these
limitations, a computationally efficient strategy is proposed to
obtain the globally optimal passing order based on dynamic pro-
gramming (DP). Specifically, the problem of merging at on-ramps
is resolved by a DP method, which uses the domain knowledge
to reduce the complexity by well defining the state space, state
transition, and criterion function. With the DP method, it is proved
that the globally optimal passing order can be obtained with the
quadratic polynomial computational complexity of O(N
2
),where
N denotes the number of vehicles. Simulation results demonstrate
the performances of the proposed strategy regarding optimality
and efficiency.
Index Terms—Connected and automated vehicles (CAVs),
cooperative driving, on-ramp merging problem, dynamic
programming.
I. INTRODUCTION
C
OOPERATIVE driving emerges as a promising method
to improve traffic efficiency and safety [1]–[7], which is
usually utilized in typical traffic scenarios, e.g., merging at on-
ramps. With the help of vehicle to vehicle (V2V) and vehicle
to infrastructure (V2I) technology, the key idea of cooperative
driving is to design a strategy to schedule the movements of
neighboring vehicles [8]–[14].
Manuscript received June 1, 2019; revised August 28, 2019; accepted October
7, 2019. Date of publication October 14, 2019; date of current version December
17, 2019. This work was supported in part by National 135 Key R&D Program
Projects under Grant 2018YFB1600600, and in part by the National Natural Sci-
ence Foundation of China under Grant 61673233. The review of this article was
coordinated by Dr. H. Zhang. (Corresponding authors: Shuo Feng; Yi Zhang.)
H. Pei, S. Feng, and D. Yao are with the Department of Automation, Tsinghua
Y. Zhang is with the Department of Automation, BNRist, Tsinghua Uni-
versity, Beijing 100084, and Berkeley Shenzhen Institute (TBSI) Shenzhen
518055, China, and also with Jiangsu Province Collaborative Innovation Cen-
ter of Modern Urban Traffic Technologies, Nanjing 210096, China (e-mail:
Digital Object Identifier 10.1109/TVT.2019.2947192
As pointed out in [4] and [8], the performance of a cooperative
driving strategy is mainly determined by the passing order of
vehicles which pass through the conflict zone. To optimize an ap-
propriate passing order, numerous cooperative driving strategies
have been proposed. According to their optimization methods,
most strategies can be classified into two categories:
1) Optimal strategy: This kind of strategies aims to find the
globally optimal passing orders of vehicles. The most straight-
forward strategy is to enumerate all possible passing order
to get the globally optimal solution, which suffers from the
high computational complexity. Li et al. [15], Müller et al.
[16] and Ahn et al. [17] formulated and solved the problem
as a mixed-integer linear programming (MILP) problem. Li
et al. [8] described the solution space of passing orders by a
spanning tree, and a pruning rule was proposed to search the
globally optimal passing order. Compared with the enumeration
strategy, these strategies can improve computational efficiency
by utilizing optimization methods or pruning rules. However,
the computational complexity still increases exponentially with
the number of passing vehicles, which makes these strategies
intractable for real-time applications, especially for high traffic
volume scenarios.
2) Sub-optimal strategy: To mitigate the limitation of the
optimal strategies, a sub-optimal strategy usually stops at a local
optimal passing order within a limited computation time. Ad hoc
negotiation based strategies use heuristic rules to get a feasible
passing order, e.g., autonomous intersection management (AIM)
[18], [19] and reservation strategy [20], [21], which instruct the
vehicles to pass through the conflict zone roughly in first-in-first-
out (FIFO) manner. However, as pointed out in [20], [22], [ 23],
ad hoc negotiation based strategy cannot effectively alleviate
traffic congestion in many situations. To keep a tradeoff between
traffic efficiency and computation flexibility, several cooperative
driving strategies t hat focus on local optimal passing order have
been recently proposed. Xu et al. [22] proposed a grouping-
based strategy, which instructed the vehicles to pass through the
conflict zone in the form of groups. By Monte Carlo tree search
(MCTS) algorithm, heuristic rules were developed to search a
local optimal passing order [23]. In [24], the conflicts between
different vehicles were calculated offline, which significantly
reduced the computational burden. Based on this fundamental
framework, the optimization of passing orders was formulated
as a non-linear mathematical program, which was solved by
a meta-heuristic Tabu search method. The major advantage of
these sub-optimal strategies lies at the computational efficiency.
To validate the effectiveness of these strategies, numerical
0018-9545 © 2019 IEEE. Personal use is permitted, but republication/redistribution requires IEEE permission.
See http://www.ieee.org/publications_standards/publications/rights/index.html for more information.
Authorized licensed use limited to: University of Michigan Library. Downloaded on July 01,2020 at 01:11:53 UTC from IEEE Xplore. Restrictions apply.
PEI et al.: COOPERATIVE DRIVING STRATEGY FOR MERGING AT ON-RAMPS BASED ON DYNAMIC PROGRAMMING 11647
experiments are usually utilized to show that these strategies can
obtain a good enough passing order. Nevertheless, there lacks a
rigorous theoretical guarantee of the performances and further
validation is always required for practical applications.
To overcome the above limitations, this paper proposes a glob-
ally optimal yet computationally efficient cooperative driving
strategy for merging at on-ramps. Specifically, a dynamic pro-
gramming (DP) based strategy is designed to obtain the globally
optimal passing order with a quadratic polynomial complexity
of the number of vehicles, i.e., O(N
2
), where N denotes the
number of vehicles. Compared with sub-optimal strategies, the
proposed strategy guarantees the optimality of the passing order
by the principle of optimality of the DP method [25], [26].
Compared with existing optimal strategies, the proposed strategy
significantly reduces the computational complexity by utilizing
the domain knowledge, e.g., the first-in-first-out principle in
the same lane. As pointed out in [25], [26], a DP method can
utilize domain knowledge of a specific problem to reduce the
complexity by well defining the state space, state transition, and
criterion function. For the merging at on-ramps problem, the DP
based strategy is designed as follows:
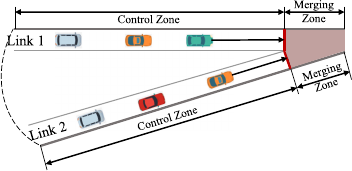
First, the state of the DP model is constructed as a triplet, i.e.,
s
i
(m
i
,n
i
,r
i
), where s
i
denotes the state at the i
th
stage, m
i
denotes the total number of vehicles at link 1 which have been
assigned right of way, n
i
denotes the t otal number of vehicles
at link 2 which have been assigned right of way, and r
i
denotes
the link ID of the vehicle with the right of way at this s tage.
By this state definition, Markovian property holds, and different
passing orders can reach the same state, which can extremely
reduce the number of states as a quadratic polynomial of the
number of vehicles. It is a significant improvement compared
with most existing studies, e.g., [8], [23], where the passing
orders are usually directly used as the state, and the number of
states increases exponentially with the number of vehicles.
Second, the state transition is well designed considering the
physical constraints of vehicles in the same lane (i.e., domain
knowledge). Specifically, under the assumption that lane-change
behavior is not allowed in the Control Zone, vehicles of the same
lane follow the first-in-first-out (FIFO) principle. It is the reason
why the defined state s
i
(m
i
,n
i
,r
i
) does not explicitly represent
the vehicle which is assigned the right of way at the current
stage. By determining the total assigned number of vehicles
at the s pecific link, the vehicle with the right of way can be
exactly specified. It significantly reduces the size of solution
space, compared with methods, which use the passing order as
the state and then prune the states violating the FIFO principle
in the same lane.
Third, the objective f unction regarding traffic efficiency is
established as the criterion function of the DP model to instruct
decision making. The recurrence relations of criterion function
are built based on the principle of optimality. For the states with
multiple predecessor states, the criterion function is utilized to
decide the optimal predecessor states. It guarantees the optimal-
ity of the passing order obtained by the DP method.
Theoretical analysis and simulations are proposed to justify
and validate the proposed DP based strategy. It is proved that
the proposed strategy has quadratic polynomial time complexity
of the number of vehicles. It is the theoretical foundation to
Fig. 1. Typical merging scenario.
overcoming the limitations of existing optimal strategies and
sub-optimal strategies. Moreover, the simulation results also
demonstrate that the proposed strategy can reach the globally
optimal passing order with much less computational time, com-
pared with existing optimal strategies.
The rest of this paper is organized as follows. Section II
formulates the merging problem as a general optimization prob-
lem. Section III proposes a DP based strategy to reformulate
and solve the merging problem. Section IV proves that the
DP based strategy is quadratic polynomial time complexity of
the number of vehicles. Then, we provide simulation results in
Section V. Finally, conclusion and further works are presented
in Section VI.
II. P
ROBLEM FORMULATION
A. Scenario and Notations
A typical highway on-ramp with a single lane in each link
is considered in this paper, as shown in Fig. 1. The light red
area is the Merging Zone where the vehicles on different links
may collide. Each link has a Control Zone where the vehicles
in the Control Zone are controllable. The length of the Control
Zone is defined as the distance from the entry of the Control Zone
to the entry of the Merging Zone. Moreover, some reasonable
assumptions are as follows:
Assumption 1: All vehicles are CAVs and controlled by the
system.
Assumption 2: Only a single lane in each link is considered,
and lane-change behavior is not allowed.
As presented in [6], [9], [22], [23], [27], most studies usually
assume that there is no lane-change behavior in the Control
Zone to simplify the problem. It is reasonable because vehicles
are usually not allowed to change lanes when approaching the
Merging Zone for safety consideration. Therefore, this paper
also assumes that the lane-change behavior is not allowed in the
Control Zone. Although the scenario is quite simple, it is the
foundation for cooperative driving in more complex scenarios.
Each vehicle is given a unique identity after arriving the
Control Zone, and vehicle i means the i
th
vehicle that reaches
the Control Zone. The vehicle identity sets of link 1 and link 2 are
denoted by M = {1,...,m} and N = {1,...,n}, respectively.
Moreover, the main notations in this paper are shown in details
in Table I.
B. Optimization Problem
Cooperative driving strategy for merging problem aims to
improve traffic efficiency by optimizing the passing order of the
Authorized licensed use limited to: University of Michigan Library. Downloaded on July 01,2020 at 01:11:53 UTC from IEEE Xplore. Restrictions apply.

11648 IEEE TRANSACTIONS ON VEHICULAR TECHNOLOGY, VOL. 68, NO. 12, DECEMBER 2019
TAB LE I
M
AIN NOTATIONS IN THIS PAPER
vehicles. To reach this goal, we formulate the objective function
as
J =maxt
assig n
i
,t
assig n
i
∈ T
assig n
. (1)
where t
assig n
i
denotes the access time to the Merging Zone
assigned to vehicle i. T
assig n
is the set of the access time of
all vehicles in the Control Zone. Obviously, J denotes the t otal
access time of the vehicles.
With the consideration of vehicle dynamics, the access time
t
assig n
i
has a lower bound t
min
i
t
assig n
i
≥ t
min
i
. (2)
t
min
i
=
⎧
⎪
⎪
⎪
⎪
⎨
⎪
⎪
⎪
⎪
⎩
v
2
0
+ 2a
max
· x
0,i
− v
0,i
a
max
+ t
0
, if
v
2
max
− v
2
0,i
2a
max
>x
0
.
v
max
− v
0,i
a
max
+
x
0,i
−
v
2
max
−v
2
0,i
2a
max
v
max
+ t
0
, otherwise.
(3)
Meanwhile, the access time has an upper bound t
max
i
.
t
assig n
i
≤ t
max
i
. (4)
t
max
i
=
⎧
⎪
⎪
⎪
⎪
⎨
⎪
⎪
⎪
⎪
⎩
v
2
0
+ 2a
min
· x
0,i
− v
0,i
a
min
+ t
0
, if
v
2
min
− v
2
0,i
2a
min
>x
0
.
v
min
− v
0,i
a
min
+
x
0,i
−
v
2
min
−v
2
0,i
2a
min
v
min
+ t
0
, otherwise.
(5)
where x
0,i
is the distance from the current location of vehicle i
to the entry of the Merging Zone. v
0,i
is the velocity of vehicle
i at the current time.
Suppose that vehicle i and vehicle (i + 1) are two consecutive
vehicles at the same link and vehicle i is physically ahead of
vehicle (i + 1). To avoid the rear-end collision at the Merging
Zone, we impose the rear-end safety constraint
t
assig n
i+1
− t
assig n
i
≥ Δ
t
1
. (6)
where Δ
t
1
is the minimal allowable safe gap for avoiding the
rear-end collision.
Suppose t hat vehicle i and vehicle j are two vehicles from
different links. To avoid the converging collision at the Merging
Zone, we impose the converging safety constraints
t
assig n
i
− t
assig n
j
≥ Δ
t
2
or t
assig n
j
− t
assig n
i
≥ Δ
t
2
. (7)
where Δ
t
2
is the minimal allowable safe gap for avoiding the
converging collision. Moreover, the vehicles from different lanes
need larger safe gap than the vehicles in the same lane, i.e., Δ
t
2
is larger than Δ
t
1
.
To formulate the whole optimization problem, some bi-
nary variables (K = {k
11
,...,k
ij
,...,k
mn
}, (i, j) ∈ M × N,
K ∈{0, 1}
m×n
) are introducing to impose the passing order
constrains
t
assig n
i
− t
assig n
j
+ M · k
ij
≥ Δ
t
2
. (8)
t
assig n
j
− t
assig n
i
+ M · (1 − k
ij
) ≥ Δ
t
2
. (9)
where M is a positive and sufficiently large number. Obviously,
k
ij
= 1 means vehicle i can enter the Merging Zone earlier than
vehicle j.
As the above descriptions, the whole optimization problem of
merging problem is formulated as
min
T
assign
,K
max t
assig n
i
subject to (2)(4)(6)(8)(9). (10)
Problem (10) is a mixed-integer linear programming (MILP)
problem. The branch-and-bound method can directly solve a
small scale MILP problem to obtain the globally optimal solu-
tion [28]. Note here that the size of the solution space of problem
(10) (i.e., the total number of the possible passing orders)
is 2
mn
. Hence the number of solutions grows exponentially
with the increasing number of vehicles. To reach the globally
optimal solutions based on current methods is an extremely
time-consuming process.
III. D
YNAMIC PROGRAMMING BASED STRATEGY
In this section, we reformulate the merging problem and
propose a DP based strategy to find the globally optimal passing
order with polynomial computational complexity. The rest of
Section III will elaborate on the DP method step by step. For
easier understanding, we take a simple example with four vehi-
cles in the Control Zone shown in Fig. 2(a) to present the process
of searching for the globally optimal solution.
A. Decision Variable
The problem of searching a passing order is equivalent to a
process of assigning the right of way of the Merging Zone to
the vehicles sequentially. Thus, problem (10) can be treated as
a sequential decision problem whose decision variable r
i
is the
right of way. Obviously, the decision variable has at most two
Authorized licensed use limited to: University of Michigan Library. Downloaded on July 01,2020 at 01:11:53 UTC from IEEE Xplore. Restrictions apply.
PEI et al.: COOPERATIVE DRIVING STRATEGY FOR MERGING AT ON-RAMPS BASED ON DYNAMIC PROGRAMMING 11649
Fig. 2. DP based cooperative driving strategy applied to a simple merging scenario with four vehicles.
possible values in a merging scenario, i.e., r
i
∈ RW = {1, 2}.
If r = 1, one vehicle at link 1 can obtain the right of way to enter
the Merging Zone. Similarly, if r = 2, one vehicle at link 2 can
get the right of way.
B. Stage Partition
Since only one vehicle can obtain the right of way at a time,
the process of assigning the right of way can be particularized
to a multi-stage decision process. At each stage, one vehicle in
the Control Zone can get the right of way. Meanwhile, it can be
assigned an access time to enter the Merging Zone.
Stage partition is used to portion the original problem as a
class of similar problems t o accommodate the framework of
DP. In our model, (m + n) stages are needed to accomplish the
assignment of the right of way for all vehicles, where (m + n)
is the total number of vehicles in the Control Zone. Considering
the i nitial stage, the stages can be numbered stage 0 through
stage (m + n). For example, since there are four vehicles in the
Control Zone in Fig. 2(a), the number of stages of this scenario
is five, as shown in Fig. 2(b).
To efficiently make decisions in a multi-stage decision pro-
cess, we adopt the DP method which regards the original prob-
lem as a class of similar problems to find the best decisions one
after another [25], [26]. In the rest of Section III, we will focus
on the formation of state space, state transition and criterion
function to construct the DP model.
C. State Space
The model is said to have (m + n + 1) stages. Hence, the state
space S of the DP model can be partitioned into (m + n + 1)
sets S
0
, S
1
, S
2
, ..., S
m+n
.
Let us take the triplet s
i
(m
i
,n
i
,r
i
) as a state,
s
i
(m
i
,n
i
,r
i
) ∈ S
i
. As shown in Fig. 2(b), m
i
denotes
the accumulated number of vehicles at link 1 that have been
assigned right of way (access time) up to stage i. Similarly,
n
i
denotes the accumulated number of vehicles at link 2 that
have been assigned right of way (access time) up to stage i. r
i
denotes the link ID of the vehicle with the right of way at s tage
i, r
i
∈ RW .
The initial state is given as s
0
(0, 0,r
0
), and the terminal state
set is S
m+n
= {s
m+n
(m, n, 1),s
m+n
(m, n, 2)}.Asshownin
Fig. 2(b), S
4
= {s
4
(2, 2, 1),s
4
(2, 2, 2)}.
D. State Transition
State transition is used to describe the transition of the right
of way between vehicles. The state transition equation emerges
after introducing the state variable and the decision variable
s
i
(m
i
,n
i
,r
i
)=g (s
i−1
(m
i−1
,n
i−1
,r
i−1
) ,r
i
) . (11)
where r
i
is the decision at stage i. g(·) is considered as the state
transition function that works as (as shown in Fig. 2(b))
i) if r
i
= 1 and m
i−1
<m, then
m
i
= m
i−1
+ 1,n
i
= n
i−1
.
ii) if r
i
= 2 and n
i−1
<n, then
m
i
= m
i−1
,n
i
= n
i−1
+ 1.
According to the above, the state and state transition possess
following properties.
Property 1: The state of the model is indeed a summary of
all past decision behavior [25]. In other words, the results of the
decisions from stage 1 to stage i are embodied in the parameters
(i.e., m
i
, n
i
, and r
i
) of state s
i
(m
i
,n
i
,r
i
).
Property 2: State transition only occurs between two adja-
cent stages.
Property 3: Different passing orders can reach the same state
in the state space. As shown in Fig. 2(b), both s
2
(1, 1, 2) and
s
2
(1, 1, 1) in stage 2 reach the same state, i.e., s
3
(2, 1, 1).
Authorized licensed use limited to: University of Michigan Library. Downloaded on July 01,2020 at 01:11:53 UTC from IEEE Xplore. Restrictions apply.
11650 IEEE TRANSACTIONS ON VEHICULAR TECHNOLOGY, VOL. 68, NO. 12, DECEMBER 2019
Property 4: Instead of using the state to explicitly represent
the vehicle with the right of way, by determining the accumulated
assigned number of vehicles at the specific link, the vehicle with
the right of way can be exactly specified. Thus, the passing orders
that violate the FIFO principle in the same lane are directly
ignored during the state transition. In other words, the infeasi-
ble solutions are directly eliminated during the construction of
solution space.
By Property 1, the state holds Markovian property which is the
feasible conditions of DP model. By Property 2, it can extremely
decrease the number of transitions of DP model. By Property 3,
it can extremely decrease the number of states of DP model.
By Property 4, it significantly reduces the size of solution space
on the premise of ensuring optimality, and the state space just
presents all feasible passing orders.
E. Criterion Function
For the states with multiple predecessor states, criterion func-
tion is utilized to instruct decision making to find the optimal
predecessor state. In this part, we will present the formulation
of the criterion function in detail.
1) Vehicle Identity Information Implied in State Variable:
Note that the state variable implies the identity information of
the vehicle that obtains an access time at the current stage. As
shown in Fig. 2(b), s
3
(2, 1, 1) implies that the second vehicle
(m
3
= 2) on link 1 (r
3
= 1) (i.e., the vehicle B) is assigned to
pass the Merging Zone at stage 3.
Then, suppose that vehicle j and vehicle k are the ve-
hicles that obtain an access time at stage (i − 1) (state
s
i−1
(m
i−1
,n
i−1
,r
i−1
)) and stage i (state s
i
(m
i
,n
i
,r
i
)), re-
spectively. To minimize the maximal access time of vehicles,
according to the safety constraints (2), (4), (6), (8), (9) and the
state transition Equation (11), the recurrence relations of the
access time of vehicle j and vehicle k can be written as
t
assig n
k
=
⎧
⎪
⎪
⎪
⎪
⎪
⎪
⎪
⎪
⎪
⎨
⎪
⎪
⎪
⎪
⎪
⎪
⎪
⎪
⎪
⎩
min
max
t
min
k
,t
assig n
j
+Δ
t
1
,t
max
k
,
if r
i
= r
i−1
.
min
max
t
min
k
,t
assig n
j
+Δ
t
2
,t
max
k
,
if r
i
= r
i−1
.
(12)
Generally, t
max
k
is a very large number. Therefore, t
assig n
k
and
t
assig n
j
satisfy formula (13) during the process of state transition.
t
assig n
k
>t
assig n
j
. (13)
For example, t
assig n
A
<t
assig n
C
<t
assig n
B
<t
assig n
D
,as
shown in Fig. 2(d).
2) Criterion Function Formulation: We use M AAT
i
to de-
note the maximal assigned access time from state s
0
(0, 0,r
0
) to
s
i
(m
i
,n
i
,r
i
). According to the objective f unction of problem
(10), we define the criterion function of state s
i
(m
i
,n
i
,r
i
) as
f
i
(s
i
(m
i
,n
i
,r
i
)) = min
p
i−1
MAAT
i
. (14)
Fig. 3. Examples of making decisions during state transition.
where p
i−1
records the path from predecessor state in S
i−1
to
state s
i
(m
i
,n
i
,r
i
).
Actually, by formula (13), the value of M AAT
i
is equal to the
access time assigned to the vehicle at stage i. Then, by formula
(12), the recurrence relation between MAAT
i−1
and MAAT
i
is
MAAT
i
=
⎧
⎪
⎪
⎪
⎪
⎪
⎪
⎪
⎪
⎨
⎪
⎪
⎪
⎪
⎪
⎪
⎪
⎪
⎩
min
max
t
min
k
, M AAT
i−1
+Δ
t
1
,t
max
k
,
if r
i
= r
i−1
.
min
max
t
min
k
, M AAT
i−1
+Δ
t
2
,t
max
k
,
if r
i
= r
i−1
.
(15)
Now, we introduce Lemma 1 to derive the recurrence relation
of criterion function.
Lemma 1 (The principle of optimality [25]): if an optimal
sequence of states passes through a particular state s
i−1
(m
i−1
,
n
i−1
,r
i−1
), then the portion of the sequence from s
0
(0, 0,r
0
)
to s
i−1
(m
i−1
,n
i−1
,r
i−1
) must be the optimal sequence from
s
0
(0, 0,r
0
) to s
i−1
(m
i−1
,n
i−1
,r
i−1
).
Considering Lemma 1, we adopt the minimal value of
MAAT
i−1
(i.e., f
i−1
(s
i−1
)) to give the recurrence relation of
criterion function as
f
i
(s
i
(m
i
,n
i
,r
i
)) = min
p
i−1
MAAT
i
=min
p
i−1
⎧
⎪
⎪
⎪
⎪
⎪
⎪
⎪
⎪
⎨
⎪
⎪
⎪
⎪
⎪
⎪
⎪
⎪
⎩
min
max
t
min
k
,f
i−1
(s
i−1
)+Δ
t
1
,t
max
k
,
if r
i
= r
i−1
.
min
max
t
min
k
,f
i−1
(s
i−1
)+Δ
t
2
,t
max
k
,
if r
i
= r
i−1
.
(16)
where s
i−1
denotes the predecessor states of s
i
(m
i
,n
i
,r
i
) in
S
i−1
. Meanwhile, s
i−1
and s
i
(m
i
,n
i
,r
i
) satisfy the state tran-
sition Equation (11).
By formula (16), we can find that f
i
(s
i
(m
i
,n
i
,r
i
)) is deter-
mined by f
i−1
(s
i−1
) and r
i
. Thus, we can say that the recurrence
relation of criterion function follows Lemma 1. Obviously, there
are at most two predecessor states of s
i
(m
i
,n
i
,r
i
) in stage
(i − 1), i.e., there are at most two possible values of M AAT
i
of state s
i
(m
i
,n
i
,r
i
). Therefore, to solve problem (16), it is
computationally efficient by comparing all values of M AAT
i
,
as shown in Fig. 2(c).
Authorized licensed use limited to: University of Michigan Library. Downloaded on July 01,2020 at 01:11:53 UTC from IEEE Xplore. Restrictions apply.

PEI et al.: COOPERATIVE DRIVING STRATEGY FOR MERGING AT ON-RAMPS BASED ON DYNAMIC PROGRAMMING 11651
Algorithm 1: A DP Based Cooperative Driving Strategy.
Input: Locations and velocities of all vehicles
Output: The globally optimal passing order and the access
time of all vehicles
1: State space construction: Build the complete state
space from the initial state based on the state transition
function, as shown in Fig. 2(b).
2: Access time assignment: Calculate the minimal
MAAT
i
for all states during state transition:
If there is more than one predecessor state of the
current state, the criterion function is applied to decide
the optimal predecessor state according to the
principle of optimality, as shown in Fig. 2(c).
3: Backtracking search: Backtrack to export the
optimal passing order and assign the access time to all
vehicles, as shown in Fig. 2(d).
We use p
∗
i−1
to record the optimal path from the predecessor
states in S
i−1
to state s
i
(m
i
,n
i
,r
i
). Let us take state s
3
(2, 1, 1)
in Fig. 3 as an example to explain the process of making
decisions. There are two paths from the predecessor states in S
2
to state s
3
(2, 1, 1). The one is s
2
(1, 1, 2) → s
3
(2, 1, 1), the other
is s
2
(1, 1, 1) → s
3
(2, 1, 1). Each path leads to a corresponding
value of MAAT
3
. Thus, we can obtain p
∗
2
by comparing the
values of MAAT
3
.
F. Backtracking Approach
The minimal criterion function value of the terminal states
in S
m+n
is the optimal value of problem (10) based on the
description above. Then, we can get the optimal path from
state s
m+n
(m, n, r
i
) to state s
0
(0, 0,r
0
) based on the se-
quence (p
∗
m+n−1
,p
∗
m+n−2
,...,p
∗
0
) via backtracking approach,
as shown in Fig. 2(d). Finally, the optimal passing order and the
access time of vehicles are exported naturally.
As an example shown in Fig. 2(d), suppose that the criterion
function value of s
4
(2, 2, 2) is the minimal one in stage 4.
Then, the optimal path from s
4
(2, 2, 2) to s
0
(0, 0,r
0
) based on
(p
∗
3
,p
∗
2
,p
∗
1
,p
∗
0
) will be acquired via backtracking. Finally, the
corresponding optimal passing order (A-C-B-D) and the access
time of vehicles will be exported. The DP based cooperative
driving strategy is summarized as Algorithm 1.
IV. A
NALYSIS OF COMPUTATIONAL TIME COMPLEXITY
The principle of optimality is adopted in decision-making
process, which ensures that the passing order obtained by the
proposed strategy is the globally optimal one. In this section,
theoretical analysis of the computational time complexity will
be presented. Recall that the number of vehicles on link 1 and
link 2 are denoted by m and n, respectively.
A. Analysis of the Size of the DP Model
Two theorems of the size of the DP model are proposed.
Theorem 1: The number of the states of the DP model is
(2mn+ m + n + 1).
Theorem 2: The number of the transitions of the DP model
is (4mn).
Proof: See Appendix A.
By Theorem 1 and Theorem 2, the number of states and the
number of transitions of the DP model are quadratic polynomial
with the number of the vehicles. Thus, the size of the DP model
grows slowly as the number of vehicles increasing.
B. Analysis of Computational Ti me Complexity
The theorem of the computational time complexity of the DP
based strategy is proposed.
Theorem 3: The computational time complexity of the DP
based cooperative driving strategy is O(mn).
Proof: See Appendix B.
By Theorem 3, DP based cooperative driving strategy can
obtain the globally optimal passing order with quadratic poly-
nomial time complexity of the number of vehicles, i.e., the
computational time complexity is O(N
2
), where N denotes the
number of vehicles.
V. S
IMULATIONS
In this section, we will further validate the performance of the
DP based strategy via exploring some comparison simulations.
The proposed strategy is compared with an existing optimal
strategy and a sub-optimal strategy as classified in Section I. As
for the existing optimal strategy, problem (10) is directly solved
by the CVX software with Mosek solver in the simulations.
Thus, the access time for all vehicles can be exported directly.
As for the sub-optimal strategy, we select the ad hoc negotiation
based strategy as the benchmark, which instructs the vehicles to
pass through the conflict zone roughly in FIFO order. Thus, the
recurrence relations of the access time for the ad hoc negotiation
based strategy presents as follows:
t
assig n
i
=
⎧
⎨
⎩
t
min
i
, if i = 1.
min
max
t
min
i
,t
assig n
i−1
+Δ
,t
max
i
, if i>1.
(17)
where if vehicle i and vehicle (i − 1) are driving on the same
lane, Δ=Δ
t
1
. Otherwise, Δ=Δ
t
2
.
There are three evaluation indicators, namely the total passing
time, the traffic throughput and the computation time. The total
passing time is the access time to the Merging Zone of the last
vehicle in the Control Zone, i.e., the objective function presented
in formula (1). The traffic throughput is the total number of
vehicles that have entered the Merging Zone in a specified period
of time. In addition, the computation time denotes the time used
to obtain the solution in one-time optimization process.
The first simulation aims to illustrate that the total passing
time obtained by the proposed strategy is exactly equal to that
of the existing optimal strategy (the total passing time obtained
by the existing optimal strategy is the globally optimal one), and
the computation time of the proposed strategy is much less than
the existing optimal strategy. The second simulation explores
the comparison experiments of different cooperative driving
Authorized licensed use limited to: University of Michigan Library. Downloaded on July 01,2020 at 01:11:53 UTC from IEEE Xplore. Restrictions apply.
11652 IEEE TRANSACTIONS ON VEHICULAR TECHNOLOGY, VOL. 68, NO. 12, DECEMBER 2019
TAB L E I I
P
ARAMETERS SETTING IN THE SIMULATIONS
Fig. 4. Total passing time with respect to the number of vehicles.
strategies respect to the arrival flow rate in the continuous traffic
process.
The parameters utilized in the simulations are set as in Table II,
and the initial velocity of the vehicle is the uniform distribution
of [v
min
,v
max
]. All simulations are carried out on MATLAB
platform in a personal computer with an i7 CPU and an 8 GB
RAM.
A. The Optimality of the DP Based Strategy
To evaluate the optimality and the computational efficiency
of the DP based strategy, we design a merging scenario with c
vehicles (c ∈ [5, 27]) that randomly distributed in the Control
Zone. Then, three different cooperative driving strategies are
applied to this merging problem to get the corresponding passing
orders. For each c, we repeat the simulation 20 times to take the
average total passing time and the average computation time.
As shown in Fig. 4 and Fig. 5, the simulation results indicate
that the total passing time of the DP based strategy is exactly
equal to that of the existing optimal strategy, and the total
passing time of the DP based strategy is significantly decreased
compared to the ad hoc negotiation based strategy when the
number of vehicles is larger than 15. Moreover, the computation
time of the DP based strategy is close to that of the ad hoc
negotiation based strategy, while the average computation time
of the existing optimal strategy grows almost exponentially with
the increasing number of vehicles.
Consequently, we can conclude that the DP based strategy can
find the optimal solution with short enough computation time for
merging problem.
Fig. 5. Computational time with respect to the number of vehicles.
B. To Evaluate the Performance of the DP Based Strategy in
Continuous Traffic Process
In this simulation, the cooperative driving strategies are
applied to continuous traffic scenarios. The passing order is
replanned when a new vehicle enters the Control Zone. We
assume that the vehicles arrive in a Poisson Process at each
link [4], [22], [29], and the arrival rate λ of vehicles varies from
0.1veh/(lane ·s) to 0.33veh/(lane · s). For each arrival rate,
we simulate a 10-minutes traffic process (supposed that two links
possess the same arrival rate).
As pointed out in [4], traffic efficiency is mainly decided by
the passing order of vehicles, and different motion planning
methods, which control the vehicle to reach the Merging Zone
at the assigned access time, have a similar influence on traf-
fic efficiency. Thus, for simplicity, we adopt a simple motion
planning method to simulate the process of vehicle movement,
referring to Appendix C for details [22]. In addition, there are
also several other motion planning methods can be applied in
the simulations, e.g., the method introduced in [27].
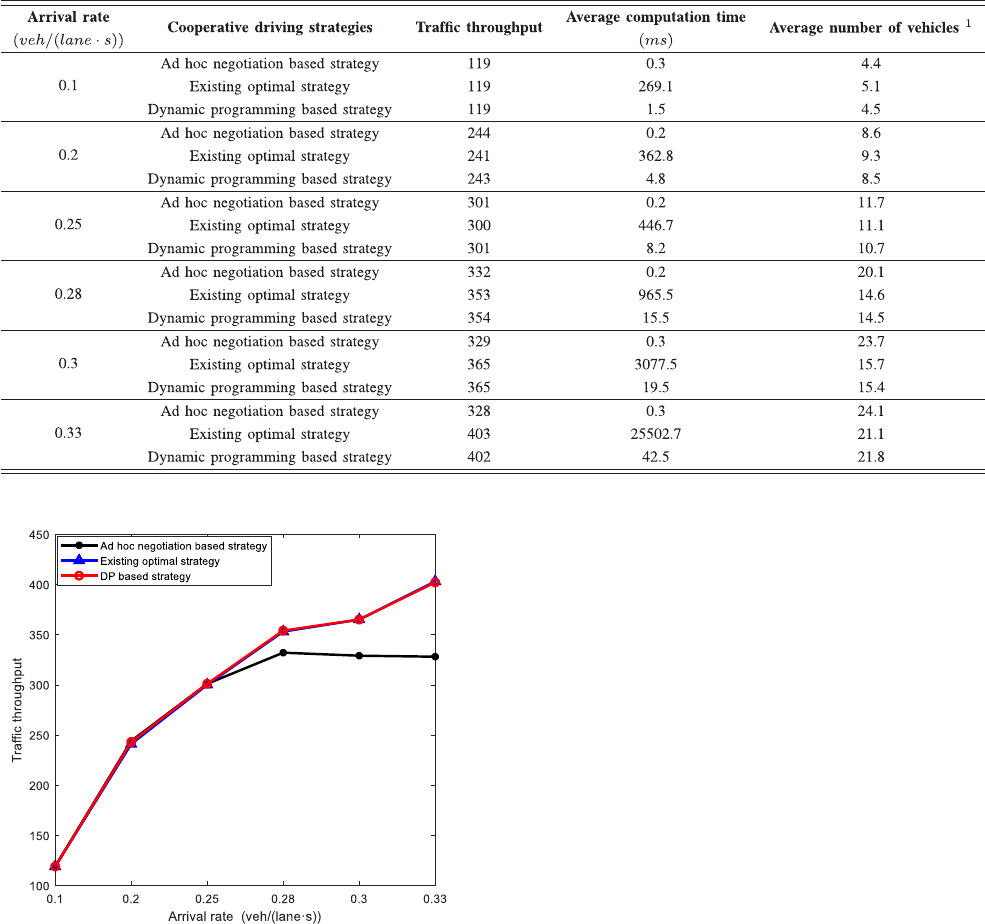
As shown in Table III and Fig. 6, the difference in the traffic
throughput of the DP based strategy and the ad hoc negotiation
based strategy increases with the increasing arrival rate. For
instance, when the arrival rate is 0.33veh/(lane ·s), the traffic
throughput of the DP based strategy is about 20% higher than the
ad hoc negotiation based strategy. Also, the traffic throughput of
the ad hoc negotiation based strategy reaches a saturation state
as the arrival rate increasing. Moreover, the computation time
of the DP based strategy is below 100 ms in all scenarios of
the simulations, as shown in Table III. In other words, the DP
based strategy exactly meets the real-time requirement when
applied to the real traffic scenario. Thus, it can be concluded
that the coordination performance of the DP based strategy is
extremely better than the ad hoc negotiation based strategy in
the continuous traffic process.
Considering the comparison results of the DP based strategy
and the existing optimal strategy, we can find that the traffic
throughput of the DP based strategy is nearly equal to the
existing optimal strategy. However, the computation time of the
existing optimal strategy grows sharply as the average arrival
Authorized licensed use limited to: University of Michigan Library. Downloaded on July 01,2020 at 01:11:53 UTC from IEEE Xplore. Restrictions apply.
PEI et al.: COOPERATIVE DRIVING STRATEGY FOR MERGING AT ON-RAMPS BASED ON DYNAMIC PROGRAMMING 11653
TABLE III
C
OMPARISON RESULTS OF DIFFERENT COOPERATIVE DRIVING STRATEGIES
1
Average number of vehicles: the average number of vehicles in the Control Zone.
Fig. 6. Traffic throughput of different strategies with respect to the arrival rate
in a 10-minutes traffic process.
rate increasing. Therefore, in terms of traffic efficiency, the
performance of the DP based strategy is almost the same as
the existing optimal strategy in the continuous traffic scenario.
In terms of computational complexity, the DP based strategy
can complete the optimization of passing order within a short
enough time.
Note here that there are a few differences in the traffic
throughput of the DP based strategy and the existing optimal
strategy. Actually, only the vehicles in the Control Zone will
be considered into the optimization of passing order at each
time period, and the optimal total passing time may correspond
to several different passing orders. Thus, for the same specific
merging scenario, both the DP based strategy and the existing
optimal strategy can obtain the optimal total passing time and an
optimal passing order, as illustrated in Section V-A. However,
for the continuous traffic scenario, the optimization of passing
order is a rolling optimization process. We can guarantee that the
passing order derived by the cooperative driving strategies is an
optimal one at current optimization process, but the influence
of the current passing order on the next time interval has not
been evaluated. Therefore, we can say that the passing order
derived by the DP based strategy or the existing optimal strategy
is a sub-optimal passing order for a continuous traffic scenario.
Also, it is hard to say which strategy getting a better passing
order in a rolling optimization process for the continuous traffic
process.
VI. C
ONCLUSION
In this paper, we propose a cooperative driving strategy for
merging at on-ramps based on DP. The key idea is to consider the
domain knowledge of the merging problem into the DP method
to reduce the complexity by well defining the state space, state
transition and criterion function. The passing order obtained by
the proposed strategy is proved the globally optimal solution. It is
also proved that the DP based strategy has quadratic polynomial
time complexity of the number of vehicles, i.e., O(N
2
).It
demonstrates that the proposed strategy is globally optimal yet
computationally efficient, which can overcome the limitations of
existing optimal strategies and sub-optimal strategies. Further-
more, the simulation results further validate that the DP based
strategy can find the globally passing order efficiently.
Moreover, some interesting and critical research topics will be
further studied in the near future. First, to relax the assumption
of pure connected and automated vehicles (CAVs), the pro-
posed strategy will be extended to a mixed traffic scenario by
Authorized licensed use limited to: University of Michigan Library. Downloaded on July 01,2020 at 01:11:53 UTC from IEEE Xplore. Restrictions apply.
11654 IEEE TRANSACTIONS ON VEHICULAR TECHNOLOGY, VOL. 68, NO. 12, DECEMBER 2019
predicting the movements of human-driven vehicles [30], [ 31].
Second, to relax the assumption of prohibiting lane changing,
the scenario with lane-change cases will be considered into the
cooperative driving problem. Third, the real-world scenario is
an infinite-horizon problem. How to improve the performance
of the proposed strategy for the infinite-horizon scenario also
deserves to be further studied.
A
PPENDIX A
P
ROOF OF THEOREM 1–2
Without losing generality, we suppose that m>n, where
m and n denote the number of vehicles on link 1 and link 2,
respectively. Recall that the stage number is denoted by i, i ∈
{i|0 ≤ i ≤ m + n, i ∈ Z}, and a state in stage i is denoted by
s
i
(m
i
,n
i
,r
i
), s
i
(m
i
,n
i
,r
i
) ∈ S
i
. Also, we have i = m
i
+ n
i
,
m
i
≤ m and n
i
≤ n by the definition of the state space of the
DP model.
Proof. (Theorem 1): The number of states varies in diff erent
stages, so we will analyze the number of states by categories,
which are classified by stage number.
1) Category 1: i = 0
There is only 1 state (the initial state s
0
(0, 0,r
0
))in
stage 0, i.e.,
N
1
= 1. (18)
2) Category 2: 0 <i≤ n
In this category, the s tate s
i
(m
i
,n
i
,r
i
) satisfies the fol-
lowing formulas:
0 ≤ m
i
≤ min{i, m} = i. (19a)
0 ≤ n
i
≤ min{i, n} = i. (19b)
m
i
+ n
i
= i. (19c)
i) Case 1: m
i
= 0,n
i
= i, r
i
= 2
There is only 1 state (i.e., state s
i
(0,i,2)) satisfying
Case 1 in stage i.
ii) Case 2: m
i
= i, n
i
= 0,r
i
= 1
There is only 1 state (i.e., state s
i
(i, 0, 1)) satisfying
Case 2 in stage i.
iii) Case 3: 0 <m
i
<i,0 <n
i
<iand r
i
= 1or2
According to 19, we can obtain that there are 2 × (i − 1)
states satisfying Case 3 in stage i.
Therefore, according to Case 1, Case 2 and Case 3, the
number of states in stage i is 2 × (i − 1)+2. Then, the
number of states satisfying Category 2 in the DP model is
N
2
=
n
i=1
[2 × (i − 1)+2]. (20)
3) Category 3: n<i≤ m
In this category, the s tate s
i
(m
i
,n
i
,r
i
) satisfies the fol-
lowing formulas:
0 ≤ m
i
≤ min{i, m} = i. (21a)
0 ≤ n
i
≤ min{i, n} = n. (21b)
m
i
+ n
i
= i. (21c)
Then, it can be obtained that m
i
and n
i
satisfy the follow-
ing formulas:
i − n ≤ m
i
≤ i. (22a)
0 ≤ n
i
≤ n. (22b)
i) Case 1: m
i
= i, n
i
= 0,r
i
= 1
There is only 1 state (i.e., state s
i
(i, 0, 1)) satisfying
Case1instagei.
ii) Case 2: i − n ≤ m
i
<i,0 <n
i
≤ n and r
i
= 1or2
According to (21)–(22), we can obtain that there are 2n
states satisfying Case 2 in stage i.
Therefore, according to Case 1 and Case 2, the number
of states in stage i is 2n + 1. Then, the number of states
satisfying Category 3 in the DP model is
N
3
=
m
i=n+1
(2n + 1). (23)
4) Category 4: i>m
In this category, the state s
i
(m
i
,n
i
,r
i
) satisfies the fol-
lowing formulas:
0 ≤ m
i
≤ min{i, m} = m. (24a)
0 ≤ n
i
≤ min{i, n} = n. (24b)
m
i
+ n
i
= i. (24c)
Then, it can be obtained that m
i
and n
i
satisfy the following
formulas:
i − n ≤ m
i
≤ m. (25a)
0 ≤ n
i
≤ min{i, n} = n. (25b)
i − m ≤ n
i
≤ n. (25c)
According to (24)–(25), we can obtain that there are 2 × (m +
n − i + 1) in stage i.
Therefore, the number of states satisfying Category 4 in the
DP model is
N
4
=
m+n
i=m+1
2 × (m + n − i + 1). (26)
Therefore, based on (18), (20), (23) and (26), we can conclude
that the total number of states in the DP model is
N
state
= N
1
+ N
2
+ N
3
+ N
4
= 2mn + m + n + 1. (27)
Obviously, (27) is a complete symmetry formula. Therefore,
formula (27) still holds when m ≤ n.
Proof. (Theorem 2): According to the state transition
Equation (11), each state in stage i has two transitions to
expand to stage (i + 1) except the state s
i
(m, i − m, r
i
) or
s
i
(i − n, n, r
i
), which has only one transitions. We can also
adopt the classified method to obtain the number of transitions
of the DP model.
1) Category 1: i = 0
According to formula (18), the state s
i
(m, i − m, r
i
) or
s
i
(i − n, n, r
i
) does not exist in stage 0. Thus, the number
of transitions in stage 0 is
N
1
= 2N
1
= 2. (28)
Authorized licensed use limited to: University of Michigan Library. Downloaded on July 01,2020 at 01:11:53 UTC from IEEE Xplore. Restrictions apply.
PEI et al.: COOPERATIVE DRIVING STRATEGY FOR MERGING AT ON-RAMPS BASED ON DYNAMIC PROGRAMMING 11655
2) Category 2: 0 <i<n
According to (20), the state s
i
(m, i − m, r
i
) or s
i
(i −
n, n, r
i
) does not exist in stage i.
Thus, the number of transitions satisfying Category 2 in
the DP model is
N
2
= 2N
2
=
n−1
i=1
[4 × (i − 1)+4]. (29)
3) Category 3: i = n
According to (20), there are 2 × (i − 1)+2 states in s tage
n including the state s
n
(0,n,2).
Thus, the number of transitions satisfying Category 3 in
the DP model is
N
3
= 2 × [2 × (n − 1)+1]+1 = 4 × (n − 1)+3.
(30)
4) Category 4: n<i<m
According to (23), there are 2n + 1 states in stage i
including the states s
i
(i − n, n, 1) and s
i
(i − n, n, 2).
Thus, the number of transitions satisfying Category 4 in
the DP model is
N
4
=
m−1
i=n+1
[2 × (2n − 1)+2 × 1]=
m−1
i=n+1
4n. (31)
5) Category 5: i = m
According to (23), there are 2n + 1 states in stage m
including the states s
m
(m, 0, 1), s
m
(m − n, n, 1) and
s
m
(m − n, n, 2).
Thus, the number of transitions satisfying Category 5 in
the DP model is
N
5
= 2 × (2n + 1 − 3)+3 = 4n − 1. (32)
6) Category 6: m<i<m+ n
According to (26), there are 2 × (m + n − i + 1) states
in stage i including the states s
i
(m, i − m, 1), s
i
(m, i −
m, 2), s
i
(i − n, n, 1) and s
i
(i − n, n, 2).
Thus, the number of transitions satisfying Category 6 in
the DP model is
N
6
=
m+n−1
i=m+1
{2 × [2 × (m + n − i + 1) − 4]+4}.
(33)
7) Category 7: i = m + n
Obviously, there is no transition expanding to next stage
in stage m + n, i.e.,
N
7
= 0. (34)
Therefore, based on (28)–(34), we can conclude that the
total number of transitions of the DP model is
N
transition
= N
1
+ N
2
+ N
3
+ N
4
+ N
5
+ N
6
+N
7
= 4mn. (35)
Obviously, (35) is a complete symmetry formula. Therefore,
formula (35) still holds when m ≤ n.
A
PPENDIX B
P
ROOF OF THEOREM 3
Proof. (Theorem 3): The computations of the DP based co-
operative driving strategy proposed in this paper mainly include
two terms: the one is the process of state transition, the other
is the evaluation of the criterion function value for each state.
The computational time of each computation is a constant time,
which does not change with the size of the input of the algorithm
(i.e., the total number of the vehicles). Therefore, the total
number of computations is about (N
transition
+ N
state
), and the
computational time complexity of the DP based cooperative
driving strategy is O(mn).
A
PPENDIX C
AS
IMPLE MOTION PLANNING METHOD
A simple motion planning method is utilized in the sim-
ulations. Several modes of vehicle movement are shown as
following [22]:
Mode 1: Keeping a constant velocity.
a
i
= 0. (36a)
x
0,i
= v
0,i
· t
m
i
. (36b)
Mode 2: Accelerating to a cruising velocity, then driving at
the cruising speed.
a
i
= a
max
. (37a)
t
a
= t
m
i
− ΔT. (37b)
v
cur
= v
0,i
+ a
i
· t
a
. (37c)
where t
a
denotes the accelerating time.
Mode 3: Decelerating to a cruising velocity, then driving at
the cruising speed.
a
i
= a
min
. (38a)
t
a
= t
m
i
+ΔT. (38b)
v
cur
= v
0,i
+ a
i
· t
d
. (38c)
where t
d
denotes the decelerating time.
where ΔT =
√
(a
i
·t
m
i
)
2
+2a
i
(v
0
·t
m
i
−x
0,i
)
a
i
.
Authorized licensed use limited to: University of Michigan Library. Downloaded on July 01,2020 at 01:11:53 UTC from IEEE Xplore. Restrictions apply.

11656 IEEE TRANSACTIONS ON VEHICULAR TECHNOLOGY, VOL. 68, NO. 12, DECEMBER 2019
REFERENCES
[1] J. A. Misener and S. E. Shladover, “Path investigations in vehicle-roadside
cooperation and safety: A foundation for safety and vehicle-infrastructure
integration research,” in Proc. IEEE Intell. Transp. Syst. Conf., 2006,
pp. 9–16.
[2] R. Ke, Z. Zeng, Z. Pu, and Y. Wang, “New framework for automatic
identification and quantification of freeway bottlenecks based on wavelet
analysis,” J. Transp. Eng., Part A: Syst., vol. 144, no. 9, 2018, Art.
no. 04 018 044.
[3] S. Tsugawa, “Inter-vehicle communications and their applications to intel-
ligent vehicles: An overview,” in Proc. Intell. Vehicle Symp., vol. 2, 2002,
pp. 564–569.
[4] M. Yue, L. Li, F. Wang, K. Li, and Z. Li, “Analysis of cooperative driving
strategies for non-signalized intersections,” IEEE Trans. Veh. Technol.,
vol. 67, no. 4, pp. 2900–2911, Apr. 2018.
[5] S. Feng, H. Sun, Y. Zhang, J. Zheng, H. X. Liu, and L. Li, “Tube-based
discrete controller design for vehicle platoons subject to disturbances
and saturation constraints,” IEEE Trans. Control Syst. Technol.,tobe
published, doi: 10.1109/TCST.2019.2896539.
[6] L. Chen and C. Englund, “Cooperative intersection management: A
survey,” IEEE Trans. Intell. Transp. Syst., vol. 17, no. 2, pp. 570–586,
Feb. 2016.
[7] R. F. Atallah, C. M. Assi, and J. Y. Yu, “A reinforcement learning technique
for optimizing downlink scheduling in an energy-limited vehicular net-
work,” IEEE Trans. Veh. Technol., vol. 66, no. 6, pp. 4592–4601, Jun. 2017.
[8] L. Li and F. Wang, “Cooperative driving at blind crossings using in-
tervehicle communication,” IEEE Trans. Veh. Technol., vol. 55, no. 6,
pp. 1712–1724, Nov. 2006.
[9] L. Li, W. Ding, and D. Yao, “A survey of traffic control with vehicular
communications,” IEEE Trans. Intell. Transp. Syst., vol. 15, no. 1, pp. 425–
432, Feb. 2014.
[10] Y. Bi, L. X. Cai, X. Shen, and Z. Hai, “Efficient and reliable broadcast
in intervehicle communication networks: A cross-layer approach,” IEEE
Trans. Veh. Technol., vol. 59, no. 5, pp. 2404–2417, Jun. 2010.
[11] Q. Guo, L. Li, and X. J. Ban, “Urban traffic signal control with connected
and automated vehicles: A survey,” Transp. Res. Part C Emerg. Technolo-
gies, vol. 101, pp. 313–334, 2019.
[12] S. Feng, Y. Zhang, S. Li, Z. Cao, H. Liu, and L. Li, “String stability for
vehicular platoon control: Definitions and analysis methods,” Annu. Rev.
Control, vol. 47, pp. 81–97, 2019.
[13] C. Yu, Y. Feng, H. X. Liu, W. Ma, and X. Yang, “Integrated optimization
of traffic signals and vehicle trajectories at isolated urban intersections,”
Transp. Res. Part B, vol. 112, pp. 89–112, 2018.
[14] Y. Feng, C. Yu, and H. X. Liu, “Spatiotemporal intersection control in
a connected and automated vehicle environment,” Transp. Res. Part C
Emerg. Technologies, vol. 89, pp. 364–383, 2018.
[15] P. Li and X. Zhou, “Recasting and optimizing intersection automation
as a connected-and-automated-vehicle (CAV) scheduling problem: A se-
quential branch-and-bound search approach in phase-time-traffic hyper-
network,” Transp. Res. Part B Methodological, vol. 105, pp. 479–506,
2017.
[16] E. R. Müller, R. C. Carlson, and W. K. Junior, “Intersection control
for automated vehicles with MILP,” IFAC Papersonline, vol. 49, no. 3,
pp. 37–42, 2016.
[17] H. Ahn and D. D. Vecchio, “Safety verification and control for collision
avoidance at road intersections,” IEEE Trans. Autom. Control, vol. 63,
no. 3, pp. 630–642, Mar. 2018.
[18] K. M. Dresner and P. Stone, “Multiagent traffic management: A
reservation-based intersection control mechanism,” in Proc. 3rd Int. Joint
Conf. Auton. Agents Multiagent Syst., 2004, pp. 530–537.
[19] K. M. Dresner and P. Stone, “A multiagent approach to autonomous
intersection management,” J. Artif. Intell. Res., vol. 31, no. 3, pp. 591–656,
2008.
[20] S. Huang, A. W. Sadek, and Y. Zhao, “Assessing the mobility and en-
vironmental benefits of reservation-based intelligent intersections using
an integrated simulator,” IEEE Trans. Intell. Transp. Syst., vol. 13, no. 3,
pp. 1201–1214, Sep. 2012.
[21] M. Choi, A. Rubenecia, and H. H. Choi, “Reservation-based cooperative
traffic management at an intersection of multi-lane roads,” in Proc. Int.
Conf. Inf. Netw., 2018, pp. 456–460.
[22] H. Xu, S. Feng, Y. Zhang, and L. Li, “A grouping based cooperative driving
strategy for CAVs merging problems,” IEEE Trans. Veh. Technol., vol. 68,
no. 6, pp. 6125–6136, Jun. 2019.
[23] H. Xu, Y. Zhang, L. Li, and W. Li, “Cooperative driving at unsignalized
intersection using tree search,” IEEE Trans. Intell. Transp. Syst., submitted
for publication.
[24] Z. Li et al., “Temporal-spatial dimension extension-based intersection
control formulation for connected and autonomous vehicle systems,”
Transp. Res. Part C: Emerg. Technol., vol. 104, pp. 234–248, 2019.
[25] J. F. Baldwin, “Principles of dynamic programmingpt 1: Basic analytic
and computational methods,” Electron. Power, vol. 25, no. 4, pp. 230–231,
1979.
[26] E. V. Denardo, Dynamic Programming: Models and Applications,New
York, NY, USA: Dover, 2003.
[27] A. Malikopoulos, C. Cassandras, and Y. Zhang, “A decentralized energy-
optimal control framework for connected automated vehicles at signal-free
intersections,” Automatica, vol. 93, pp. 244–256, 2018.
[28] E. M. L. Beale, “Branch and bound methods for mathematical program-
ming systems,” Discrete Optim., vol. 5, no. 5, pp. 201–219, 1979.
[29] C. Liu, C. W. Lin, S. Shiraishi, and M. Tomizuka, “Distributed conflict res-
olution for connected autonomous vehicles,” IEEE Trans. Intell. Vehicles,
vol. 3, no. 1, pp. 18–29, Mar. 2018.
[30] S. Gong and L. Du, “Cooperative platoon control for a mixed traffic flow
including human drive vehicles and connected and autonomous vehicles,”
Transp. Res. Part B: Methodological, vol. 116, pp. 25–61, 2018.
[31] F. Li and Y. Wang, “Cooperative adaptive cruise control for string stable
mixed traffic: Benchmark and human-centered design,” IEEE Trans. Intell.
Transp. Syst., vol. 18, no. 12, pp. 3473–3485, Dec. 2017.
Huaxin Pei received the B.S. degree from the Univer-
sity of Electronic Science and Technology of China,
Chengdu, China, in 2017. He is currently working
toward the Ph.D. degree with the Department of Au-
tomation, Tsinghua University, Beijing, China. His
current research interests include cooperative driving
and intelligent vehicles.
Shuo Feng received the B.S. degree from the Depart-
ment of Automation, Tsinghua University, Beijing,
China, in 2014. He is currently working toward the
Ph.D. degree with the Department of Automation,
Tsinghua University, China. He is also a Visiting
Ph.D. Student with the Department of Civil and
Environmental Engineering, University of Michigan,
Ann Arbor, MI, USA. His current research interests
include optimal control, connected and automated
vehicle evaluation, and transportation data analysis.
Yi Zhang (S
01−M
04) received the B.S. and M.S.
degrees, from Tsinghua University, Beijing, in China,
in 1986 and 1988, respectively, and the Ph.D. degree
from the University of Strathclyde, Glasgow, in the
UK, in 1995. He is a Professor in Control Science and
Engineering with Tsinghua University. His current
research interests focuses on intelligent transportation
systems. His active research areas include intelligent
vehicle-infrastructure cooperative systems, analysis
of urban transportation systems, urban road network
management, traffic data fusion and dissemination,
and urban traffic control and management. His research fields also cover the
advanced control theory and applications, advanced detection and measurement,
systems engineering, etc.
Danya Yao (M
04) received the B.S., M.S., and Ph.D.
degrees from Tsinghua University, Beijing, China, in
1988, 1990, and 1994, respectively. He is a Full Pro-
fessor with the Department of Automation, Tsinghua
University. His research interests include intelligent
detection technology, system engineering, mixed traf-
fic flow theory, and intelligent transportation systems.
Authorized licensed use limited to: University of Michigan Library. Downloaded on July 01,2020 at 01:11:53 UTC from IEEE Xplore. Restrictions apply.
