Technical Disclosure Commons Technical Disclosure Commons
Defensive Publications Series
19 Jan 2021
Automatic Timestamp Recalculation During Audio Transcript Automatic Timestamp Recalculation During Audio Transcript
Editing Editing
Hao Wu
Follow this and additional works at: https://www.tdcommons.org/dpubs_series
Recommended Citation Recommended Citation
Wu, Hao, "Automatic Timestamp Recalculation During Audio Transcript Editing", Technical Disclosure
Commons, (January 19, 2021)
https://www.tdcommons.org/dpubs_series/3984
This work is licensed under a Creative Commons Attribution 4.0 License.
This Article is brought to you for free and open access by Technical Disclosure Commons. It has been accepted for
inclusion in Defensive Publications Series by an authorized administrator of Technical Disclosure Commons.

Automatic Timestamp Recalculation During Audio Transcript Editing
ABSTRACT
Automatic speech-to-text software sometimes produces transcripts that include errors
which users correct manually, e.g., by inserting or deleting words. It is important that the edited
transcript bears word-level timestamps that are faithful to the raw (unedited) transcript. This
disclosure describes techniques that can be applied in real time to automatically and accurately
recalculate timestamps of words in a transcript even as a user makes edits to the transcript. With
immediate/ real-time timestamp recalculation as described herein, users can play a recording and
edit the corresponding transcript while simultaneously enjoying transcript-editing utilities like
karaoke-style highlighting; word, sentence, or paragraph insertion, replacement, or deletion;
paragraph break insertion; paragraph merging; playing or sharing selected audio segments
(sentences, paragraphs, etc.) of the transcript; etc.
KEYWORDS
● Transcript editing
● Transcript timestamps
● Audio timestamp
● Speech-to-text
● Karaoke highlighting
● Longest common subsequence
(LCS)
BACKGROUND
Automatic speech-to-text software, e.g., used for online or offline meetings or in other
contexts, sometimes produces transcripts that include errors. Users edit and correct transcripts for
various reasons, e.g., to have high-quality records; to reduce misunderstandings that may arise
from inaccuracy; to enable searches through transcripts; to restructure transcripts to make them
easy to read, to quote, or refer to; to enable accurate sharing of information; to generally parse
2
Wu: Automatic Timestamp Recalculation During Audio Transcript Editing
Published by Technical Disclosure Commons, 2021
information; etc. Transcript-editing software enables users to simultaneously replay the audio,
display the transcript by the side (highlighting karaoke-style the word that is currently being
played), and make corrections to the transcript.
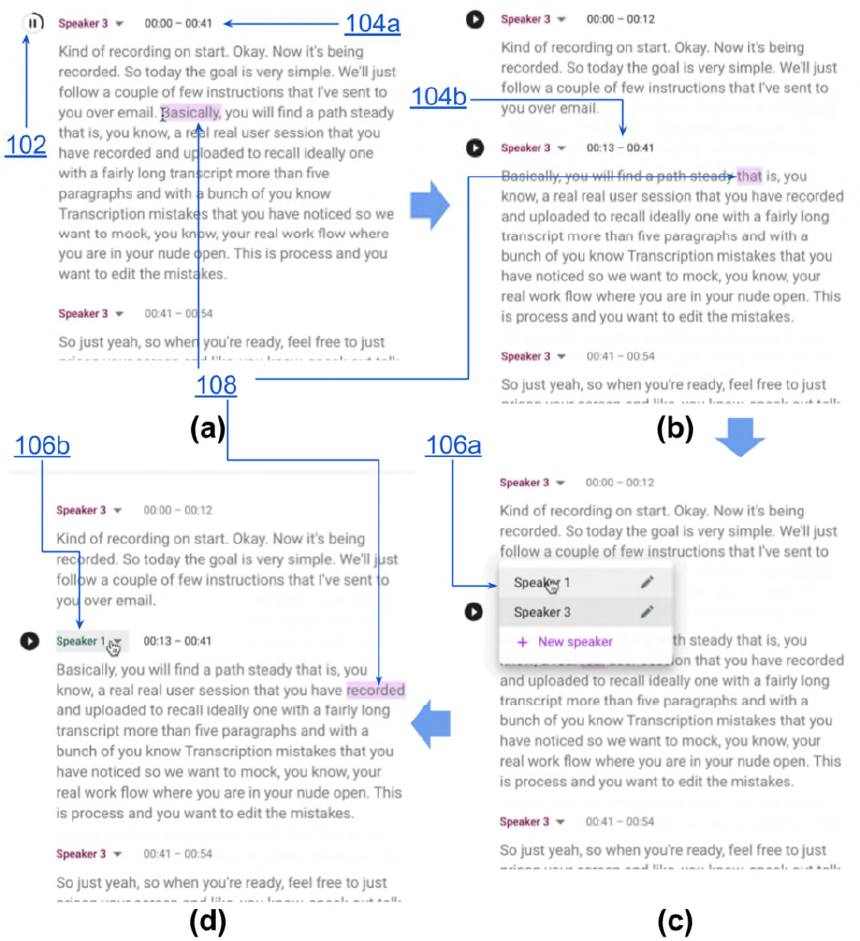
Fig. 1: Transcript-editing software in operation
3
Defensive Publications Series, Art. 3984 [2021]
https://www.tdcommons.org/dpubs_series/3984
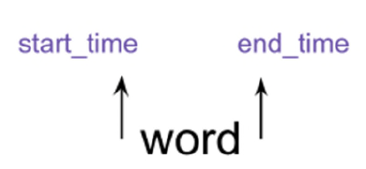
Fig. 1 illustrates an example of transcript-editing software in operation. In this example,
audio that includes a conversation is provided as input to the software. Figures 1(a)-(d) represent
consecutive snapshots of the user interface (UI) in time. Buttons (102) are provided to play or
pause the audio waveform. Fig. 1(a) represents an initial (unedited) transcript, which includes
paragraph timestamps (104a).
In Fig. 1(b), as the audio plays, the user introduces an edit, e.g., the insertion of a
paragraph-break. The newly-formed paragraph is assigned its own paragraph-level timestamp
(104b) based on word-level timestamps. The word-level timestamps remain invisible to the user.
In Fig. 1(c), as the audio continues playing, the user makes another edit (106a), e.g., the
relabeling of the speaker of the second paragraph. Fig. 1(d) shows the paragraph with the re-
labeled speaker (106b). Even as the audio continues playing and the user simultaneously makes
edits, the currently played word is highlighted karaoke-style (108, pink).
Fig. 2: A word in a raw transcript is annotated with start and end timestamps
As shown in Fig. 2, speech-to-text software generally annotates each word in a transcript
with timestamps that indicate the start and the end of word-utterances. Although word-level
timestamps do not appear in the user interface, these are critical to many transcript-editing
functions, e.g., karaoke-style highlighting; word, sentence, or paragraph insertion, replacement,
or deletion; paragraph (or other) break insertion; paragraph (or other) merging; playing or
sharing selected audio segments (sentences, paragraphs, etc.) of the transcript; etc.
4
Wu: Automatic Timestamp Recalculation During Audio Transcript Editing
Published by Technical Disclosure Commons, 2021

A transcript that is edited by the user may include insertions or deletions. For transcript-
editing features to continue to work, it is important that the edited transcript bears word-level
timestamps that are faithful to the raw (unedited) transcript. Specifically, the timestamps of the
new (inserted) words must lie on a continuum between original words at the ends of an inserted
string, the deletion of words must not introduce timestamp inaccuracy, and timestamps must
monotonically increase with the text in the edited transcript.
Although there are transcript-editors that enable users to modify timestamps, such editors
do not automatically recalculate word timestamps, or even display the timestamps on the UI. As
a result, the user has to resort to manually associating sentences or chunks of text to parts of the
recording by looking at and replaying chunks of the audio. It is important to reduce or eliminate
the burden of assigning timestamps to edited words that falls on the user who edits the transcript.
DESCRIPTION
This disclosure describes techniques that can be applied in real time to automatically and
accurately recalculate timestamps of words in a transcript even as a user makes edits to the
transcript. Users can simply edit transcripts as if editing a plain text document (similar to editing
in a text editor) without manually reassigning word timestamps. Since word timestamps are
recalculated as the user makes edits, users can play an audio recording and edit the
corresponding transcript while simultaneously enjoying transcript-editing utilities like karaoke-
style highlighting; word, sentence, or paragraph insertion, replacement, or deletion; paragraph
(or other) break insertion; paragraph (or other) merging; playing or sharing selected audio
segments (sentences, paragraphs, etc.) of the transcript; etc.
5
Defensive Publications Series, Art. 3984 [2021]
https://www.tdcommons.org/dpubs_series/3984
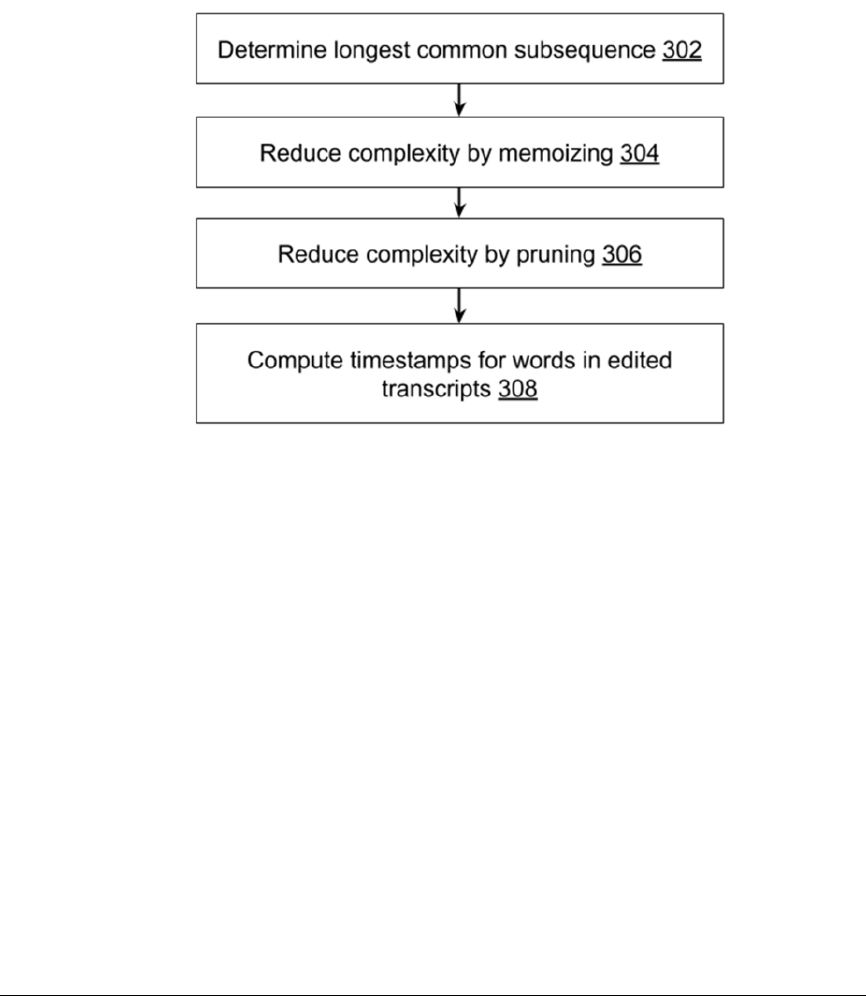
Fig. 3: Real-time timestamp-recalculation in audio transcripts
As illustrated in Fig. 3, raw and edited transcripts are compared to determine the longest
common subsequences (LCS) between them (302). LCS determination is cast as a dynamic
programming problem whose complexity is reduced from exponential to polynomial using
windowing, memoization (304), and pruning (306). Once LCS is determined between raw and
edited transcripts, timestamps are calculated for the words in the edited transcripts (308). For
example, the timestamps for words inserted between two original (or anchor) words are
calculated generally as a linear interpolation between the timestamps of the anchor words. The
techniques are described in greater detail below.
Determine the LCS between raw and edited transcripts (dynamic programming formulation)
The longest common subsequence length between two sequences of words s
1
and s
2
is
denoted by C(s
1
, s
2
). For example,
C(‘and yet this mottled dawn’, ‘mottled dawn is unlike our dream’) = 2,
6
Wu: Automatic Timestamp Recalculation During Audio Transcript Editing
Published by Technical Disclosure Commons, 2021
since the longest common subsequence between the strings ‘and yet this mottled dawn’ and
‘mottled dawn is unlike our dream’ is ‘mottled dawn’ which is of length 2. In computing
common subsequence length, the subsequence needs not be continuous . For example,
C(‘to be or not to’, ‘to or be not is to’) = 4
since the longest common subsequence between the input strings is ‘to be not to’ (of length 4),
obtained from the first argument as ‘to be or not to’ and from the second argument as ‘to or be
not is to.’
Given an unedited string s
1
of length n + 1 words and an edited string s
2
of length m + 1
words, the following recursion holds.
C( s
1
[0 … n], s
2
[0 … m] ) =
{
C( s
1
[0 … n−1], s
2
[0 … m−1] )
+ 1,
if s
1
[n] = s
2
[m]
max( C( s
1
[0 ... n−1], s
2
[0 ... m] ),
C( s
1
[0 ... n], s
2
[0 ... m−1]
) ),
if s
1
[n] ≠ s
2
[m]
The above recursion sets up the determination of the LCS between strings s
1
and s
2
as a dynamic
programming problem, which, in its raw form, however, is exponential in complexity.
Fig. 4: Windowed LCS
To reduce the complexity of LCS computation, the sequences s
1
and s
2
being compared
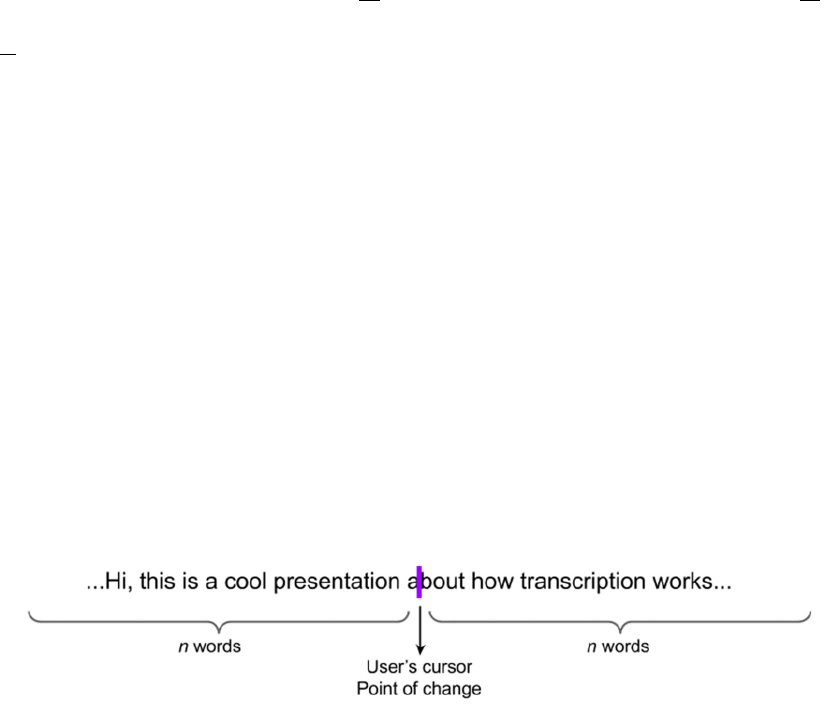
are windowed, as illustrated in Fig. 4. The windowed LCS recursion is centered on the user’s
current cursor location, and looks back and looks ahead a finite number (n) of words, where n
7
Defensive Publications Series, Art. 3984 [2021]
https://www.tdcommons.org/dpubs_series/3984
can be, for example, forty. Windowing reduces the number of states in the dynamic
programming model such that operations can be completed without exceeding memory
constraints.
Memoization
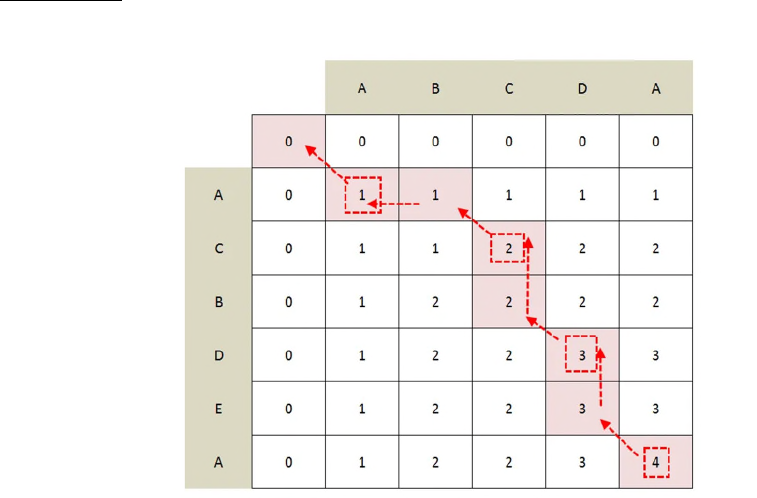
Fig. 5: Illustrating memoization (Source: [2])
As illustrated in Fig. 5, memoization can be carried out by caching state space in a two-
dimensional matrix. In this context, state refers to C(s
1
[0 ... i], s
2
[0 ... j]) for any i [0, n], j [0,
n]. The row-header of the matrix is the unedited transcript, e.g., ABCDA, and the column-header
is the edited transcript, e.g., ACBDEA (where A, B, …, E represent words). An entry represents
an LCS solution for some truncated s
1
and s
2
. The final LCS between s
1
and s
2
can be found by
backtracking along the pink pathway: the LCS sequence is represented by the dashed red boxes.
For example, the longest common subsequences at various time-points in the matrix are
as follows.
8
Wu: Automatic Timestamp Recalculation During Audio Transcript Editing
Published by Technical Disclosure Commons, 2021
C
(A, A)
= 1
C
(AB, A)
= 1
C
(ABC,
AC)
= 2
C
(ABC, ACB)
= 2
…
C
(ABCDA, ACBDEA)
= 4
Pruning
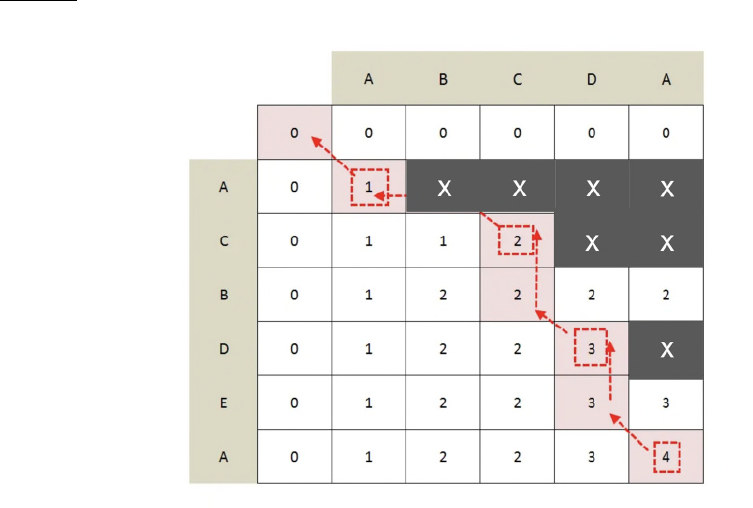
Fig. 6: Illustrating pruning
Pruning builds on the observation that at every step the recursion increases the length of
the longest common subsequence by at most one. Thus, the maximum value in row j can be at
most 1 greater than that of row j - 1. As a result, the upper-bound of the maximum value of the
next row in the state matrix can be predicted and calculation in that row can be stopped once the
upper-bound value is reached. In light of this, as illustrated in Fig. 6, many entries in the upper
diagonal of the state-space matrix need not be computed, thus further reducing complexity.
9
Defensive Publications Series, Art. 3984 [2021]
https://www.tdcommons.org/dpubs_series/3984
Computing timestamps of words in the edited transcript
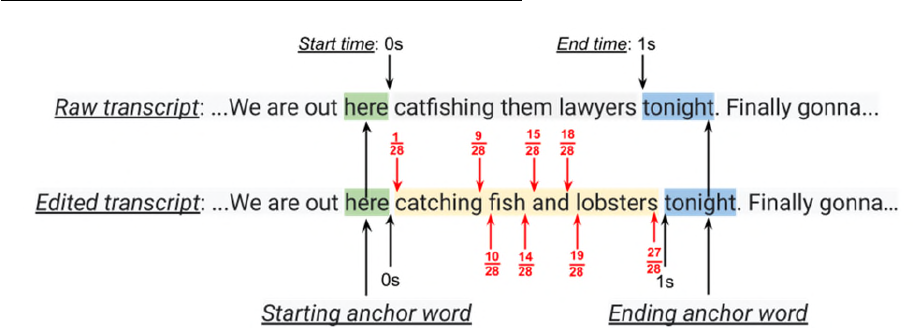
Fig. 7: Computing timestamps of words in the edited transcript
As illustrated in Fig. 7, the longest common subsequences between the raw and the edited
transcripts determine the common words at either end of an edited string. These common words
are known as the starting anchor word and the ending anchor word. In the example of Fig. 7, the
string “catfishing them lawyers” in the raw transcript has been edited by the user to “catching
fish and lobsters.” The starting anchor word, e.g., the common word just prior to the edits, is
“here,” and the ending anchor word, e.g., the common word just after the edits, is “tonight.” As
explained earlier, the raw transcript has word-level timestamps (see Fig. 2). These word-level
timestamps can be used to determine the starting and ending timestamp of the edited phrase. In
the example of Fig. 7, the start-time and the end-time of the edited phrase are respectively 0
seconds and 1 second.
Word-level timestamps can be found for the edited transcript in various ways. For
example, as shown in Fig. 7 (red font), the word-level transcripts can be a linear interpolation
between the start- and end-times of the edited phrase (accounting for the length of the phrase in
letters, 28 in this example, whitespace included). As a special case, if just one word is deleted
and replaced, then the replaced word has the same word-level timestamp as the original word. If
10
Wu: Automatic Timestamp Recalculation During Audio Transcript Editing
Published by Technical Disclosure Commons, 2021

no anchor words are found, linear interpolation is carried out within the current context (the time
boundary of the edited phrase is determined solely by neighboring words in the edited
transcript).
The described techniques can be implemented as part of standalone transcript editing
software, or transcript editing as implemented in other software, to provide instantaneous updates
in the user interface as a user edits transcripts of any recording, e.g., a recording of an
online/offline meeting.
CONCLUSION
This disclosure describes techniques that can be applied in real time to automatically and
accurately recalculate timestamps of words in a transcript even as a user makes edits to the
transcript. With immediate/ real-time timestamp recalculation as described herein, users can play
a recording and edit the corresponding transcript while simultaneously enjoying transcript-
editing utilities like karaoke-style highlighting; word, sentence, or paragraph insertion,
replacement, or deletion; paragraph break insertion; paragraph merging; playing or sharing
selected audio segments (sentences, paragraphs, etc.) of the transcript; etc.
REFERENCES
1. Speech-to-Text: Automatic Speech Recognition https://cloud.google.com/speech-to-text
2. Dynamic Programming - Longest Common Subsequence | TutorialHorizon
https://algorithms.tutorialhorizon.com/dynamic-programming-longest-common-subsequence/
3. Trint: Audio Transcription Software | Speech to Text to Magic https://trint.com/
4. Descript | Create podcasts, videos, and transcripts https://www.descript.com/
11
Defensive Publications Series, Art. 3984 [2021]
https://www.tdcommons.org/dpubs_series/3984
