
Received:23April2021 Revised:7April2022 Accepted:9May2022
DOI:10.1111/desc.13290
SHORT REPORT
Looking is not enough: Multimodal attention supports the
real-time learning of new words
Sara E Schroer Chen Yu
DepartmentofPsychology,TheUniversityof
TexasatAustin,Austin,Texas,USA
Correspondence
SaraESchroer,DepartmentofPsychology,The
UniversityofTexasatAustin,Austin,TX,USA.
Email:[email protected]
Funding information
NationalInstitutesofHealth,Grant/Award
Numbers:R01HD074601,R01HD093792,
T32HD007475;NationalScienceFoundation,
Grant/AwardNumber:GRFPDGE-1610403
Abstract
Most research on early language learning focuses on the objects that infants see
and the words they hear in their daily lives, although growing evidencesuggests that
motordevelopmentisalsocloselytiedtolanguagedevelopment.Tostudythereal-time
behaviorsrequiredforlearningnewwords duringfree-flowing toyplay,we measured
infants’ visual attention and manual actions on to-be-learned toys. Parents and 12-
to-26-month-old infants wore wireless head-mounted eye trackers, allowing them to
movefreely around a home-likelab environment. After the play session, infants were
testedontheirknowledgeofobject-labelmappings.Wefoundthathowoftenparents
namedobjectsduringplaydidnotpredictlearning,butinstead,itwasinfants’attention
duringandaroundalabelingutterancethatpredictedwhetheranobject-labelmapping
waslearned.Morespecifically,wefoundthatinfantvisualattentionalonedidnotpre-
dict word learning. Instead, coordinated, multimodal attention––when infants’ hands
and eyes were attending to the same object––predicted word learning. Our results
implicate a causal pathwaythrough whichinfants’ bodily actions play a critical role in
earlywordlearning.
KEYWORDS
attention,eyetracking,multimodalbehaviors,parent–infantinteraction,wordlearning
1 INTRODUCTION
Learning new words seems to be an easy task for infants, but a hard
problem for developmental researchers to figure out how infants
accomplish the task. Moments when parents use object names to
refer to things in the world are often deemed ambiguous and infor-
mationaboutword-referentmappingsseemsfleeting(Trueswelletal.,
2016). This narrative begins to shift, however, when we consider
the experience of the infant learner. Noisy background information,
variability, and referential ambiguity all support learning, rather than
hinder it (Bunce & Scott, 2017; Cheung et al., 2021; Twomey et al.,
2018). Social cues also help reduce referential ambiguity. When talk-
ing about objects in ambiguous contexts, parents use gestural cues
(Cheung et al., 2021) and both infant and adult learners can utilize
social cues to resolve uncertainty (Baldwin, 1993; MacDonald et al.,
2017).Theinfant’suniqueviewoftheworldfurtherreducesreferential
ambiguity.
1.1 Infants’ view of the world supports learning
Recent studies using head-mounted cameras and eye trackers found
thattheinfant’sfield-of-viewhasuniqueproperties,differingdramat-
ically from the parent’s view at the same moment of toy play: infant’s
shorter arms result in held objects taking up a large proportion of
the infant’s field-of-view; those held objects occlude other parts of
the infant’s visual environment; and manual actions also create more
diverseviewsofobjectsintheinfant’sfield-of-viewthantheirparent’s
(e.g.,Bambachetal.,2018;Yu&Smith,2012).Theinfant’suniqueview
of the world provides the information that is available for learning.
Developmental Science. 2022;e13290. ©2022JohnWiley&SonsLtd. 1of8wileyonlinelibrary.com/journal/desc
https://doi.org/10.1111/desc.13290
14677687, 0, Downloaded from https://onlinelibrary.wiley.com/doi/10.1111/desc.13290 by University Of Texas Libraries, Wiley Online Library on [09/01/2023]. See the Terms and Conditions (https://onlinelibrary.wiley.com/terms-and-conditions) on Wiley Online Library for rules of use; OA articles are governed by the applicable Creative Commons License

2of8 SCHROERAND YU
OnestudyusingtheHumanSimulationParadigm(asinTrueswelletal.,
2016) found that ambiguity is reduced and word learning improves
when trained from the infant’s point-of-view as opposed to a third-
person camera view (Yurovsky et al., 2013). Computer vision models
similarly learn better from the infant’s view than their parent’s (e.g.,
Bambach et al., 2018). The uncertainty at the crux of the word learn-
ing “problem” is diminished with social cues, properties of infant’s
field-of-view,andtheinfant’sownhands.
1.2 Infants’ manual activity creates learning
moments
Infant manual activity modulates their learning input, as parents are
more likely to label an object when their infants are manipulating it
and creating an object-dominant view (Chang & Deák, 2019; Chang
et al., 2016; Suanda et al., 2019; West & Iverson, 2017). When par-
ents talk about objects with this infant-generated visual dominance,
infantsare more likelyto learn that object-label mapping(Yu & Smith,
2012). Infant’s “real-time” manual activity has a cascading impact on
their language development. Fifteen-month-old infants who created
more diverse object views had greater vocabulary growth over the
next 6 months – but the variability of object views infants saw when
their parents were holding the object did not predict language out-
comes(Sloneetal.,2019).Despiteevidencesuggestingtheimportance
of hands in shaping informative moments for word learning, no work
hasdirectlyrelatedinfants’visualattentionandmanualactionstotheir
real-timelearningofobject-labelmappings.
1.3 Measuring embodied influences on learning
To examine the causal effects of infant visual attention and manual
actiononwordlearning,thepresentstudylinkedinfantbehaviorsdur-
ing free play to learning outcomes in a test after the play session.
Participants played with 10 unfamiliar objects in a home-like labora-
tory while wearing wireless eye trackers. Using wireless eye trackers
grantedfullmobilitytothedyadwhilestillcapturingtheirvisualatten-
tion in a naturalistically cluttered environment. Infants’ knowledge of
the object-label mappings was then tested after the play session. This
design allowed us to study the types of social and multimodal behav-
iors that support word learning. One hypothesis is that looking a t an
object while hearing its name is sufficient for word learning. More
embodied hypotheses, however, would predict that holding may also
be critical for learning. To test those hypotheses, we measured infant
behavior when parents labeled objects and examined whether visual
attention, manual action, or the c ombination of the two was the most
predictive of learning. We analyzed infant behavior not just during a
labeling utterance, but also before and after the utterance. Analyzing
infantbehaviorbeforeandafterlabelingcouldrevealwhetherparents
followed or directed the infant’s attention to the labeled object for
successful learning, and whether labeling promoted infant’s sustained
attentiontothetargetobject,creatingmoreinformationforlearning.
RESEARCH HIGHLIGHTS
∙
Wireless head-mounted eye tracking was used to record
gaze data from infants and parents during free-flowing
play with unfamiliar objects in a home-like lab environ-
ment.
∙
Neither frequency of object labeling nor infant visual
attentionduringandaroundlabelingutterancespredicted
whetherinfantslearnedtheobject-labelmappings.
∙
Infants’ multimodal attention to objects around label-
ing utterances was the strongest predictor of real-time
learning.
∙
Taking the infant’s perspective to study word learning
allowed us to find new evidence that suggests a causal
pathwaythrough which infants’ bodies shape their learn-
inginput.
2 METHODS
2.1
Participants
Twelve- to-26-month-old infants and parents were recruited from
Bloomington, IN, a primarily white, non-Hispanic community of
working- and middle-class families in the Midwest of the United
States between November 2018 and November 2019. Families were
enrolledina subject database through word-of-mouthandatcommu-
nityevents,suchasthefarmers’market.Englishdidnotneedtobethe
participants’primarylanguageandallinfantparticipantsweretypically
developing.Seventy-sixpercentof recruitedinfantstoleratedwearing
theeyetracker. 62% of these infants contributed usable data (N = 29;
averageage= 17.2;12F).Theremaininginfantshadeye-trackingdata
thatdidnotmeetqualitystandards(badeyeimage,N = 8;unstableeye
image,N = 9)ordidnotcompletethescreen-basedtest(N = 1).Subject
informationforthe29infantsisprovidedinTableS1.
Participants were brought into a laboratory decorated to approx-
imate a studio apartment. The HOME Lab (Home-like Observa-
tional Multisensory Environment) had three distinct areas in an open
floorplan–acolorfulplayarea,alivingroom,and akitchenette. Third-
personviewcamerasandmicrophonesweremountedonthewallsand
ceilingthroughoutthespace.Forthecurrentexperiment,onlytheplay
area (Figure 1a) and an adjoining test room were used. The Univer-
sity Institutional Review Board approved all procedures and parents
providedinformedconsenttoparticipate.
2.2 Procedure
We asked parents and infants to play with 10 unfamiliar objects for
10 min or until the infant grew fussy (average amount of usable data
per participant = 7.12 min [range = 2.22–11.26 min]). We selected
14677687, 0, Downloaded from https://onlinelibrary.wiley.com/doi/10.1111/desc.13290 by University Of Texas Libraries, Wiley Online Library on [09/01/2023]. See the Terms and Conditions (https://onlinelibrary.wiley.com/terms-and-conditions) on Wiley Online Library for rules of use; OA articles are governed by the applicable Creative Commons License
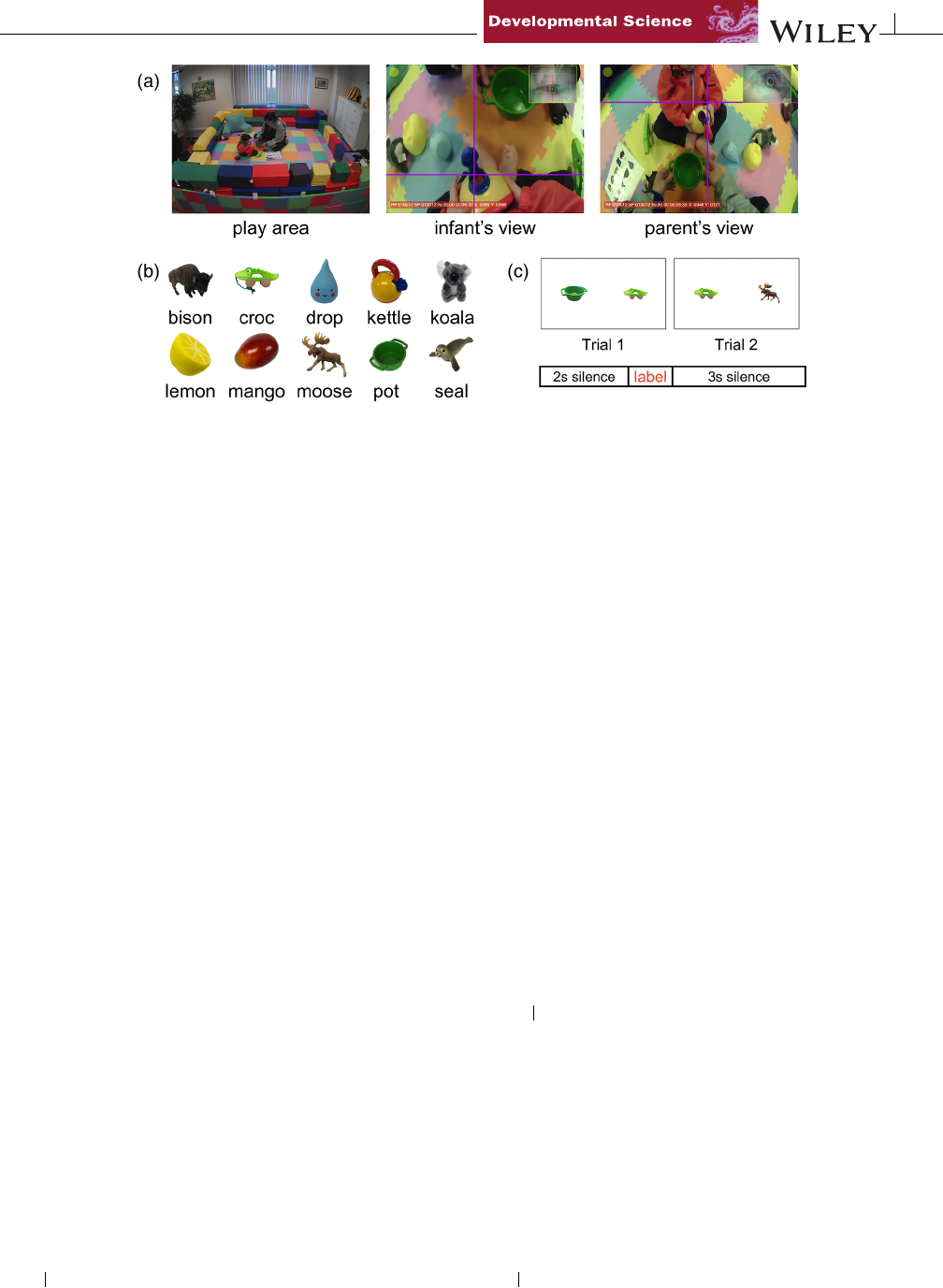
SCHROERAND YU 3of8
FIGURE 1 (a)Imagesfromthreecamerasshowingthedifferencesina3 rd-personrecording(left),theinfant’sview(middle),andtheparent’s
view(right)atthesamemoment.Thepurplecrosshairindicatesthelocationoftheparticipant’sgaze.(b)Thetenobjectsandlabels.(c)Thetwo
trialsusedtotest“croc”inthescreen-basedtask.Trialslasted7s:2sofsilence,thenthe1-slabelingutterance,followedby3-ssilence.
everyday objects that infants were unlikely to know the names of as
theyarenotincludedontheMacArthur–BatesCommunicativeDevel-
opment Inventory (MCDI, Fenson et al., 1993;Figure1b). There were
no significant differences in the total amount of time infants spent
looking at or holding the 10 toys during the experiment (tested with
one-wayANOVAs,ps > 0.11).Parentswereaskedtoplayastheywould
at home. To avoid biasing parent behavior during the study, parents
werenot told in advancethatthe playsessionwas followed bya word
learningtest.
While they were playing, dyads wore wireless head-mounted eye
trackers (Pupil Labs). Parents wore the “out-of-the-box” eye tracker
and infants wore a modified version affixed to a hat. Each eye tracker
was attached to an Android smart phone through a USB-C cord. Par-
ticipantsworecustomjacketswithasmallpocketon theback thatthe
phones were placed into during the experiment. This wire-free set-up
allowedparticipantstomovefreelythroughoutthestudy.
After the experiment, the eye-tracking videos were calibrated
(Yarbus software, Positive Science) to produce a crosshair, indicating
the location of the participant’s in-the-moment gaze in the egocentric
view (Figure 1a). To measure visual attention, gaze data were anno-
tatedframe-by-frame(30 framesper second) toidentifymomentsthe
participant was looking at a toy or their socialpartner’s face. The par-
ticipants’ handling of objects was also coded frame-by-frame with an
in-houseannotationprogram.Anytimeaparticipant’shandtouchedan
object was coded as manual attention on that object. Parent speech
wastranscribedattheutterancelevelusingAudacity,followingYuand
Smith(2012),fromwhichweidentifiedwhenparentsnamedanobject
andanalyzedinfantvisualandmanualattentiontothenamedobjectat
thosemoments.
2.3 Word learning test
After the play session, infants were tested using a computer monitor
and screen-based eye tracker (SMI REDn Scientific Eye Tracker).Dur-
ing each test trial, a target and a distractor would appear on a white
screen (Figure 1c). After 2 s of silence, the infants heard the assigned
labelof the target embeddedinthe phrase“where’s the X?” Thelabel-
ing utterance lasted approximately 1 s and was followed by 3 s of
silence before the trial ended. Infants’ knowledge of each object was
testedtwice,usingtwodifferentdistractors.
Atrialwasscorediftheparticipantattendedtothescreenformore
than one third of the window after the naming event.Similar to other
studiesusingthelooking-while-listeningparadigm(e.g.,Schwab&Lew-
Williams,2016),trialswerescoredbydividingthedurationofattention
to the target object by the total time looking at the two objects dur-
ing the 3-s window. A trial was considered “correct” if the participant
spent a greater proportion of the time looking at the target or “incor-
rect”iftheinfantlookedmoreatthedistractorduringthe3-swindow
1
.
Anobject-labelmappingwasconsidered“learned”iftheinfantgotboth
testtrialscorrectand“notlearned”iftheinfantgotbothtrialsincorrect
forthatobject.Objectswithonecorrectandoneincorrecttrial,aswell
asoneormoreunusabletrials,wereexcludedfromtheanalyses.
2.4 Statistical analysis
Mixed-effectslogistic regressions were used to assess whether atten-
tiontothelabeledobjectduringeachtemporalwindow(before,during,
after) could predict whether an object’s label was learned or not
learnedattest(lmerTestpackagefor R;Kuznetsovaetal.,2017).Sub-
jects and objects were included in the models as random effects. All
models were compared to the null model (randomeffect only) using a
chi-squaretest.
3 RESULTS
Infant participants showed some word learning after the play ses-
sion. Based on the test, infants, on average, showed learning of 2.3
14677687, 0, Downloaded from https://onlinelibrary.wiley.com/doi/10.1111/desc.13290 by University Of Texas Libraries, Wiley Online Library on [09/01/2023]. See the Terms and Conditions (https://onlinelibrary.wiley.com/terms-and-conditions) on Wiley Online Library for rules of use; OA articles are governed by the applicable Creative Commons License
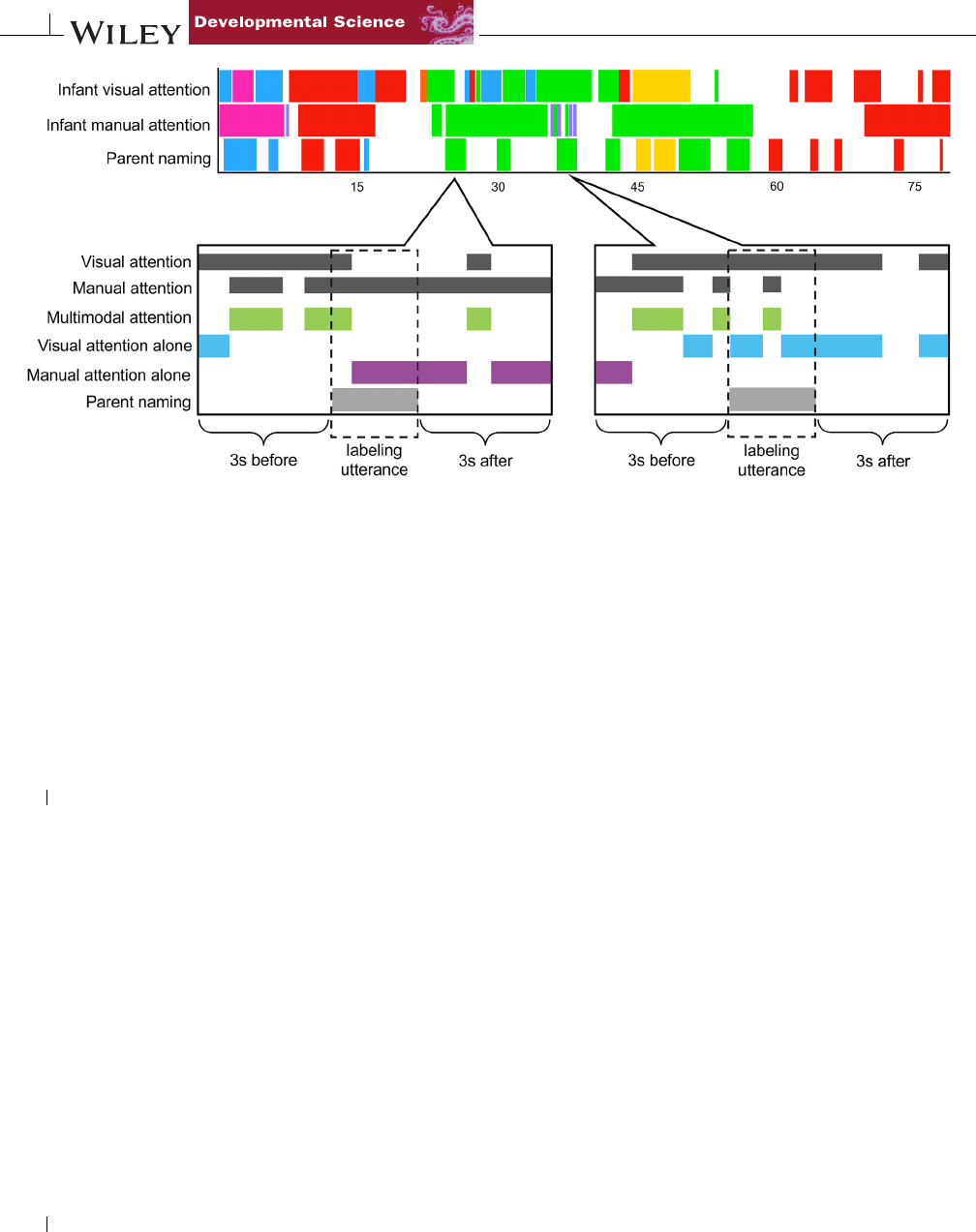
4of8 SCHROERAND YU
FIGURE 2 Thetopvisualizationstreamrepresents80sofdatafromonesubject,showinginfantbehaviorandparentnamingutterances.Each
rectanglerepresentstheonsetandoffsetofabehavior,andthecolorindicatestheobjectbeingattendedtoortalkedabout.Weidentified
utteranceswhenparentsnamedanobjecttheinfantdidordidnotlearnthenameof.Thetwobottompanelsshowtheinfant’sattentiontoatarget
object(darkgray)duringthelabelingutterance,aswellin3-swindowsbeforeandaftertheutterance.Wethenidentifiedthemomentswhenthe
infantwasinmultimodalattention(green),visualattentionalone(blue),ormanualattentionalonetotargetobject(purple).
(out of 10) words and no learning of 1.9 words. Across all the infants,
66objectinstanceswerecategorizedaslearnedand56asnotlearned.
The number of objects infants learned and did not learn was not
correlatedwiththeirage(ps > 0.094).
3.1 Does frequency of parent labeling predict
learning?
We first compared how frequently learned and not learned objects
were labeled by parents. Across all objects and subjects, there were
256 labeling events of learned objects and 248 labeling events of not
learned objects. On average, a learned object was labeled 3.88 times
(range: 0–16) and a not learned object was labeled 4.43 times (range:
0–19). There was no significant difference in how manytimes learned
and not learned objects were labeled (p = 0.479). Mean length of all
naming utterances was 1.25 s. Thus, within the context of this experi-
ment,howmanytimestheinfantheardanobject’slabelwasnotrelated
towhetherthemappingwaslearned.Instead,wheninfantshearobject
labelsmaybemoreimportantforlearning.Toaddressthisquestion,we
analyzedinfantattentionduringandaroundthelabelingevents.
3.2 Does multimodal attention predict learning?
In everyday activities such as toy play, eyes and hands often go
together.Toexaminethepotentialimpactsofmultimodalbehaviorson
word learning, we identified three attention types: multimodal atten-
tion (looking and holding at the same time), visual attention alone
(lookingwithoutholding),andmanualattentionalone(holdingwithout
looking).If justvisualattention issufficientfor wordlearning,then we
wouldexpectthatboth multimodalattentionandvisualattentionalone
would be significant predictors of learning. Similarly, if just manual
attention was sufficient for learning, then both multimodal attention
andmanualattentionalonewouldpredictlearning.Wecalculated the
proportion of time infants spent in the three attention types, not just
during a labeling utterance, but also within 3 s before and after the
utterance. The rationale behind studying the temporal windows sep-
arately is to go beyond synchronized behaviors at labeling moments
(i.e., infant is attending to the object at the exact moment they hear a
label)andexaminewhetherand,ifso,howeachtemporalwindowmay
independentlycontributetoinfantwordlearning(Figure2).
Before the labeling utterance (Figure3aandTable 1),infantsspent
agreaterproportionoftimeinmultimodalattentiontolearnedobjects
(M
learned
= 0.230, M
notlearned
= 0.133, p < 0.005). Conversely, the
proportionof time invisualattention alone negativelypredicted ifthe
object was learned (M
learned
= 0.131, M
notlearned
= 0.177, p = 0.014).
The proportion of time in manual attention alone did not predict
learning (M
learned
= 0.217, M
notlearned
= 0.185, p = 0.545). During the
labeling utterance (Figure 3b), infants spent a greater proportion of
time in multimodal attention when the object’s label was learned,
though this result was only trending on significance (M
learned
= 0.253,
M
notlearned
= 0.158, p = 0.056). The proportion of time in visual
attention alone (M
learned
= 0.150, M
notlearned
= 0.167, p = 0.295)
and manual attention alone (M
learned
= 0.229, M
notlearned
= 0.200,
p = 0.378) did not predict learning. After the labeling utter-
ance (Figure 3c), multimodal attention still positively predicted
whether the object-label mapping was learned (M
learned
= 0.229,
M
notlearned
= 0.126, p < 0.005), while visual attention alone
(M
learned
= 0.175,M
notlearned
= 0.142,p = 0.269)andmanualattention
14677687, 0, Downloaded from https://onlinelibrary.wiley.com/doi/10.1111/desc.13290 by University Of Texas Libraries, Wiley Online Library on [09/01/2023]. See the Terms and Conditions (https://onlinelibrary.wiley.com/terms-and-conditions) on Wiley Online Library for rules of use; OA articles are governed by the applicable Creative Commons License
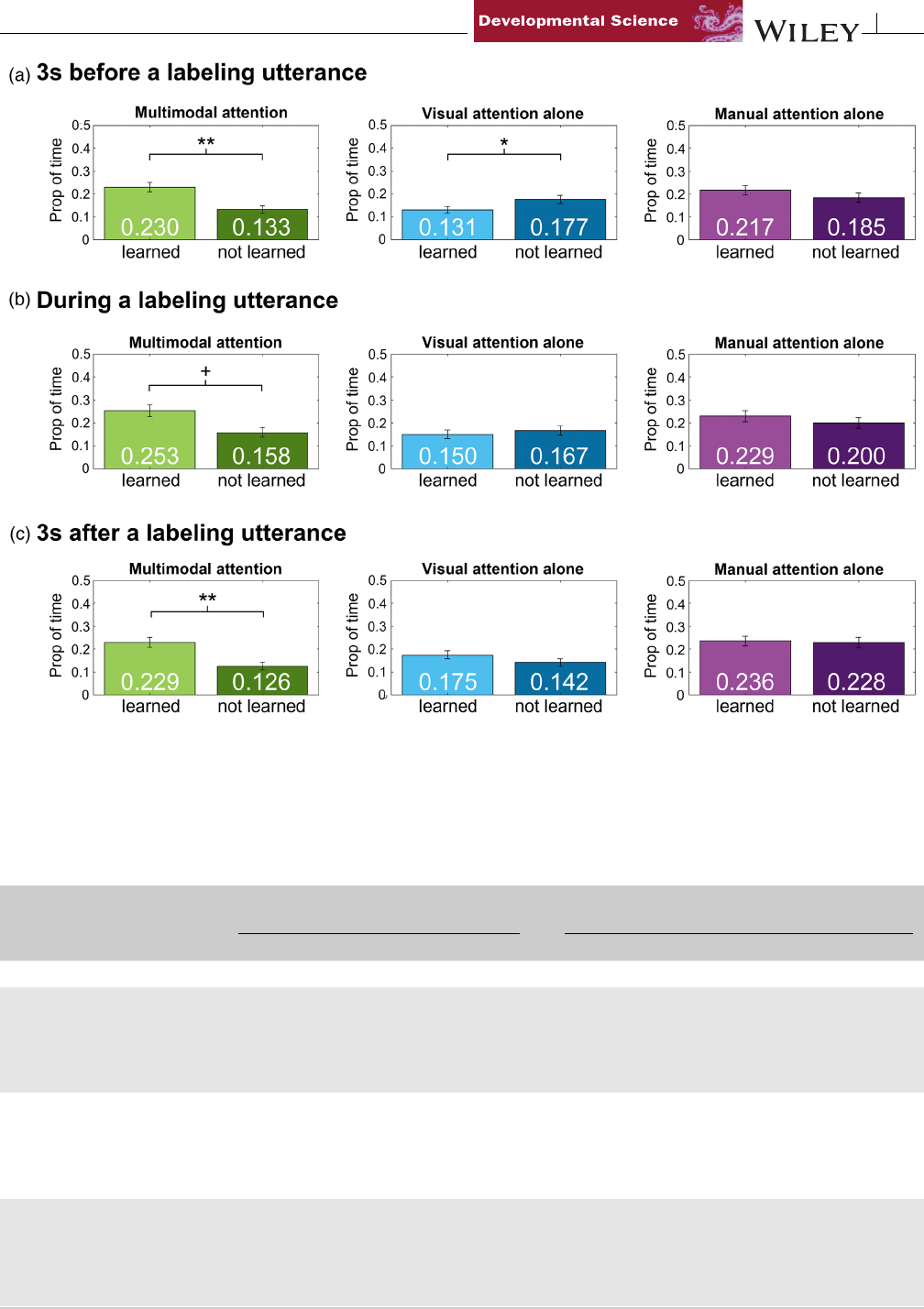
SCHROERAND YU 5of8
FIGURE 3 Theaverageproportionbefore(a),during(b),andafterthelabelingutterance(c)theinfantspentattendingtothelabeledobject
withmultimodalattention(green),visualattentionalone(blue),andmanualattentionalone(purple).Thelightershadeisattentiontolearned
objects,andthedarkershadeisattentiontonotlearnedobjects.Errorbarsshowstandarderror.Theaveragevalueisshownineachbar.+ trending,
*
p < 0.05,
**
p < 0.01
TA B L E 1 Summarystatisticsandregressionoutputs
Average proportion of time attending to
labeled object Learned? ∼ attention + (1|subject)
Learned Not Learned β p Null model comparison
Multimodalmeasuresofattention
3sbeforelabelingutterance
Multimodalattention 0.230(sd = 0.334) 0.133(sd = 0.240) 1.071 0.004 χ
2
(1)= 8.478,p = 0.004
Visualattentionalone 0.131(sd = 0.240) 0.177(sd = 0.270) −1.020 0.014 χ
2
(1)= 6.050,p = 0.014
Manualattentionalone 0.217(sd = 0.336) 0.185(sd = 0.314) 0.199 0.545 n.s.
Duringlabelingutterance
Multimodalattention 0.253(sd = 0.402) 0.158(sd = 0.335) 0.547 0.056 χ
2
(1)= 3.663,p = 0.056
Visualattentionalone 0.150(sd = 0.314) 0.167(sd = 0.301) −0.352 0.295 n.s.
Manualattentionalone 0.229(sd = 0.388) 0.200(sd = 0.368) 0.250 0.378 n.s.
3safterlabelingutterance
Multimodalattention 0.229(sd = 0.338) 0.126(sd = 0.255) 1.101 0.003 χ
2
(1)= 9.343,p = 0.002
Visualattentionalone 0.175(sd = 0.284) 0.142(sd = 0.241) 0.446 0.269 n.s.
Manualattentionalone 0.236(sd = 0.336) 0.228(sd = 0.357) 0.005 0.987 n.s.
14677687, 0, Downloaded from https://onlinelibrary.wiley.com/doi/10.1111/desc.13290 by University Of Texas Libraries, Wiley Online Library on [09/01/2023]. See the Terms and Conditions (https://onlinelibrary.wiley.com/terms-and-conditions) on Wiley Online Library for rules of use; OA articles are governed by the applicable Creative Commons License

6of8 SCHROERAND YU
alone (M
learned
= 0.236, M
notlearned
= 0.228, p = 0.987) did not predict
learning.
Ourresultsshowthatmultimodalattention,butnotvisualattention
alonenormanualattentionalone,wasthestrongestpredictorofword
learning. Further, by analyzing each temporal window separately, we
found that besides the moments during parent labeling, the moments
right before and after labeling also matter for learning. When par-
entsfollow infant multimodal attention and label the attended object,
infants may extend their multimodal attention to the labeled object
during and after labeling (see Schroer et al., 2019). By coordinating
their visual and manual attention on the same object around nam-
ing moments, infants create better opportunities to support real-time
learning.
4 DISCUSSION
It is well-accepted that visually attending to an object while hear-
ing its label is necessary for young learners to build the object-label
mapping (e.g., Yu & Smith, 2011). The embodied nature of early word
learning has also been suggested through findings such as parents
selectively naming objects that infants hold (e.g., Chang et al., 2016;
West & Iverson, 2017). However, the present study showed that nei-
thervisualattentionnormanualattentionalonewasthebestpredictor
of word learning in the context of toy play. By linking various atten-
tionmeasuresduringaplaysessionwiththeresultsfromalearningtest
immediatelyafter,thepresentedworkidentifiedacausalpathway,sug-
gestingthat theperceptual experienceofmultimodal inputcreated by
hand-eyecoordination supports the real-time learning of object-label
mappings.
4.1 Infants’ hands matter for learning
What are the mechanisms through which multimodal attention sup-
ports word learning? Multimodal attention may simply be a stronger
indicatorofinfantovertattentionthanlookingorholdingalone.Alter-
natively, infants may process information in their “hand-space” better
thaninformationoutsideofthehand-space.Researchwithadultssug-
gests that hands, but not other barriers, scaffold attention by acting
as a frame that attracts attention within the hand-space where visual
information is processed more efficiently (e.g., Davoli & Brockmole,
2012; Kelly & Brockmole, 2014). Thus, the self-generated multimodal
inputfromhand-eyecoordinationmayreducedistractioninacluttered
visual scene and lead to greater neural representation and increased
processing of the object being held (discussed in Davoli & Brockmole,
2012). If the object held by the infant is labeled at the same time, the
infantismorelikelytobuildtheobject-labelmapping.Whataboutpar-
ents’ hands? Although previous studies found that adult gestures and
synchronoushandmovementsimprovedin-the-momentwordlearning
(e.g., de Villiers Rader & Zukow-Goldring, 2012; Gogate et al., 2000),
most experimental studies that emphasized the importance of adult
manual actions were designed to not permit the child to touch the
objects they were meant to learn. The findings of Brockmole and col-
leagues may explain why infants’ own hands are more important for
supportinglearningwhendyadsengageinmorenaturalisticplay(Slone
etal.,2019).
4.2 Manual actions create the learning input
Another mechanism through which multimodal attention supports
word learning is that manual actions change the visual input dur-
ing naming moments. Young children’sown bodily actions shape their
visualexperiences(e.g.,Kretch,Franchak,&Adolph,2014;Yu&Smith,
2012) and create rich opportunities for object exploration. Training
studies using the “sticky mittens paradigm” found that providing 3-
and 4-month-old infants, who could not yet reach and grasp objects,
the opportunity to manipulate objects themselves improved perfor-
mance on mental rotation tasks and had lasting down-stream effects
on object exploration at 15-months-old (Libertus et al., 2016;Slone
et al., 2018). Further, manual activities create visual data with more
dominant and diverse views of objects that facilitate visual object
recognition by computational models (Bambach et al., 2018). In early
word learning, manual actions may help infants to identify and seg-
ment the named object from a visually cluttered scene, while gazing
at that held object at the same time provides high-resolution visual
information. Multimodal attention to named objects may thus create
a robust pathway from manual action to visual input to successful
learning.Onewaytoprovidefurtherevidenceofthispathwayistoana-
lyze the infant’s egocentric images and compare the visual properties
of the target object during multimodal attention and visual attention
alone moments. Furthermore, recent advances in machine learning
offer powerful analytics tools to analyze and model visual data col-
lectedfromtheinfant’segocentricview(e.g.,Orhanetal.,2020;Tsutsui
etal.,2020).Inastudyusingthepresenteddata(Amatunietal.,2021),
a model can distinguish frames during learned naming events from
framesduringnotlearnednamingevents.An openquestionis towhat
degree this distinction is a result of infants’ manual activities. By ana-
lyzing visual information in the infant’s view,we may discovera visual
signature of successful naming moments created by infant’s hands,
whereintheinfant’sviewoftheworldiswell-suitedtowordlearning.
4.3 Limitations
The presented work analyzed individual naming instances in parent
speech,showinghowembodiedattentionthroughbotheyesandhands
facilitateslearning object names innaturalistictoyplay. Temporalpat-
terns in parent speech, such as repeated naming, can also scaffold
learning (Schwab & Lew-Williams,2016). Futureanalyses should con-
sider the effect of discourse-level temporal distributions when dyads
played with and named objects. Moreover, a few experimental and
data analysis decisions may also limit the interpretation of our find-
ings and require follow-up studies in future work. First, to promote a
morenaturalisticinteraction,dyadsweregivenmoretoystoplaywith
14677687, 0, Downloaded from https://onlinelibrary.wiley.com/doi/10.1111/desc.13290 by University Of Texas Libraries, Wiley Online Library on [09/01/2023]. See the Terms and Conditions (https://onlinelibrary.wiley.com/terms-and-conditions) on Wiley Online Library for rules of use; OA articles are governed by the applicable Creative Commons License

SCHROERAND YU 7of8
thanpreviouswork(e.g.,Yu&Smith,2012)–whichmayhaveincreased
the learning demands on our participants. Second, although we chose
target words that are unlikely to be in early vocabulary, it is possi-
ble that infants in the study had prior exposure to the 10 words. The
effect of prior knowledge can be difficult to predict – prior exposure
maybeafactorthatcontributestothelearningoutcomesmeasuredat
test,butpreviousworkalsosuggeststhatinfantshaveworseretention
of novel object-label mappings when learning in the context of well-
knownwords(Kuckeret al.,2020).Furthermore,despitethe wide age
rangeof ourparticipants,neitherthe infant participant’s agenortheir
concurrent vocabulary size predicted their performance at the test
(correlations with MCDI scores reported in Table S2), suggesting that
prior knowledge may not have had a direct impact on word learning
in the present study. Lastly, we did not collect comprehensive demo-
graphic information from our participants, including whether infants
were learning English as their first language. Nonetheless, we anno-
tated and examined non-English words used in the play session and
found that the three infants that heard any non-English words per-
formed similarly to other subjects at test (these infants still heard the
targetobjectlabelsinEnglish;seeTableS1).Futureworkthatconsiders
whether the microlevelbehaviors examined in the present study vary
across different demographic groups would undoubtedly be a major
contributiontothefield.
5 CONCLUSION
We examined multimodal and social factors that support infant word
learning in naturalistic parent–infant play when learning is not an
exogenous goal of the interaction. Our findings suggest that only
studying infant-looking behavior and parent speech is not enough.
Considering how infants’ bodies shape their visual input will foster a
richer,mechanisticunderstandingofearlylanguageacquisition.
ACKNOWLEDGMENTS
This work was supported by NIH R01HD074601 and R01HD093792
to CY. SES was supported by the NSF GRFP (DGE-1610403) and NIH
T32HD007475. We thank the Computational Cognition and Learning
LabatIndianaUniversityandtheDevelopmentalIntelligenceLabatUT
Austin,especiallyDanielPearcy,HannahBurrell,DianZhi,Tian(Linger)
Xu, Julia Yurkovic-Harding,Drew Abney, Andrei Amatuni, and Jeremy
Borjon for their support in data collection, coding, and many fruitful
discussions.
CONFLICT OF INTEREST
Theauthorsdeclarenoconflictofinterest.
DATA AVAILABILITY STATEMENT
Thedataarenotpubliclyavailableduetoprivacyorethicalrestrictions,
butareavailableuponrequestfromthecorrespondingauthor.
ORCID
Sara E Schroer
https://orcid.org/0000-0002-6139-060X
ENDNOTE
1
To confirm our results, we also used stricter criteria to score trials as
correct/incorrect, for example, the infant must look at target for at least
250 ms longer than the distractor to be correct. This increases the num-
ber of not learned items and decreases the number of learned items.
Nonetheless,themainresultsofthepaperstillhold–showingthatinfants’
multimodalattentionisthestrongestpredictoroflearningandthatvisual
attentionaloneinthe3sbeforenamingnegativelypredictslearning.
REFERENCES
Amatuni, A., Schroer, S. E., Peters, R. E., Reza, M. A., Zhang, Y., Crandall,
D., & Yu, C. (2021). In the-moment visual information from the infant’s
egocentricview determines thesuccess ofinfant word learning:A com-
putational study. In Proceedings of the 43rd Annual Meeting of the
CognitiveScienceSociety.
Baldwin, D. A. (1993). Early referential understanding: Infants’ ability to
recognize referential acts for what they are. Developmental Psychology,
29(5),832–843.
Bambach, S., Crandall, D. J., Smith, L. B., & Yu, C. (2018). Toddler-inspired
visualobject learning. InProceedings of the Advances in NeuralInforma-
tionProcessingSystems(NeurIPS),(pp.31).
Bunce, J. P., & Scott, R. M. (2017). Finding meaning in a noisy world:
Exploring the effects of referential ambiguity and competition on 2.5-
year-olds’ cross-situational word learning. Journal of Child Language,
44(3),650–676.
Chang,L.,deBarbaro,K.,&Deák,G.(2016).Contingenciesbetweeninfants’
gaze, vocal,and manual actions and mothers’ object-naming: Longitudi-
nalchangesfrom4to9months.Developmental Neuropsychology,41(5–8),
342–361.
Chang, L. M., & Deák, G. O. (2019). Maternal discourse continuity and
infants’ actions organize 12-month-olds’ language exposure during
objectplay.Developmental Science,22(3),e12770.
Cheung, R. W., Hartley, C., & Monaghan, P. (2021). Caregivers use ges-
ture contingently to support word learning. Developmental Science, 24,
e13098.
Davoli, C. C., & Brockmole, J. R. (2012). The hands shield attention from
visual interference. Attention, Perception, & Psychophysics, 74(7), 1386–
1390.
de Villiers Rader, N., & Zukow-Goldring, P. (2012). Caregivers’ gestures
direct infant attention during early word learning: The importance of
dynamicsynchrony.Language Sciences,34(5),559–568.
Fenson,L.,Dale,P.S.,Reznick,J.S.,Thal,D.,Bates,E.,Hartung,J.P.,&Reilly,
J.S.(1993).MacArthur communicative development inventories: User’s guide
and technical manual.PaulH.Brookes.
Gogate, L. J., Bahrick, L. E., & Watson, J. D. (2000). A study of multimodal
motherese: The role of temporal synchrony between verbal labels and
gestures.Child Development,71(4),878–894.
Kelly, S. P., & Brockmole, J. R. (2014). Hand proximity differentially affects
visual working memory for color and orientation in a binding task.
Frontiers in Psychology,5,318.
Kretch, K. S., Franchak, J.M., & Adolph, K. E. (2014). Crawling and walking
infantsseetheworlddifferently.Child Development,85(4),1503–1518.
Kucker,S. C.,McMurray,B.,& Samuelson,L.K. (2020).Sometimes itis bet-
ter to know less: How known words influence referent selection and
retention in 18- to 24-month-old children. Journal of Experimental Child
Psychology,189,104705.
Kuznetsova, A., Brockhoff, P. B., & Christensen, R. H. B. (2017). lmerTest
package: Tests in linear mixed effects models. JournalofStatistical
Software,82(13),1–26.
Libertus,K.,Joh,A.S.,&Needham,A.W.(2016).Motortrainingat3months
affectsobjectexploration12monthslater.Developmental Science,19(6),
1058–1066.
MacDonald, K., Yurovsky, D., & Frank, M. C. (2017). Social cues modu-
late therepresentations underlying cross-situational learning. Cognitive
Psychology,94,67–84.
14677687, 0, Downloaded from https://onlinelibrary.wiley.com/doi/10.1111/desc.13290 by University Of Texas Libraries, Wiley Online Library on [09/01/2023]. See the Terms and Conditions (https://onlinelibrary.wiley.com/terms-and-conditions) on Wiley Online Library for rules of use; OA articles are governed by the applicable Creative Commons License

8of8 SCHROERAND YU
Orhan, A. E., Gupta, V. V., & Lake, B. M. (2020). Self-supervised learning
through the eyes of a child. Advances in Neural Information Processing
Systems,33,9960–9971.
Schroer, S., Smith, L., & Yu, C. (2019). Examining the multimodal effects of
parent speech in parent-infant interactions. In Proceedings of the 41st
AnnualMeetingoftheCognitiveScienceSociety.
Schwab, J. F., & Lew-Williams, C. (2016). Repetition across successive
sentencesfacilitates youngchildren’sword learning.Developmental Psy-
chology,52(6),879–886.
Slone, L. K., Moore, D. S., & Johnson, S. P. (2018). Object exploration
facilitates 4-month-olds’ mental rotation performance. Plos One, 13(8),
e0200468.
Slone,L.K., Smith,L.B.,&Yu,C.(2019).Self-Generatedvariabilityinobject
imagespredictsvocabularygrowth.Developmental Science,22,e12816.
Suanda, S. H., Barnhart, M., Smith, L. B., & Yu, C. (2019). The signal in the
noise:Thevisualecologyofparents’objectnaming.Infancy,24,455–476.
Trueswell, J. C., Lin, Y., Armstrong III, B., Cartmill, E. A., Goldin-Meadow,
S., & Gleitman, L. R. (2016). Perceiving referential intent: Dynamics of
referenceinnaturalparent–childinteractions.Cognition,148,117–135.
Tsutsui, S., Chandrasekaran, A., Reza, M. A., Crandall, D., & Yu, C. (2020).
A computational model of early word learning from the infant’s point
of view. In Proceedings of the 42nd Annual Meeting of the Cognitive
ScienceSociety.
Twomey, K. E., Ma, L., & Westermann, G. (2018). All the right noises:
Background variability helps early word learning. Cognitive Science, 42,
413–438.
West,K. L., & Iverson, J.M. (2017). Language learning is hands-on: Explor-
inglinksbetweeninfants’objectmanipulationandverbalinput.Cognitive
Development,43,190–200.
Yu,C.,&Smith,L.B.(2011).Whatyoulearniswhatyousee:Usingeyemove-
ments to study infant cross-situational word learning. Developmental
Science,14(2),165–180.
Yu, C., & Smith, L. B. (2012). Embodied attention and word learning by
toddlers.Cognition,125(2),244–262.
Yurovsky,D.,Smith,L.B., &Yu,C.(2013). Statisticalwordlearning atscale:
Thebaby’sviewisbetter.Developmental Science,16,959–966.
SUPPORTING INFORMATION
Additionalsupporting informationcanbefoundonline inthe Support-
ingInformationsectionattheendofthisarticle.
How to cite this article: Schroer,S.E.,&Yu,C.(2022).Looking
isnotenough:Multimodalattentionsupportsthereal-time
learningofnewwords.Developmental Science,e13290.
https://doi.org/10.1111/desc.13290
14677687, 0, Downloaded from https://onlinelibrary.wiley.com/doi/10.1111/desc.13290 by University Of Texas Libraries, Wiley Online Library on [09/01/2023]. See the Terms and Conditions (https://onlinelibrary.wiley.com/terms-and-conditions) on Wiley Online Library for rules of use; OA articles are governed by the applicable Creative Commons License
